一种基于进化算法的交互式本体匹配方法和计算机设备与流程
本发明涉及一种本体匹配方法和可执行该方法的计算机设备。
背景技术:
本体:对某个领域中的知识的概念化明确的规范说明,即对某个领域中存在的对象、概念、其他实体以及它们之间的关系的正式的和规范化描述。
本体匹配过程:确定两个异质本体中语义相同的实体对集合的过程。
本体匹配技术可以解决本体异质问题(同一个概念在不同本体有不同的名字),实现基于本体的应用程序在语义层面上的协作。
本体作为语义网的核心技术,是一种共享的、正式的信息交换参考模型,它描述了某个领域中存在的对象、概念、其他实体以及它们之间的关系[1]。本体技术在知识管理、信息检索、电子商务和生物医学等领域都具有重要应用,目前语义网上已公布的本体中含有的实体规模已经达到31亿之巨。然而,这些本体间的异质问题(同一个概念在不同本体有不同的名字)是实现语义网中不同应用间语义协作的最大障碍,也是制约语义网发展的瓶颈问题。本体匹配技术是当前解决本体异质问题最有效的方法[2]。可是截至本专利申报书完成之前(2017年2月),已有的本体匹配技术对语义网上已公布的5亿个实体匹配结果有接近45%是错误的[3,4]。因此,业内急需一种能够获取高质量本体匹配结果的技术。由于本体匹配过程的复杂性,自动化本体匹配技术获取的本体匹配结果需要通过用户验证来确保其质量。令用户和自动化本体匹配技术在合理的时间内互相协作以获取高质量的本体匹配结果的过程称为交互式本体匹配过程。本体匹配系统无法要求用户验证一个本体匹配结果中的全部实体匹配对,因此在交互式本体匹配过程中存在的主要挑战问题之一是如何最小化用户的工作量的同时最大化用户检验结果的价值。
在最小化用户工作量的工作中,shi等[5]提出通过交互式算法确定的阈值和相似度扩散图来选择最有信息量的问题匹配对让用户验证。jiménez-ruiz等[6]提出了三个原则(即一致性,局部性和保留性原则)来过滤候选实体匹配对。beisswanger等[7]提出了一些质量检查标准来度量本体匹配结果的可复用性,并使用其确定候选实体匹配集。cruz[8]等选择让不同的本体匹配器无法达成一致结果的问题实体匹配对给用户。类似地,sambo[9]通过之前用户验证过的知识来减少不必要的用户干预。gomma[10]采用的是基于组合和差异性的自适应算法来复用不受影响的实体匹配对。prompt[11]通过最新的用户干预的结果来确定候选实体匹配集。
相似度扩散算法可以依据本体概念体系结构将用户验证的结果扩散到其邻居概念中去,是最大化用户验证结果的有效方法。shi等[5]提出了一种主动学习框架,可以向用户提供最有信息量的候选匹配结果给用户验证,并将用户验证结果依据本体概念体系结构扩散以提高匹配的准确性。agreementmaker[8]使用签名向量来讲用户的反馈结果扩散到其他实体匹配对中去,通过一个线性函数来实现对相关匹配对相似度值的增加和减少。
归结目前这些现有的本体匹配方法,存在下述缺点:
(1)由于每次迭代过程都要用户介入,增加了用户不必要的工作量;
(2)需要用户逐个验证候选匹配结果,无法依据用户的验证结果自动处理剩余的候选匹配结果,增加了用户的工作量;
(3)容易扩散错误的用户验证结果,从而降低了本体匹配的质量。
[1]garridoa.logicalfoundationsofartificialintelligence[j].brain.broadresearchinartificialintelligenceandneuroscience,2010,1(2):149-152.
[2]shvaikop,euzenatj.ontologymatching:stateoftheartandfuturechallenges[j].ieeetransactionsonknowledgeanddataengineering,2013,25(1):158-176.
[3]liuw.truthdiscoverytoresolveobjectconflictsinlinkeddata[j].arxivpreprintarxiv:1509.00104,2015.
[4]liuw,liuj,duanh,etal.exploitingsource-objectnetworktoresolveobjectconflictsinlinkeddata[j].arxivpreprintarxiv:1604.08407,2016.
[5]f.shi,j.li,j.tang,g.xie,andh.li,“activelylearningontologymatchingviauserinteraction,”ininternationalsemanticwebconference.springer,2009,pp.585–600.
[6]e.jiménez-ruiz,b.c.grau,i.horrocks,andr.berlanga,“logic-basedassessmentofthecompatibilityofumlsontologysources,”journalofbiomedicalsemantics,vol.2,no.1,p.s2,2011.
[7]e.beisswangerandu.hahn,“towardsvalidandreusablereference
[8]i.f.cruz,c.stroe,andm.palmonari,“interactiveuserfeedbackinontologymatchingusingsignaturevectors,”in2012ieee28thinternationalconferenceondataengineering.ieee,2012,pp.1321–1324.
[9]p.lambrixandr.kaliyaperumal,“asession-basedapproachforaligninglargeontologies,”inextendedsemanticwebconference.springer,2013,pp.46–60.
[10]a.groβ,j.c.dosreis,m.hartung,c.pruski,ande.rahm,“semi-automaticadaptationofmappingsbetweenlifescienceontologies,”ininternationalconferenceondataintegrationinthelifesciences.springer,2013,pp.90–104.
[11]n.f.noy,m.a.musenetal.,“algorithmandtoolforautomatedontologymergingandalignment,”inproceedingsofthe17thnationalconferenceonartificialintelligence(aaai-00).availableassmitechnicalreportsmi-2000-0831,2000.
技术实现要素:
本发明要解决的技术问题,在于提供一种基于进化算法的交互式本体匹配方法,能够自适应地确定用户介入的时间点,自动确定数量有限的本体匹配候选集让用户检验,并扩散用户检验的结果以实现最大化用户检验结果的价值的目的。
本发明方法是这样实现的:一种基于进化算法的交互式本体匹配方法,包括:
本体划分阶段,将大规模的本体划分为小规模的本体分块,使得后续的本体匹配过程是在本体分块中进行;
基于进化算法的本体匹配阶段,利用进化算法实现自动化的本体匹配过程,自适应地确定用户介入的时间点;
用户检验和检验结果扩散阶段,将自动确定的候选本体匹配结果呈现给用户检验,在用户检验的过程中自动处理剩余的候选本体匹配结果,最后扩散可信的用户检验结果;
本体分块匹配结果集成与评价阶段,集成不同本体分块匹配结果,并利用本体的参考匹配结果计算最终结果的f度量。
进一步的,所述本体划分阶段的具体过程是:
(1)首先通过semanticaccuaracy度量本体结构的分散性和不平衡性来选择可靠性较强的本体作为源本体;
(2)然后利用扩展自scan算法的本体划分算法将源本体划分为源本体分块;
(3)对每个源本体分块,利用概念相关度度量来确定其相似的目标本体分块。
进一步的,所述基于进化算法的本体匹配阶段包括建模过程和匹配过程;
所述建模过程具体是:
s11、将本体o定义为o={c,p,i},其中c,p和i分别表示本体中的概念集合,属性集合和实例集合,其中概念,属性和实例统称本体的实体;本体匹配结果a是一个实体匹配对的集合,每一个实体匹配对可以表示为一个四元组{e,e',n,rel},其中e和e'分别表示元本体和目标本体的实体,n是e和e'关系的可信度值,rel是e和e'之间的等价关系;
s12、给定本体匹配结果a,其质量由f(a)来度量:
其中,|a|是a中的匹配对数量,mf(a)是计算a的matchfmeasure值,δi是a中第i个匹配对的相似度值,α∈[0,1]是用于权衡本体匹配结果的查全率和查准率主调整参数;
s13、给定源本体分块osrc和目标本体分块otgt,设计单目标本体匹配问题的优化模型如下:
其中,fi(x),i=1,2,...,m计算第i个本体匹配器结果的f()值,|osrc|和|otgt|分别表示本体osrc和otgt的实体集合的基数,xi,i=1,2,...,|osrc|表示第i个实体匹配对;
所述匹配过程具体是:
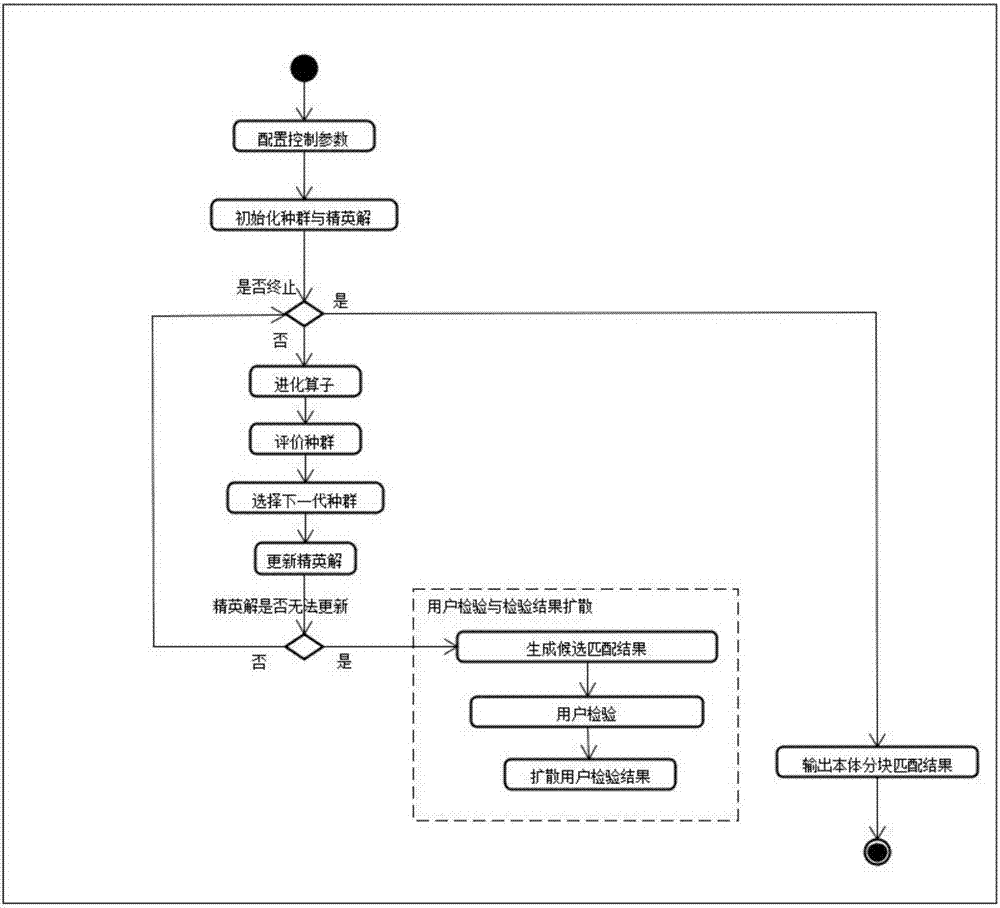
s21、配置算法控制参数,包括数值精度,种群规模,选择概率,交叉概率和变异概率;
s22、随机初始化种群,并在种群中选出适应度值最高的个体作为精英解的初始化值;
s23、进入进化过程,首先评价种群中每一个个体的适应度值f(),通过赌轮盘选择,以及通过单点交叉和单点变异标准进化算子操作之后选择生成下一代种群;
s24、重新评价种群的适应度值f()并尝试更新精英解,直到满足终止条件,并输出本体分块匹配结果,若精英解连续若干代无法更新而进化,此时让用户介入引导算法的进化方向。
进一步的,所述用户检验和检验结果扩散阶段的具体过程是:
(1)首先将精英解中实体匹配对在相似度阈值为0.4附近的“问题”匹配对让用户检验;
(2)然后对于目标本体中一个实体有多个源本体实体对应的匹配,让用户选出其中一个正确的匹配对,其余的匹配对的可信度设置为0;
(3)最后对于用户检验过的结果,将相似度值高于阈值0.9的匹配对的可信扩散到其周边概念中。
进一步的,所述α值同查全率呈正比,同查准率成反比。所述α的建议取值是0.35。
此外,本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时能够执行上述本发明方法的过程。
本发明具有如下优点:
(1)利用进化算法自适应地决定用户介入的时机,减少了不必要的用户交互;
(2)自动根据用户检验结果处理剩余候选匹配对,减少了用户的工作量,提高了用户检验过程的效率;
(3)将用户检验过的高于阈值的实体匹配对扩散到周边概念中,以减少错误的用户检验结果带来的不良影响,在最大化用户检验结果的价值的同时提高本体匹配过程的效率和最终本体匹配结果的质量。
附图说明
下面参照附图结合实施例对本发明作进一步的说明。
图1为本发明方法执行流程图。
图2为本发明方法中用户检验和检验结果扩散阶段的执行流程图。
具体实施方式
请参阅图1所示,本发明的基于进化算法的交互式本体匹配方法,包括本体划分阶段,基于进化算法的本体匹配阶段,用户检验和检验结果扩散阶段,以及本体分块匹配结果集成与评价阶段。
所述本体划分阶段,将大规模的本体划分为小规模的本体分块,使得后续的本体匹配过程是在本体分块中进行;其具体过程是:
(1)首先通过semanticaccuaracy(sánchezd,batetm,martínezs,etal.semanticvariance:anintuitivemeasureforontologyaccuracyevaluation[j].engineeringapplicationsofartificialintelligence,2015,39:89-99)度量本体结构的分散性和不平衡性来选择可靠性较强的本体作为源本体;
(2)然后利用扩展自scan算法的本体划分算法将源本体划分为源本体分块;
(3)对每个源本体分块,利用概念相关度度量来确定其相似的目标本体分块(x.xue,j.pan,asegment-basedapproachforlarge-scaleontologymatching,knowledgeandinformationsystems(2017)1–18)。
所述基于进化算法的本体匹配阶段,利用进化算法实现自动化的本体匹配过程,自适应地确定用户介入的时间点;所述基于进化算法的本体匹配阶段包括建模过程和匹配过程;
所述建模过程具体是:
s11、将本体o定义为o={c,p,i},其中c,p和i分别表示本体中的概念集合,属性集合和实例集合,其中概念,属性和实例统称本体的实体;本体匹配结果a是一个实体匹配对的集合,每一个实体匹配对可以表示为一个四元组{e,e',n,rel},其中e和e'分别表示元本体和目标本体的实体,n是e和e'关系的可信度值,rel是e和e'之间的等价关系;
s12、给定本体匹配结果a,其质量由f(a)来度量:
其中,|a|是a中的匹配对数量,mf(a)是计算a的matchfmeasure值,δi是a中第i个匹配对的相似度值,α∈[0,1]是用于权衡本体匹配结果的查全率和查准率主调整参数;所述α值同查全率呈正比,同查准率成反比;所述α的建议取值是0.35;
s13、给定源本体分块osrc和目标本体分块otgt,设计单目标本体匹配问题的优化模型如下:
其中fi(x),i=1,2,...,m计算第i个本体匹配器结果的f()值,|osrc|和|otgt|分别表示本体osrc和otgt的实体集合的基数,xi,i=1,2,...,|osrc|表示第i个实体匹配对;
所述匹配过程具体是:
s21、配置算法控制参数,包括数值精度,种群规模,选择概率,交叉概率和变异概率;
s22、随机初始化种群,并在种群中选出适应度值最高的个体作为精英解的初始化值;
s23、进入进化过程,首先评价种群中每一个个体的适应度值f(),通过赌轮盘选择,以及通过单点交叉和单点变异标准进化算子操作之后选择生成下一代种群;
s24、重新评价种群的适应度值f()并尝试更新精英解,直到满足终止条件,并输出本体分块匹配结果,若精英解连续若干代无法更新而进化,此时让用户介入引导算法的进化方向。
所述用户检验和检验结果扩散阶段,将自动确定的候选本体匹配结果呈现给用户检验,在用户检验的过程中自动处理剩余的候选本体匹配结果,最后扩散可信的用户检验结果;其具体过程是:
(1)首先将精英解中实体匹配对在相似度阈值为0.4附近的“问题”匹配对让用户检验;
(2)然后对于目标本体中一个实体有多个源本体实体对应的匹配,让用户选出其中一个正确的匹配对,其余的匹配对的可信度设置为0;
(3)最后对于用户检验过的结果,将相似度值高于阈值0.9的匹配对的可信扩散到其周边概念中;
例如,对于用户检验过的匹配对{e,e',0.92,=},分别找出e和e'在各自本体概念体系结构中的所有父概念集合supe和supe',若是
所述本体分块匹配结果集成与评价阶段,通过贪心算法集成不同本体分块匹配结果,并利用本体的参考匹配结果计算最终结果的f度量。
需要说明的是:本发明的本体划分算法也可以通过其他的本体划分算法来代替;本发明采用的近似本体匹配结果的度量技术也可以采用其他的近似本体匹配结果度量技术代替;本发明采用的进化算法也可以使用其他群智能算法代替。此外,本发明还提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时能够执行上述本发明方法的过程。
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!