一种基于THz吸收谱和LOO‑RELM算法的转基因豆油快速鉴别方法与流程
本发明涉及转基因豆油的快速无损检测领域,特别是涉及一种基于太赫兹吸收谱和loo-relm算法的转基因豆油识别领域。
背景技术:
转基因作物的诞生及其产业化彻底改变了世界传统的植物遗传育种方法,这项被认为是生物技术“第二次浪潮”的革命已经开始影响到人类的日常生活。转基因大豆,是指利用转基因技术,通过基因工程方法导入外源基因所培育的具有特定性状的大豆品种。转基因大豆可能同时具有多重优点,例如高产、优质、抗寒、抗旱、抗涝、抗病毒、抗虫、抗盐碱、抗除草剂等,有利于提高国民经济收入。对于转基因和非转基因大豆油,虽然目前为止使用常规的化学分析方法对这两种豆油的营养成分进行分析,并没有发现它们的营养成分有任何差异,但是作为重要的转基因作物——转基因大豆,其生产的豆油及其制品作为人类食品加工原料、动物饲料对人类的影响一直受到很大的争议。而目前我国对于转基因豆制品的安全性评价方面,仍缺乏相应的评价标准和技术规范,所以,检测豆制品是否为转基因有重要的意义。
传统的转基因豆油检测方法,必须检测由外源基因产生的蛋白质,或先从大豆油中将极微量的dna萃取出来,然后才能对dna进行检测,然而对于经过粉碎、浸提、高温杀菌和挤压等生产加工过程得到的豆油,在经过复杂的工业加工后,成分已经发生巨大的改变,精炼的程度越高,检测转基因成分也越难,很难进行转基因与否的鉴别。
许多学者研究发现,thz光谱技术在生物分子研究中的独特优势许多生物分子的振动和转动能级都位于thz波段(30μm~3000μm)内,具有“指纹谱”。thz光谱技术对探测物质结构存在的微小差异和变化非常灵敏,但从现有的光谱测量结果来看,由于豆油中多种成分吸收谱的相互叠加,单靠“指纹谱”来进行鉴别几乎不可行,必须借助化学计量学及模式识别等方法来进行鉴别分析。
针对这一难题,本发明将loo-relm算法与太赫兹光谱技术相结合,并采用适当的谱图预处理方法,实现转基因豆油的无损、绿色和快速检测。
技术实现要素:
针对传统转基因豆油的检测不足,本发明提出了基于太赫兹吸收谱和loo-relm算法的转基因豆油识别方法。该发明实现步骤如下:(1)收集超市在售转基因和非转基因豆油样品,并做相应的标记;(2)thz光谱仪器设备进行参数的设定与优化,采集转基因和非转基因豆油样品的太赫兹光谱;(3)将采集的光谱进行批量归一化预处理,并剔除明细异常样本点;(4)根据经典模型提取0.2-1.8thz范围内样品吸收谱,借助模式识别的正则极限学习机(relm)算法建立基于太赫兹光谱的转基因和非转基因豆油分类模型;(5)建模过程中采用参数网格组合策略,通过留一(loo)交叉验证法确立隐含层节点数l和正则化参数c最优参数组合,使分类模型获得较好分类准确率的同时获得最佳泛化性能;(6)使用该模型对样品进行预测。
附图说明
图1本发明所述方法的流程示意图。
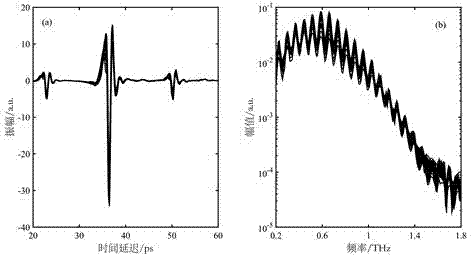
图2被测豆油样本thz时域脉冲及对应频谱。
图3elm网络结构图。
图4不同c、l参数组合下relm模型对训练集、预测集分类准确率。
具体实施方式
下面结合附图对本发明作进一步详细描述。
本发明的实现流程图,如图1所示,其具体步骤如下:
(1)研究对象的选取,收集转基因和非转基因豆油样品,并做相应的标记;
(2)根据研究对象选择2.0mm光程石英比色皿作为样本容器,同时对thz光谱仪器设备进行参数的设定与优化;将空比色皿放入thz光谱仪器中采集参考信号er(t),相同实验条件下,将豆油样本放入比色皿容器置入thz光谱仪样品台,采集样品信号es(t);
(3)对采集的thz光谱信号进行误差分析,批量归一化预处理,剔除明细异常样本点,并利用改进解卷积算法去除f-p效应干扰;
(4)借助经典thz透射式光学参数物理模型对步骤(3)中预处理后的豆油thz时域光谱信号进行转换,提取相应的样品thz吸收谱。并将转换后的样品吸收谱按2:1划分为训练集和预测集。
(5)将步骤(4)中提取的吸收谱借助模式识别loo-relm算法建立分类模型,对豆油属性进行定性分析。将分类模型预测结果与实际样品属性进行对照,得出模型的预测准确率。
其中:
步骤(1)方法是:从重庆各超市、农贸批发市场、网络商城收集67份非转基因和转基因豆油样品,其中37份为转基因豆油,用“1”表示30份为非转基因豆油,用“2”表示;
步骤(2)方法是:在本文中,采用立陶宛生产的t-specthz时域光谱仪对每份豆油样品进行thz透射光谱扫描。为便于测量使用2.0mm光程的石英比色皿作为液体容器。测量过程中为了减少空气中水蒸汽对thz-tds信号影响,在密封的光路中充入氮气,使光路内的相对湿度小于5%,温度保持在298k左右,为了保证实验数据的准确化在不同位置对每个样品进行多次扫描,时域平均后就得到了该样品的thz时域光谱信息,其对应时域、频域光谱如图2所示。
步骤(3)的方法是:在测量过程中,充分考虑各种非目标因素对测量结果的影响,对光谱数据进行预处理:对所有样品光谱信号进行批量归一化,剔除明显异常信号;在此基础上,充分考虑光路中各种介质对thz波的非线性吸收,在传统分析模型的基础上,对naftaly、王等提出的解卷积算法进行改进,有效去除液体池窗片及仪器自身f-p效应引起的频谱寄生振荡。
步骤(4)方法是:借助如下经典thz透射物理模型对步骤(3)预处理后所得thz信号进行分析,提取样品吸收谱。
其中t(w)为豆油样品透射函数,pr(w)、ps(w)为er(t),es(t)分别进行傅里叶变换得到的频谱。k=2π/λ=ω/c为波数,λ为光的波长,c为空气中的光速,w为电磁波的角频率。ds分别为样品、比色皿壁的厚度。忽略界面多次反射,且认为样品、比色皿的消光系数远小于折射率时,则得到样品的折射率ns、消光系数ks和吸收系数α的计算公式如下:
从样品吸收谱数据集中随机选出其中45份样品作为训练集建立基于relm建立校正模型,剩余22份样品组成的预测集。
步骤(5)方法是:将步骤(4)提取的thz吸收谱作为loo-relm模型的输入值,对relm分类模型中的两个参数,隐含层节点数l和正则化参数c采用模型参数网格组合策略,通过loo交叉验证方法寻找最优的参数组合,在最优参数组合下利用loo-relm算法,计算出
其中,传统的极限学习(extremelearningmachine,elm)算法是一种特殊类型的单隐含层前向神经网络,仅包含一个节点层,其网络结构图如图3所示。给定包含n个样本的训练集:s={(xj,tj)|j=1,2,…,n},xj=[xj1,xj2,…,xjd]t∈rd,tj=[tj1,tj2,…,tjd]t∈rm,则包含l个隐含层节点的elm输出可表示为
β=[β1,β2,…,βl]t为隐含层到输出层之间的输出权值,h(x)=[h1(x),h2(x),…,hl(x)]为elm隐含层非线性特征映射,它实现了样本数据从d维原始样本空间到l维特征空间的一个非线性映射,即隐含层对于输入x得到的输出行向量,hi(x)为隐含层第i个节点对应输出。需要说明的是隐含层节点的输出并不是固定不变的,在不同的激励函数的作用下,可以得到不同的隐含层输出。而激励函数g(a,b,x)可以是满足elm算法全局逼近能力的任意有界、非常数、分片连续函数。
从理论上来说,elm训练模型能够逼近任意目标函数,其输出值能以最小的误差逼近真实值,并且将复杂的神经网络训练过程转化为矩阵求逆问题,从而极大地提高了网络训练速度。但是这种算法也有可能在大样本情况下出现“过拟合”,即出现训练精度与测试精度不一致的情况,从而降低模型对测试集的预测精度。为了在输出权重范数与训练误差之间取得最佳折衷,黄广斌等在elm算法的基础上引入正则化参数c,该算法被称为正则化极限学习机(regularizedextremelearningmachine,relm)。relm算法同时实现了训练误差与输出权重的最小化,增强原算法的鲁棒性和范化性,可以对豆油进行“无损、快速”检测。在寻找最优正则化参数c时,本发明采用了常见的leave-one-out交叉验证(记为loo-cv)。loo交叉验证充分利用了集合中所有的训练样本,因此最接近原始样本的分布,模型训练过程中没有随机因素影响实验数据,确保实验过程是可以被复制的,评估结果可靠,尤其适用于小样本数据分析。故基于约束优化elm模型的数学表达式可以描述为
其中β=[β1,β2,…,βl]t为隐含层到输出层之间的输出权值,h为隐含层输出矩阵,将方程转化为约束条件hβ-t=e下,目标函数的
其中i为l维单位矩阵。
本发明在前人研究基础上,在elm理论框架下对loo交叉验证算法进一步优化,以模型预测残差平方和(thepredictionsumofsquares,press)作为指标评价模型优劣,确定最优正则参数copt。press值越小,说明模型的预测能力越好,因此一般选择press值最小时对应的正则参数c为最优正则参数copt。loo交叉验证过程中需要进行n次迭代,计算量非常大,但借助线性回归则不需要进行n次relm模型的显示训练。为了进一步提高模型loo交叉验证效率,降低参数寻优过程中press计算量,对隐含层输出矩阵h进行奇异值分解。依据误差最小原则选择最小press对应参数c作为最优正则参数,即
具体操作如下:从样品数据集中优选出其中45份样品作为训练集建立基于relm建立校正模型,并对剩余22份样品组成的预测集进行预测,并将预测结果与样品真实属性进行对比。在后续的处理中,relm的隐含层节点的激活函数为sigmoid函数,即
综上所述,经过模型训练,参数寻优,在正确选择模型参数的前提下,loo-relm算法对豆油样本训练集、测试集的分类准确率都能达到95%以上。基本满足转基因豆油的分类需求。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
算法1:计算输出权重
输入参数:隐含层输出矩阵hn×l,训练集标签tn×m,c寻优向量[cmin:δc:cmax]
输出参数:最优正则参数copt,及对应的输出权重
1.ifl≤n
2.对矩阵hn×l进行奇异值分解,[u,d,v]=svd(h)
3.forci=cmin:δc:cmax
4.计算hat矩阵对角元素向量d_hat
5.令p=repmat(θ,1,n).*ut
6.计算q=u.*pt
7.d_hat=[hat11,hat22,…hatnn]t=sum(q,2)
8.计算训练集预测标签
9.计算press统计误差eloo
10.令
11.
12.end
13.返回最小eloo对应参数copt,及其对应hat矩阵对角元素向量
14.计算copt对应最优输出权重
15.
16.else
17.对矩阵
18.forci=cmin:δc:cmax
19.计算hat矩阵对角元素向量d_hat
20.令p=repmat(θ,1,n).*vt
21.计算q=v.*pt
22.d_hat=[hat11,hat22,…hatnn]t=sum(q,2)
23.计算训练集预测标签
24.计算press统计误差eloo
25.令
26.
27.end
28.返回最小eloo对应参数copt,及其对应hat矩阵对角元素向量
29.计算copt对应最优输出权重
30.
31.end
算法2:loo-relm回归模型
输入参数:训练集an×d,训练集样本真实值tn,隐含层节点数l测试集yn×d,c寻优向量[cmin:δc:cmax],激励函数类型g
输出参数:预测集样本预测值
(1)随机给定隐含层节点参数(ai,bi),i=1,2,…,l;
(2)根据指定激励函数g,计算隐含层输出矩阵hn×l=h(a1,a2,…,al,x1,x2,…,xn,b1,b2,…,bl);
(3)将hn×l带入算法1,寻找最优正则参数copt及对应输出权重
(4)对预测集样本计算模型预测输出
算法3:loo-relm分类器
对于一个包含m类n个样本的训练集的分类问题
把每个训练集样本的标签映射为一个m维矢量,则定义新的m维目标向量
其中
输入参数:训练集an×d,训练集样本真实分类标签值tn,隐含层节点数l,测试集yn×d,测试集样本真实分类标签值tn,c寻优向量[cmin:δc:cmax],激励函数类型g
输出参数:预测集样本预测值
(1)根据式(14)将训练集样本标签n维矢量映射为一个m×n维目标矩阵s;
(2)随机给定隐含层节点参数(ai,bi),i=1,2,…,l;
(3)根据指定激励函数g,计算隐含层输出矩阵hn×l=h(a1,a2,…,al,x1,x2,…,xn,b1,b2,…,bl);
(4)将hn×l带入算法1,寻找最优正则参数copt及对应输出权重
(5)对预测集样本计算模型预测输出
(6)计算分类模型预测准确率
- 还没有人留言评论。精彩留言会获得点赞!