一种基于内容标签的知识库推荐系统的制作方法
本发明设计一种知识库知识推荐系统,具体的说是一种基于内容标签的知识库推荐系统。
背景技术:
目前很少有在知识库中引入知识推荐,一般知识简单的集成传统的搜索引擎提供给用户进行知识内容的搜索。用户很难有效在海量的知识库中直接获取或随时获取自己想要的知识内容,即使是通过各种条件检索的方式也很难在极短的时间内获取到目标内容。
目前大部分内容系统只能做到“找到相关信息”,而“找到我想要的信息”极少系统能做到,用户真正需要的东西淹没在海量数据中,如何从海量信息及时获得最新信息,是一个非常值得研究的课题。
技术实现要素:
本发明提出一种基于内容标签的推荐系统,并应用于知识库领域,让用户被动的获取到自己感兴趣的知识内容,其包括:
知识源:包括电子知识资源、纸件知识资源,电子知识资源包括电子文本、电子图片、视频、或语音;
知识采集模块:负责从知识源上采集知识内容,或人工录入,知识采集模块采集到知识内容后,将知识内容保存到内容资源数据库中,为保持推荐的知识内容为总为新的,知识采集模块还包括活跃内容管理模块,活跃内容管理模块负责管理容资源数据库中活跃的内容,若某一知识内容发布时间超过一定的实效则视为过期,并标记为已归档,而不会出现在以后的知识推荐列表中;
知识推荐模块:负责响应用户请求,生成知识推荐列表,并将列表返回给用户,在知识推荐模块中的算法为基于内容标签的推荐算法,知识推荐模块还包括将最新的知识内容整合到推荐列表中的功能模块,因为最新的知识是依据时间排序的,而内容具有随机性。
资源调度模块:负责监控知识库推荐系统当前负载情况,按照算法调整知识数据保持的时间实效,从而保证知识的实时性,并控制知识的数量;还调用推荐算法进行计算和关于相似度的计算,计算的内容包括用户在浏览知识的过程中其使用习惯数据,该使用习惯数据包括使用时间、阅读的知识分类、每天知识阅读时间和次数等信息,这些信息都被记录到用户数据库,然后,由用户建模模块进行数据分析,并最终生成用户模型保存在用户模型数据库中。
所述资源模块定时运行,不断更新用户模型,使得用户的兴趣转移能够实时反映到用户模型中。
所述资源模块还包括监视系统资源模块,所述监视系统资源模块根据负载情况实时调整计算资源的分配,从而保持知识库推荐系统稳定的响应时间。
所述知识分类包括对用户的不同主题的兴趣特征进行分类,计算使用用户关注某篇内容的时间长度,并以此作为用户对此内容的一个关注度指标。
附图说明
图1为本发明基于内容标签的知识库推荐系统示意图;
图2为本发明基于内容标签的知识库推荐系统知识推荐原理示意图。
具体实施方式
实施例1,如图1所示,一种基于内容标签的推荐系统,并应用于知识库领域,让用户被动的获取到自己感兴趣的知识内容,其包括:
知识源:包括电子知识资源、纸件知识资源,电子知识资源包括电子文本、电子图片、视频、或语音;
知识采集模块:负责从知识源上采集知识内容,或人工录入,知识采集模块采集到知识内容后,将知识内容保存到内容资源数据库中,为保持推荐的知识内容为总为新的,知识采集模块还包括活跃内容管理模块,活跃内容管理模块负责管理容资源数据库中活跃的内容,若某一知识内容发布时间超过一定的实效则视为过期,并标记为已归档,而不会出现在以后的知识推荐列表中;
知识推荐模块:负责响应用户请求,生成知识推荐列表,并将列表返回给用户,在知识推荐模块中的算法为基于内容标签的推荐算法,知识推荐模块还包括将最新的知识内容整合到推荐列表中的功能模块,因为最新的知识是依据时间排序的,而内容具有随机性。
资源调度模块:负责监控知识库推荐系统当前负载情况,按照算法调整知识数据保持的时间实效,从而保证知识的实时性,并控制知识的数量;还调用推荐算法进行计算和关于相似度的计算,计算的内容包括用户在浏览知识的过程中其使用习惯数据,该使用习惯数据包括使用时间、阅读的知识分类、每天知识阅读时间和次数等信息,这些信息都被记录到用户数据库,然后,由用户建模模块进行数据分析,并最终生成用户模型保存在用户模型数据库中。
所述资源模块定时运行,不断更新用户模型,使得用户的兴趣转移能够实时反映到用户模型中。
所述资源模块还包括监视系统资源模块,所述监视系统资源模块根据负载情况实时调整计算资源的分配,从而保持知识库推荐系统稳定的响应时间。
所述知识分类包括对用户的不同主题的兴趣特征进行分类,计算使用用户关注某篇内容的时间长度,并以此作为用户对此内容的一个关注度指标。
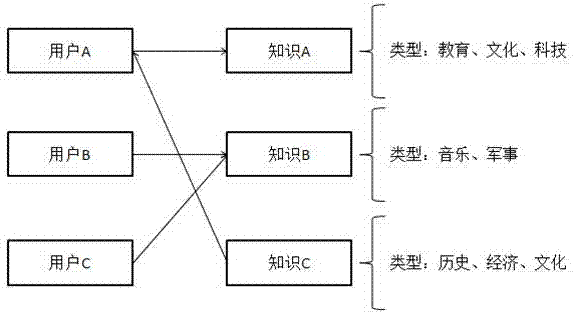
下面结合具体的案例来进一步阐述本发明基于内容标签的知识库推荐系统知识推荐原理。如图2所示,
首先,要对知识点元数据有一个建模,如将知识分为不同的类型,以图2中所示知识类型为例包括知识a、知识b、知识c,
知识a包括:教育、文化、科技;
知识b包括:音乐、军事;
知识c包括:历史、经济、文化;
首先,要对知识点元数据有一个建模,如将知识分为不同的类型,以图2中所示知识类型为例包括知识a、知识b、知识c,
知识a包括:教育、文化、科技;
知识b包括:音乐、军事;
知识c包括:历史、经济、文化;
然后,由资源调度模块对用户行为进行分析,调用推荐算法进行计算和关于相似度的计算,计算的内容包括用户在浏览知识的过程中其使用习惯数据,该使用习惯数据包括使用时间、阅读的知识分类、每天知识阅读时间和次数等信息,资源调度模块将这些信息都被记录到用户数据库,如资源调度模块计算出,
用户a在浏览知识的过程中,其使用习惯有访知识a的习惯,阅读的知识分类为教育、文化和科技类;
用户b在浏览知识的过程中,其使用习惯有访知识b的习惯,阅读的知识分类为音乐、军事类;
用户c在浏览知识的过程中,其使用习惯有访知识c的习惯,阅读的知识分类为历史、经济、文化;
资源调度模块将上述计算结果记录到用户数据库中。
接着,用户建模模块进行数据分析,通过知识的元数据发现知识间的相似度,因为类型都是“文化”知识a和知识c被认为是相似的知识,进而得出用户a的模型,即知识a+知识c,进一步的,用户a的模型包括“教育、文化、科技”+“历史、经济”,资源调度模块将用户a的模型保存在用户模型数据库中。
最后,知识推荐模块调用用户a的用户模型,将知识a+知识c,即“教育、文化、科技”+“历史、经济”知识推送给用户a。
一个个性化的内容推荐系统,最好的效果是实现根据用户喜好和需求推荐内容。只是推荐大都基于海量数据的计算和处理,然而在海量数据上高效的运行一些高复杂的算法需要消耗的资源也是惊人的,所以对于智能推荐,基于内容标签的推荐方法来说比较合适,它对各种设备已经运行环境的要求不高,并且对于技术人员也易于掌握。在使用该方法的系统中,被推荐对象使用其内容的特征进行表示,推荐系统通过学习用户的兴趣,将用户模型与被推荐对象进行相似度比较来实现特征提取,而文本类的内容,其特征相对来说较易提取,所以,在文本要描述的知识内容系统中,采用基于内容标签的推荐方法,效果非常显著。
- 还没有人留言评论。精彩留言会获得点赞!