一种可靠的分布式日志收集方法和系统与流程
本申请涉及互联网大数据收集技术,具体地,涉及可靠的分布式日志收集方法和系统,使得日志在传输过程中的检查不再依赖于人工经验,而是可通过机器的自动化检测实现日志的切割、传输和检验,减少了人工检验的过程。
背景技术:
随着大数据技术的发展,越来越多的互联网企业介入大数据分析领域,从而得到更智能更精准的分析结果。工程师会同时收集pc端、无线端、h5端等上的不同服务的用户行为日志,经过传输、转换、存储后形成tb甚至pb级别的数据仓库。数据仓库是所有数据分析和挖掘的基础,其数据准确性显得尤为重要。因此,这对入库过程提出了更高的要求,企业要尽量减少进程失败、网络抖动等不稳定因素带来的日志数据丢失问题。
针对日志的收集技术,现有的技术方案绝大部分是在各个服务器端机器部署日志采集模块,然后通过日志传输组件(类似flume,scribe)将日志传输到收集端机器。由收集端机器的进程完成数据的etl过程,然后在入库后,开发各种分析、挖掘的程序得到决策方案。
然而,这样的技术方案面临着数据丢失的问题。一方面,通过网络传输的数据难免因为网络抖动造成数据的丢失,这样的丢失在现有技术方案中是很难被发现的,而在分析精度要求比较高的场景下,会对分析结果造成不利的影响。现有技术中,数据的丢失往往需要靠人在观察分析结果时发现,这样大大分散了分析师的精力,增加了人工成本。
另一方面,向收集端机器传输日志的日志打印机器的进程和从日志打印机器收集日志的收集端机器的进程随时可能挂掉,如果有一个进程挂掉就可能导致大范围的数据丢失,如果此时开始执行数据分析,则会得到错误的结论。
技术实现要素:
针对现有技术中存在的一个或多个问题,本申请提出了一种可靠的分布式日志收集方法及系统。
本申请提供的分布式日志收集方法包括:将应传输的日志切分为多个日志块;将应传输的日志块与flume监控目录建立软链接;传输与flume监控目录建立了软链接的日志块;将已传输的日志块存入hdfs集群;将应传输的日志块在传输前的行数与从hdfs读取的相应已传输日志块的行数进行比较,以确定相应已传输的日志块是否为正常日志块;以及将所确定出的正常日志块存入数据仓库。
将应传输的日志块在传输前的行数与从hdfs读取的相应已传输日志块的行数进行比较之前,该方法还可包括:根据应传输的日志块与日志打印机器之间的对应关系,核对应进行日志传输的日志打印机器和当前参与日志传输的日志打印机器是否一致,如果一致,则执行比较的步骤;如果不一致,则自动拉起相应日志打印机器上的flume进程,然后执行比较的步骤。
该方法还可进一步包括:判断拉起的过程是否成功的步骤,如果不成功,向用户发出第一警报。
上述比较的步骤可包括:判断出应传输的日志块在传输前的行数与从hdfs集群读取的相应已传输日志块的行数之间的误差超出了预设的误差范围,以及将判断后的已传输的日志块确定为异常日志块,并返回至建立软链接的步骤。
上述比较的步骤还可包括:判断出应传输的日志块在传输前的行数与从hdfs集群读取的相应已传输日志块的行数之间的误差未超出预设的误差范围;以及将判断后的已传输的日志块确定为正常日志块。
该方法还可包括:在已传输的日志块被确定为异常日志块之后且在返回至建立软链接的步骤之前,根据对应于异常日志块的应传输的日志块已与相应flume监控目录建立软链接的次数分析是否向用户发出第二警报,如果次数超出预设值,则向用户发出第二警报,否则返回至建立软链接的步骤。
应传输的日志块与日志打印机器之间的对应关系可通过在切分的日志块的名称中添加执行切分的日志打印机器的名称而建立。
将日志切分为多个日志块的步骤可根据第一预设时间而执行。
切分的日志块的名称可与第一预设时间关联。
该方法还可包括:每隔第二预设时间执行检测flume收集端机器是否存在flume进程的步骤,响应于flume收集端机器上不存在flume进程,拉起相应flume收集端机器的flume进程。
本申请提供的分布式日志收集系统包括:多个日志打印机器,配置成将应传输的日志切分为多个日志块并将应传输的日志块与日志打印机器中配置的flume监控目录建立软链接;flume收集端机器,配置成接收与日志打印机器中配置的flume监控目录建立了软链接的日志块;hdfs集群,配置成存储flume收集端机器所接收的日志块;处理模块,配置成将日志打印机器应传输的日志块在传输前的行数与从hdfs集群读取的相应日志打印机器已传输日志块的行数进行比较,以确定相应日志打印机器已传输的日志块是否为正常日志块;数据仓库,配置成存储处理模块所确定出的正常日志块。
处理模块还可配置成:在将日志打印机器应传输的日志块在传输前的行数与从hdfs集群读取的相应日志打印机器已传输日志块的行数进行比较之前,根据建立的应传输的日志块与日志打印机器之间的对应关系核对应进行日志传输的日志打印机器和当前参与日志传输的日志打印机器是否一致,响应于二者一致,处理模块进行比较的步骤;响应于二者不一致,处理模块自动拉起相应日志打印机器上的flume进程,然后执行比较的步骤。
处理模块可进一步配置成:判断拉起的过程是否成功,如果不成功,向用户发出第一警报。
处理模块进行的比较的步骤可包括:判断出日志打印机器应传输的日志块在传输前的行数与从hdfs集群读取的相应已传输日志块的行数之间的误差超出了预设的误差范围,以及将判断后的已传输的日志块确定为异常日志块,并通知与异常日志块对应的日志打印机器将对应于异常日志块的应传输的日志块与日志打印机器上的flume监控目录重新建立软链接。
日志打印机器应传输的日志块在传输前的行数可由相应日志打印机器记录在文件传输表中。
处理模块可通过map-reduce版etl实现。
应进行日志传输的日志打印机器可记录在采集机器表中。
处理模块进行的比较的步骤可包括:判断出日志打印机器应传输的日志块在传输前的行数与从hdfs集群读取的相应日志块在传输已传输日志块的行数之间的误差未超出预设的误差范围,以及将判断后的已传输的日志块确定为正常日志块。
处理模块还可配置成:在将从hdfs集群读取的已传输日志块被确定为异常日志块之后且在通知与异常日志块对应的日志打印机器将对应于异常日志块的应传输的日志块与日志打印机器中配置的flume监控目录重新建立软链接之前,根据对应于异常日志块的应传输的日志块已与相应日志打印机器中配置的flume监控目录建立软链接的次数分析是否向用户发出第二警报,如果次数超出预设值,则向用户发出第二警报,否则通知与异常日志块对应的日志打印机器将对应于异常日志块的应传输的日志块与日志打印机器上的flume监控目录重新建立软链接。
日志打印机器还可配置成:在接收到从处理模块发出的重新建立软链接的通知后,执行重新建立软链接的步骤。
多个日志打印机器中的每一个可通过在所切分的日志块的名称中添加自身的机器名而建立起应传输的日志块与日志打印机器之间的对应关系。
多个日志打印机器切分日志的过程可根据第一预设时间执行。
多个日志打印机器中的每一个切分的日志块的名称可与第一预设时间关联。
flume收集端机器还可配置成每隔第二预设时间检测自身是否在存在flume进程,响应于不存在flume进程,拉起自身的flume进程。
附图说明
通过阅读参照以下附图对非限制性实施方式所作的详细描述,本申请的其它特征、目的和优点将变得更加明显,附图中:
图1示出了根据本申请实施方式的分布式日志收集系统。
图2示意性地示出了分布式日志收集系统中的日志打印机器将其所切分的日志块与其中配置的flume监控目录建立软链接的示图。
图3示意性地示出了图2中的日志块和存入hdfs集群中的相应日志块。
图4示出了根据实施方式的分布式日志收集系统进行日志收集的方法。
图5示出了根据本申请另一实施方式的分布式日志收集系统进行日志收集的方法。
图6示出了根据本申请再一实施方式的分布式日志收集系统进行日志收集的方法。
图7示出了根据本申请又一实施方式的分布式日志收集系统进行日志收集的方法。
具体实施方式
以下结合附图和具体实施方式对本申请的方面进行详细说明以帮助理解如由权利要求及其等同所限定的本公开的多种实施方式。应理解的是,本文中所描述的具体实施方式仅用于解释本申请,而非对本申请的范围进行限定。需注意的是,在不冲突的情况下,本申请中的实施方式及实施方式中的特征可以相互组合。因此,本领域普通技术人员将认识到,在不背离本公开的范围和精神的情况下,可对本文中所描述的多种实施方式进行多种改变和修改。
除非另有限定,否则本文中使用的所有术语(包括技术术语和科学术语)具有与由本申请所属技术领域的普通技术人员所通常理解的含义相同的含义。还将理解的是,除非本文中明确地如此限定,否则诸如常用词典中定义的那些术语应被解释成具有与其在相关技术领域和/或本说明书的上下文中的含义一致的含义,并且不应以理想化或过于正式的含义进行解释。
以下将结合附图对本申请的实施方式进行描述。
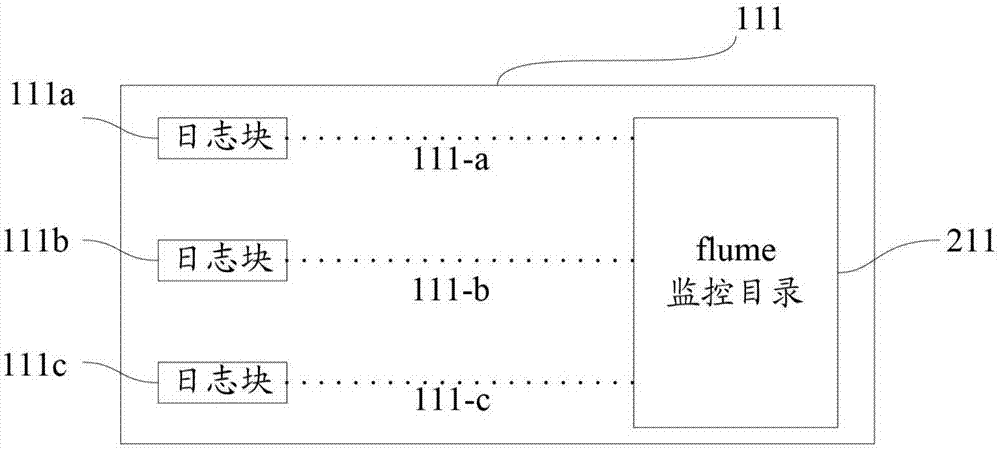
图1示出了根据本申请实施方式的分布式日志收集系统。图2示意性地示出了分布式日志收集系统中的日志打印机器将其所切分的日志块与其中配置的flume监控目录建立软链接的示图。
图1中示出的分布式日志收集系统100包括多个日志打印机器110、至少一个flume收集端机器130、hdfs集群150、处理模块170以及数据仓库190。
图1中示例性地示出日志打印机器110为四个日志打印机器(分别为日志打印机器111、日志打印机器113、日志打印机器115和日志打印机器117),但日志打印机器110的数量并不限于此,因此,图1中日志打印机器110的数量仅作为示例提供。可根据实际的情况提供更多或更少的日志印机器。类似地,图1中flume收集端机器130的数量也不限于图1中所示出的数量。
日志打印机器110配置成向flume收集端机器130传输数据仓库需要的日志(日志打印机器110应传输的日志)。
根据本申请的实施方式,日志打印机器110可在传输日志之前,将日志切分为多个日志块,并将切分后的日志块与自身中配置的flume监控目录建立软链接。
例如,如图2中所示,日志打印机器110中的日志打印机器111可将其应传输的日志切分为日志块111a、日志块111b和日志块111b,并将日志块111a、日志块111b和日志块111b分别与其自身中配置的flume监控目录211建立软链接111-a、软链接111-b、软链接111-c。
此后,日志打印机器110向flume收集端机器130传输与flume监控目录建立了软链接的日志块。
例如,在日志打印机器111将日志块111a与flume监控目录211建立了软链接111-a之后,日志打印机器111向flume收集端机器130传输日志块111a。此处,日志打印机器110向flume收集端机器130传输日志块的具体路径不受限制,可以是一个日志打印机器110向一个或多个flume收集端机器130传输日志块,也可以是多个日志打印机器110向一个或多个flume收集端机器130传输日志块。
flume收集端机器130配置成将从日志打印机器110接收的日志块存入hdfs集群150。
处理模块170配置成在hdfs集群150将所存储的日志块存入数据仓库190之前,将被日志打印机器110传输前的日志块的行数与从hdfs集群150读取的相应已传输的日志块的行数进行比较,以确定hdfs集群150中的相应日志块是否符合要求(即,是否为正常日志块)。具体地,可根据二者之间的误差是否在根据需要而预设的误差范围内来确定从hdfs集群150读取的(也是hdfs集群150中的)相应日志块是否为正常日志块。当二者之间的误差未超出预设误差范围时,处理模块170将hdfs集群150中的相应日志块确定为正常日志块;当二者之间的误差超出了预设误差范围时,处理模块170将hdfs集群150中的相应日志块确定为异常日志块。
hdfs集群150根据处理模块170确定出的结果,将被确定为正常日志块的日志块存入数据仓库190中。
此外,处理模块170还可配置成在hdfs集群150中的某一日志块被确定为异常日志块时通知传输了异常日志块的日志打印机器110(即,与异常日志块对应的日志打印机器110)将对应于该异常日志块的需要被传输的日志块与日志打印机器110中的flume监控目录重新建立软链接,相应的日志打印机器110在接收到通知信息后对应地执行重新建立软链接的步骤。这可通过以下结合图3的描述而更清楚地理解。
图3示意性地示出了图2中的日志块和存入hdfs集群中的对应的日志块。
如图3中所示,将存入hdfs集群150中的与图2中的日志块111a对应的日志块记作日志块111a’,将存入hdfs集群150中的与图2中的日志块111b对应的日志块记作日志块111b’,将存入hdfs集群150中的与图2中的日志块111c对应的日志块记作日志块111c’,如果处理模块170在将日志块111a的行数与日志块111a’的行数进行比较之后将日志块111a’确定为异常日志块,则处理模块170通知日志块111a所在的日志打印机器111将日志块111a与flume监控目录211重新建立软链接111-a。如果处理模块170在将日志块111b和日志块111c的行数分别与日志块111b’和日志块111c’的行数进行比较之后将日志块111b’和日志块111c’确定为正常日志块,则处理模块170将日志块111b’和日志块111c’存入数据仓库190。
根据本申请的实施方式,日志打印机器110所切分的日志块的行数可在日志打印机器110将日志切分为多个日志块时可通过日志打印机器111自身或与日志打印机器111通信或电连接的任何装置或组件在日志打印机器111的flume进程211每次与日志块111a建立软链接时记录(例如,记录在文件传输表中,并可被处理模块170读取),并可被处理模块170读取。应注意,处理模块170获取日志块在被传输前的行数的方式不限于此。
此外,为了保证每个日志打印机器都参与了日志传输,根据本申请的实施方式,处理模块170还可配置成在将传输前的日志块的行数与从hdfs集群150读取的相应已传输的日志块的行数进行比较之前,根据建立的应传输的日志块与日志打印机器110之间的对应关系核对应进行日志传输的日志打印机器110与当前参与日志传输的日志打印机器110是否一致,响应于二者一致,处理模块170执行将传输前的日志块的行数与从hdfs集群150读取的相应已传输的日志块的行数进行比较的过程;响应于二者不一致,处理模块170自动拉起相应日志打印机器上的flume进程。
例如,日志打印机器110可通过在将日志切分为日志块时将日志块的标志名中添加其名称即可建立日志块与日志打印机器110之间的对应关系。例如但不限于,日志打印机器113可在将日志切分为日志块时将日志块的名称中添加日志打印机器113的名称来建立应传输的日志块与日志打印机器113之间的对应关系。当应传输日志的日志打印机器110包括日志打印机器113但从hdfs集群150读取的日志块的标志名中不存在日志打印机器113的名称时,可确定出应进行日志传输的日志打印机器与当前参与日志传输的日志打印机器不一致(缺少日志打印机器113),此时,处理模块170自动拉起日志打印机器113上的flume进程。
一般而言,上述拉起过程可以一次成功,但如果机器宕机无法自身解决或者出现了网络问题,上述拉起过程不一定能成功,因此处理模块170可根据需要进一步配置成判断拉起日志打印机器113上的flume进程的过程是否成功,如果不成功,则向用户发出第一警报。
此外,处理模块170还可配置成在hdfs集群中的某一日志块被确定为异常日志块之后且在与异常日志块对应的日志打印机器110在将对应于异常日志块的应传输日志块与相应日志打印机器110上的flume进程建立软链接之前,根据对应于所述异常日志块的应传输的日志块已与相应日志打印机器中配置的flume监控目录建立软链接的次数分析是否向用户发出第二警报,如果次数超出预设值,则向用户发出第二警报,否则通知传输了异常日志块的日志打印机器110(即,与异常日志块对应的日志打印机器110)将对应于该异常日志块的需要被传输的日志块与日志打印机器110中的flume监控目录重新建立软链接,相应的日志打印机器110在接收到通知信息后对应地执行重新建立软链接的步骤。
例如,如果处理模块170确定出日志块111a’为异常日志块,则处理模块170还判断日志块111a与flume进程211建立软链接111-a的次数是否超出预设值。如果日志块111a与flume进程211建立软链接111-a的次数超出了预设值,则处理模块170向用户发出第二警报。如果未超出预设值,则处理模块170通知日志打印机器111将日志块111a与flume进程211重新建立软链接111-a,日志打印机器111在接收到通知后执行将日志块111a与flume进程211重新建立软链接111-a的过程。
与应进行日志传输的日志打印机器有关的信息可记录在机器采集表中。当日志块的标志名中添加有自身所在的日志打印机器的名称时,这样的信息可通过从应被传输的日志块的名称获取并记录在机器采集表中,但本申请不限于此。
根据本申请的实施方式,处理模块170可通过map-reduce版etl实现。
根据本申请的实施方式,日志打印机器110切分日志的过程可根据第一预设时间执行。此外,日志打印机器110所切分的日志块的名称可以与该第一预设时间关联。
为了保证收集过程的效率,根据本申请的实施方式,flume收集端机器130还可配置成每隔第二预设时间检测自身是否在存在flume进程,响应于不存在flume进程,拉起自身的flume进程。
应理解,图2中示出的日志块和软链接的数量仅出于说明的目的,其数量不限于此。另外,图1中示出的至少一个flume收集端机器130为与hdfs分开的机器,但flume收集端机器130实际上也可以是hdfs集群中的一部分,只要hdfs集群中的所述一部分执行以上结合图1至图3描述的flume收集端机器130所执行的功能且另外的部分执行以上结合图1至图3描述的hdfs集群的功能即可。
以下将结合图4至图7详细描述分布式日志收集系统进行日志收集的方法。
图4示出了根据本申请实施方式的分布式日志收集系统进行日志收集的方法。
如图4中所示,日志打印机器110首先将应传输的日志切分为多个日志块(步骤s1100),然后将应传输的日志块与其上的flume监控目录建立软链接(步骤s1300)。日志打印机器110根据软链接向flume收集端机器130传输与各自的flume监控目录建立了软链接的日志块(s1500)。flume收集端机器130在接收到日志块后将接收的日志块存入hdfs集群150(s1700)。随后,处理模块170将应传输的日志块在传输前的行数与从hdfs集群150读取的相应已传输日志块的行数进行比较以确定相应已传输的日志块是否为正常日志块(s1900)。最后,hdfs集群150将处理模块170确定出的正常日志块存入数据仓库190。
例如,如参考图2和图3所描述的,日志打印机器110中的例如日志打印机器111将日志切分为日志块111a、日志块111b和日志块111c,并将它们分别与自身上的flume监控目录211建立软链接111-a、111-b和111-c。日志打印机器111根据软链接111-a、111-b和111-c向flume收集端机器130传输日志块111a、日志块111b和日志块111c。flume收集端机器130在接收到这些日志块后将它们存入hdfs集群150,为方便描述,将hdfs集群150中的这些日志块分别记为日志块111a’、日志块111b’和日志块111c’。随后,处理模块170将日志块111a、日志块111b和日志块111c的行数(这可通过日志打印机器111将日志切分为日志块111a、日志块111b和日志块111c时由日志打印机器111自身或与日志打印机器111通信的任何其它任何装置或组件读取并记录,例如记录在例如文件传输表中)分别与日志块111a’、日志块111b’和日志块111c’的行数进行比较,确定出日志块111b’和日志块111c’为正常日志块后将日志块111b’和日志块111c’存入数据仓库190。
图5示出了根据本申请另一实施方式的分布式日志收集系统100进行日志收集的方法。
图5中的步骤s1100至步骤s1700与图4中的步骤s1100至步骤s1700相同,为使本申请的说明书更简洁,将省略对重复步骤的描述。
如图5中所示的,在flume收集端机器130在接收到日志块后将接收的日志块存入hdfs集群150(步骤s1700)之后,处理模块170根据应传输的日志块与日志打印机器之间的对应关系(可通过日志打印机器110在切分的日志块的名称中添加执行自身的机器名称而建立),核对应进行日志传输的日志打印机器110和当前参与日志传输的日志打印机器110是否一致。
在步骤s1810中,如果确定出二者一致,则进行步骤s1900(与图1中的步骤s1900相同),即将应传输的日志块在传输前的行数与从hdfs集群150读取的相应已传输日志块的行数进行比较以确定是否为正常日志块。步骤s1900和步骤s2000与图4中的步骤s1900和步骤s2000相同,因此,省略对它们的描述。
在步骤s1810中,如果确定出二者不一致,则处理模块170自动拉起相应日志打印机器110上的flume进程(步骤s1811)。
一般而言,这种拉起过程可一次成功,但如果拉起失败,则说明机器宕机无法自身解决或者出现网络问题,这时,应发出报警通知到人。
因此,可在自动拉起过程后增加判断过程,即判断拉起的过程是否成功的步骤(步骤s1813)。如果不成功,则处理模块170发出第一警报(步骤s1813)通知到用户;如果成功,继续进行步骤s1900。
例如,所需的数据仓库190中需要日志打印机器111和日志打印机器113上的日志,但处理模块170从hdfs集群读取的日志块中不存在日志打印机器113切分的日志块,则处理模块170可判断出日志打印机器113没有参与日志传输,此时,处理模块170自动拉起日志打印机器113上的flume进程以使得日志打印机器113能够继续参与日志传输过程。如果处理模块170判断出拉起过程失败,则处理模块170发出第一警报通知到用户。如果处理模块170判断出拉起过程成功,则继续进行步骤s1900。
图6示出了根据本申请再一实施方式的分布式日志收集系统100进行日志收集的方法。
图6中示出的步骤s1900与图4和图6中的步骤s1900对应,并且其进一步包括步骤s1910、步骤s1930和步骤s1950。图6中的步骤s1100至步骤s1300与图4和图5中示出的步骤s1100至步骤s1300相同,此外,图6中示出的步骤s1300与步骤s1900之间的步骤包括图4中的步骤s1500和步骤s1700,还可以进一步包括图6中的步骤s1810至步骤s1815,因此将省略对步骤s1900之前的步骤的描述。将参考图6,详细描述步骤s1900所包括的步骤s1910、步骤s1930和步骤s1950。
如图6中所示,当方法执行到步骤s1900时,处理模块170首先判断应传输的日志块在传输前的行数与从hdfs集群读取的相应已传输日志块的行数之间的误差是否超出预设的误差范围(步骤s1910)。如果判断出为超出预设的误差范围,则处理模块170将hdfs集群150中的相应日志块确定为正常日志块(步骤s1930),并将该正常日志块存入数据仓库190(步骤s2000)。如果判断出超出了预设的误差范围,则处理模块170将hdfs集群150中的相应日志块确定为异常日志块(步骤s1950),并返回步骤s1300。
例如,参考图2和图3,当处理模块170在确定出,日志块111a的行数与日志块111a’的行数之间的误差(例如,(日志块111a的行数-日志块111a’的行数)的绝对值/日志块111a的行数*100%)超出了预设的误差范围(例如,5%),则日志打印机器111将日志块111a与日志打印机器111上的flume监控目录211重新建立软链接,并继续进行后续步骤。
图7示出了根据本申请又一实施方式的分布式日志收集系统100进行日志收集的方法。
除步骤s1950之后还进行步骤s1951和步骤s1953之外,图7中示出的日志收集方法的其余步骤与图6中示出的步骤相同,因此将省略重复描述。
如图7中所示,在步骤s1950之后且在返回至步骤s1300之前,处理模块170还根据日志块与相应flume进程建立软链接的次数分析是否向用户发出第二警报,具体地,在将日志块确定为异常日志块后,处理模块170还判断日志块与相应flume进程建立软链接的次数是否超出预设值(步骤s1951)。如果未超出预设值,则返回步骤s1300。如果超出了预设值,则向用户发出第二警报(s1953)。
例如,参考以上结合图2和图3描述的,如果处理模块170确定出日志块111a’为异常日志块,则处理模块170还判断日志块111a与flume进程211建立软链接111-a的次数是否超出预设值。如果日志块111a与flume进程211建立软链接111-a的次数超出了预设值,则处理模块170向用户发出第二警报。如果未超出预设值,则处理模块170通知日志打印机器111将日志块111a与flume进程211重新建立软链接111-a,日志打印机器111在接收到通知后执行将日志块111a与flume进程211重新建立软链接111-a的过程。
日志块111a与flume进程211建立软链接111-a的次数可通过日志打印机器111自身或与日志打印机器111通信或电连接的任何装置或组件在日志打印机器111的flume进程211每次与日志块111a建立软链接时记录,并可被处理模块170在执行步骤s1951前或时读取。
在参照图4至图7所描述的方法中,flume收集端机器还可每隔第二预设时间检测自身是否在存在flume进程,响应于不存在flume进程,拉起自身的flume进程。
本申请在日志传输和收集的过程中,通过在日志被存入数据仓库之前自动地核对日志打印机器和日志采集机器以及对传输日志进行检测而使得进入数据仓库的数据有效,并且可减少人工成本。此外,可根据需要设置数据丢失率的容忍范围,使得进入数据仓库的数据在具有所需准确度的同时能够高效地收集。
本申请提供的分布式日志收集系统和分布式日志收集方法能够可靠地收集日志,并且可以避免因网络抖动造成的数据丢失。具体地,本申请提供的分布式日志收集系统和分布式日志收集方法能够直接对传输结果进行自动检测,在发现传输结果不合格时,自动执行相关的重传、进程拉起等操作,使得收集的日志更加稳定可靠,并极大地降低了人工运维成本。能够使得日志传输和收集在无人值守的情况下能够长期稳定地运行,为更高效更稳定的数据仓库打下了基础。
以上描述仅为本申请的示例性实施方式以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的申请范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不背离所述申请构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!