一种基于Spark框架进行全文检索的实现方法与流程
本发明属于大数据处理领域,具体涉及一种基于spark框架进行全文检索的实现方法。
背景技术:
随着计算机技术的不断发展和信息化程度的不断提高,数据量迅速增长,大数据应用越来越广泛。如,在网络安全上,使用大数据技术分析网络攻击行为;在电子商务上,使用大数据技术分析用户购物喜好或最受青睐的商品;在城市建设上,利用大数据技术构建智慧城市,方便人民出行。诸如此类,大数据技术在建设节约型社会,提高生成效率等方面起到了积极的推动作用;但随着数据量的持续增大和大数据应用的不断发展,面向海量数据的存储和应用也在蓬勃发展,随之而来的是对检索大数据的要求越来越高。在海量数据检索应用中,全文检索是最常用的统计功能之一,其可用性和效率直接影响了业务应用。
全文检索是一种将文件中所用文本与检索项匹配的文字资料检索方法,可以方便的进行对数据的相关统计和分析;而apache基金会的spark框架是一个通用并行框架,具有较高的效率及可用性,提供了同hive一样的hiveql接口;但是原生的spark框架并未支持全文检索这一检索方式。因此,如何使用spark框架来进行全文检索是一个需要解决的关键问题。
技术实现要素:
本发明为了解决上述问题,提出了一种基于spark框架进行全文检索的实现方法;通过对数据进行索引创建和查询,高效的对海量数据进行全文检索,并使用索引和缓存来提高全文检索的效率,提高全文检索的可用性。
具体步骤如下:
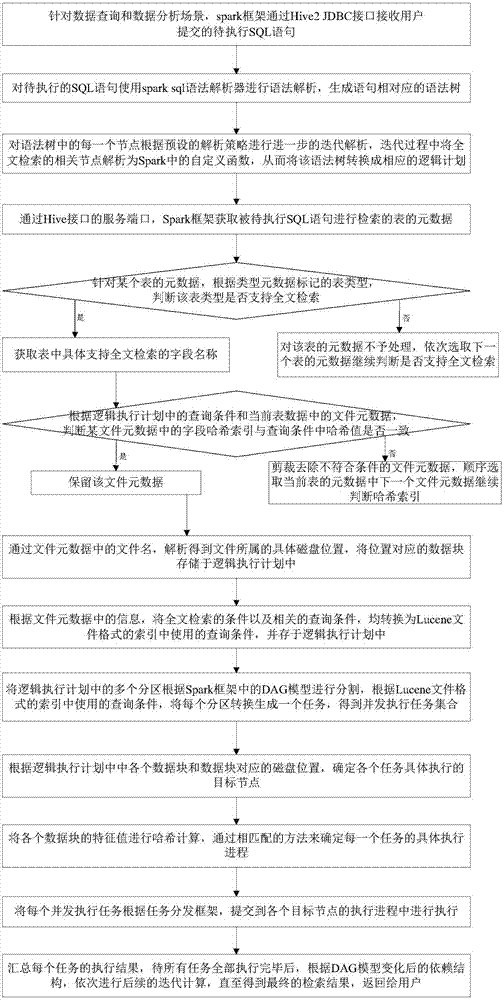
步骤一、针对数据查询和数据分析场景,spark框架通过hive2jdbc接口接收用户提交的待执行sql语句;
步骤二、对待执行的sql语句使用sparksql语法解析器进行语法解析,生成语句相对应的语法树;
步骤三、对语法树中的每一个节点进行迭代解析,将该语法树转换成相应的逻辑计划,并将逻辑计划中全文检索的相关节点解析为spark中的自定义函数。
每一节点即为一个语法结构,每个语法结构都有相应的逻辑执行计划;逻辑执行计划中存储的是查询条件。
步骤四、通过hive接口的服务端口,spark框架获取对待执行sql语句进行检索的所有表的元数据;
所有表的元数据均存储在hive元数据服务中。
spark框架进行全文检索所使用的数据结构,包括两部分,第一部分是表的元数据,第二部分是数据块和索引。
其中,表的元数据又包括字段元数据,分区元数据,类型元数据和文件元数据;
字段元数据包括字段名称和字段类型;分区元数据包括分区类型和分区名;类型元数据包括表类型和支持全文检索的字段;文件元数据包括文件名,文件地址和字段哈希索引;
数据块和索引包括n个时间分区,每个时间分区中分别包括若干数据块和索引;每个数据块各对应一个索引;
步骤五、针对某个表的元数据,根据类型元数据标记的表类型,判断该表类型是否支持全文检索,如果是,获取支持全文检索的字段名称,进入步骤六;否则,对该表的元数据不予处理,依次选取下一个表的元数据继续判断是否支持全文检索。
步骤六、根据逻辑计划存储的查询条件和当前表的元数据,判断某文件元数据中的字段哈希索引与查询条件中的哈希值是否一致,如果是,保留该文件元数据,进入步骤七;否则,剪裁去除不符合条件的文件元数据,顺序选取当前表的元数据中下一个文件元数据继续判断哈希索引;
步骤七、通过文件元数据中的文件名,解析得到文件所属的具体磁盘位置,将位置对应的数据块存储于逻辑执行计划中;
步骤八、根据文件元数据中的信息,将全文检索的条件以及相关的查询条件,均转换为lucene文件格式的索引中使用的查询条件,并存于逻辑执行计划中。
同时,将逻辑执行计划中的其他检索条件通过迭代的形式体现于逻辑执行计划中。
步骤九、将逻辑执行计划中的多个分区根据spark框架中的dag模型进行分割,根据lucene文件格式的索引中使用的查询条件,将每个分区转换生成一个任务,得到并发执行任务集合;
步骤十、根据逻辑执行计划中各个数据块和数据块对应的磁盘位置,确定各个任务具体执行的目标节点;
步骤十一、将各个数据块的特征值进行哈希计算,通过相匹配的方法来确定每一个任务的具体执行进程;
步骤十二、将每个并发执行任务根据任务分发框架,提交到各个目标节点的执行进程中进行执行;
步骤十三、汇总每个任务的执行结果,待所有任务全部执行完毕后,根据dag模型变化后的依赖结构,依次进行后续的迭代计算,直至得到最终的检索结果,返回给用户。
本发明的优点及带来的有益效果在于:
1)、一种基于spark框架进行全文检索的实现方法,使用该方法进行大数据检索时具有较高的效率,可以快速的完成海量数据的全文检索,在大数据处理领域具有很强的实用性和应用范围,具有很广泛的应用前景。
2)、一种基于spark框架进行全文检索的实现方法,不仅能够基于spark对海量数据进行全文检索,同时还能通过一些索引和缓存的使用来减少对系统资源的使用,提高检索的效率,降低延时,符合当前大数据分析检索应用的实际需求。
附图说明
图1为本发明基于spark框架进行全文检索实现的表数据组织结构;
图2为本发明基于spark框架进行全文检索的实现方法的流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对根据本发明一个实施例的层次分段式的备份数据组织管理方法进一步详细说明。
本发明首先在接收用户提交的sql查询语句后,进行语法解析生成sql语句的语法树,通过对语法树的内容进行进一步解析来生成检索的逻辑执行计划,在生成逻辑执行计划的过程中,将全文检索相关的语句解析为spark中的自定义函数。然后,从hive中获取对执行sql语句进行检索的表的元数据,判断被全文检索的字段是否支持全文检索,若支持,则根据检索的具体条件通过文件元数据中的字段哈希索引对数据块进行初步的裁剪,以减少被检索的文件数据。继而,根据文件元数据中的信息,将全文检索的条件以及相关的查询条件转换为lucene文件格式索引中的查询条件并存于逻辑执行计划中;从文件元数据中获取数据块所具体存放的磁盘位置,也存放于逻辑执行计划中;将逻辑执行计划中的其它检索条件通过迭代的形式体现于逻辑执行计划中。
最后,将逻辑执行计划根据spark的dag模型,转换为可分布式执行的任务集合,通过逻辑执行计划中所保存的各个数据块位置来确定任务具体执行的目标节点。通过对任务目标数据块的特征值得哈希计算,来确定任务所具体执行的目标进程,以此来保证对缓存的有效重复使用,来提高查询的效率。对任务进行分发执行,并汇总执行结果,根据执行计划进行后续的迭代计算,获取检索的最终结果,返回给提交检索的用户。
如图2所示,基于spark进行全文检索的操作过程具体步骤如下:
步骤一、针对数据查询和数据分析场景,spark框架通过hive2jdbc接口接收用户提交的待执行sql语句;
步骤二、对待执行的sql语句使用sparksql语法解析器进行语法解析,生成语句相对应的语法树;
步骤三、对语法树中的每一个节点根据预设的解析策略进行进一步的迭代解析,迭代过程中将全文检索的相关节点解析为spark中的自定义函数,从而将该语法树转换成相应的逻辑计划。
每一节点即为一个语法结构,每个语法结构都有相应的逻辑执行计划;逻辑计划中存储的是查询条件。
步骤四、通过hive接口的服务端口,spark框架获取被待执行sql语句进行检索的表的元数据;
表的元数据存储在hive元数据服务中。如图1所示,给出了基于spark的全文检索的实现的数据组织结构;
spark框架进行全文检索所使用的数据结构,包括两部分,第一部分是表的元数据,第二部分是数据块和索引。
在实现例中,表的基本信息包括表名和表所属的数据库名称;表的元数据中主要包含四类内容,分别为字段元数据,分区元数据,类型元数据和文件元数据;
字段元数据包括表中所存储的各个字段的名称和字段类型;
分区元数据包括表的分区字段、分区类型和分区名;包含分区类型的具体分区情况,在实现例中以时间日期作为分区,在检索时可以裁剪掉不需要的日期数据,减少检索的目标数据量;
类型元数据包括该表的具体类型,表中是否有字段支持全文检索;
文件元数据包括表中所有的文件名称,文件地址和字段哈希索引;在实现例中,文件元数据通过在hive对应的hdfs里创建空文件的形式来实现,在空文件的文件名中将文件的实际磁盘位置和文件的字段哈希索引进行拼接,来达到方便读取文件元数据的目的。
在文件元数据所指示的具体磁盘位置上存储有数据块和lucene文件格式的索引。
数据块和索引包括n个时间分区,每个时间分区中分别包括若干数据块和索引;每个数据块各对应一个索引;
元数据中包含表中的各个字段名称类型;表的分区情况;表的类型元数据,表是否支持全文检索以及哪一个字段支持全文检索;表的数据文件元数据,在文件元数据中包含表的所有数据文件名、文件存放的具体磁盘位置;数据块在加载时可按照字段哈希值分组存放,可将字段哈希值也存入文件元数据中,以方便对文件的裁剪。在数据块索引中采用lucene文件格式的索引存储数据块的索引值,以在检索时进行全文检索。
该数据组织结构可以支持完成如下操作:
1)根据字段哈希索引进行数据块的裁剪;
2)根据文件元数据获取数据存放的磁盘位置;
3)根据lucene文件格式的索引获取符合全文检索条件的数据。
步骤五、针对某个表的元数据,根据类型元数据标记的表类型,判断该表类型是否支持全文检索,如果是,获取表中具体支持全文检索的字段名称,进入步骤六;否则,对该表的元数据不予处理,依次选取下一个表的元数据继续判断是否支持全文检索。
步骤六、根据逻辑执行计划中的查询条件和当前表数据中的文件元数据,判断某文件元数据中的字段哈希索引与查询条件中哈希值是否一致,如果是,保留该文件元数据,进入步骤七;否则,剪裁去除不符合条件的文件元数据,顺序选取当前表的元数据中下一个文件元数据继续判断哈希索引;
对文件进行剪裁,减少需要检索的文件数量;
步骤七、通过文件元数据中的文件名,解析得到文件所属的具体磁盘位置,将位置对应的数据块存储于逻辑执行计划中;
步骤八、根据文件元数据中的信息,将全文检索的条件以及其它可使用lucene文件索引进行查询的相关条件,均转换为lucene文件格式的索引中使用的查询条件,并将对lucene文件索引的查询方法存放于逻辑执行计划之中;
同时,将逻辑执行计划中的其它与全文检索不相关的检索条件,通过迭代的形式对逻辑执行计划进行相应的变换,完善逻辑执行计划;
步骤九、将生成的逻辑执行计划根据spark中的dag模型,转换生成可并发执行的任务集合;
具体为:将spark逻辑执行计划(rdd)中的多个分区进行分割,每个分区转化成一个spark中的任务,生成的并发执行的任务集合。
步骤十、根据逻辑执行计划中各个数据块和数据块对应的磁盘位置,对各个任务的具体执行的目标节点;
步骤十一、将各个数据块的特征值进行哈希计算,通过相匹配的方法来确定每一个任务的具体执行进程;
步骤十二、将每个并发执行任务根据spark中的任务分发框架,提交到各个目标节点的执行进程中进行执行;
每个任务独立执行和返回,由此来提升对执行进程中缓存的利用。
步骤十三、汇总每个任务的执行结果,待所有任务全部执行完毕后,根据dag模型变化后的依赖结构,依次进行后续的迭代计算,直至得到最终的检索结果,返回给用户。
应该注意到并理解,在不脱离后附的权利要求所要求的本发明的精神和范围的情况下,能够对上述详细描述的本发明做出各种修改和改进。因此,要求保护的技术方案的范围不受所给出的任何特定示范教导的限制。
- 还没有人留言评论。精彩留言会获得点赞!