一种三角形图元并行光栅化定序方法与流程
本发明涉及计算机硬件技术领域,涉及一种三角形图元并行光栅化定序方法。
背景技术:
随着图形化应用的不断增加,早期单靠cpu进行图形绘制的解决方案已经难以满足成绩和技术增长的图形处理需求,图形处理器(graphicprocessingunit,gpu)应运而生。从1999年nvidia发布第一款gpu产品至今,gpu技术的发展主要经历了固定功能流水线阶段、分离染色器架构阶段、统一染色器架构阶段,其图形处理能力不断提升,应用领域也从最初的图形绘制逐步扩展到通用计算领域。gpu流水线高速、并行的特征和灵活的可编程能力,为图形处理和通用并行计算提供了良好的运行平台。
目前,我国尚无基于统一染色架构的gpu,各领域显示控制系统中大量采用国外进口的商用gpu芯片。尤其是在军用领域中,国外进口商用gpu芯片存在温度和环境适应性差、无法保证电路本身或配套软件没有“后门”、包含大量军用领域不需要的冗余功能单元,功耗指标无法满足要求、商用gpu芯片更新换代快,随时面临停产、断档,难以满足武器装备持续保障等缺陷,在安全性、可靠性、保障性等方面的存在重大隐患。而且,出于政治、军事、经济等原因,国外对我国实行技术“封锁”和产品“垄断”,难以获得gpu芯片的底层技术资料,如寄存器资料、详细内部微架构、核心软件源码等,导致gpu功能、性能无法充分发挥,且移植性较差;上述问题严重制约了我国显示系统的独立研制和自主发展。
三角形图元并行光栅化定序方法,是提升和增强gpu图形处理能力的关键技术。突破高性能光栅化单元设计关键技术,研制高性能图形处理器芯片迫在眉睫。
技术实现要素:
本发明的目的是:提供一种三角形图元并行光栅化定序方法,能够提升光栅化单元硬件资源的利用率,从而提升三角形图元的处理吞吐率和像素生成能力,尤其对于完全在三角形内像素tile与三角形边界像素tile比例较大的三角形图元来说,性能提升更为明显。
本发明的技术解决方案是:
一种三角形图元并行光栅化定序方法,其特征为:所述三角形图元并行光栅化定序方法至少包括三角形像素tile扫描阶段、边界像素tile处理阶段、完全在内像素tile处理阶段、像素tile属性插值请求仲裁阶段和像素tile属性插值阶段;
三角形像素tile扫描阶段:对三角形图元实现光栅化,像素tile的扫描路径基于zigzag算法进行,串行扫描时遇到的边界tile送入边界像素tile通道fifo中;遇到的完全在内tile送入完全在内tile通道fifo中;边界像素tile和完全在内tile按照光栅化的顺序被统一编号排序分别进入到边界像素tile处理阶段和完全在内像素tile处理阶段;
边界像素tile处理阶段:监控像素tile扫描阶段输出,基于三角形数量计数器bbtn,判断边界像素tile处理单元中处理的tile属于几个三角形;使用fifo存储三角形像素tile扫描阶段输出的边界像素tile;
完全在内像素tile处理阶段:使用fifo存储三角形像素tile扫描阶段输出的完全在内tile;
像素tile属性插值请求仲裁阶段:按照tile的光栅化顺序将tile逐个输出到像素tile属性插值阶段;tile属性插值请求仲裁逻辑的请求源有两个:边界像素tile和完全在内tile;当像素tile属性插值请求仲裁阶段通过查询边界像素tile处理阶段的三角形数量计数器bbtn得知tile处理单元中处理的边界像素tile属于2个以上三角形则拒绝属于后一个三角形的任何一个像素tile进入像素属性插值阶段进行处理;
像素tile属性插值阶段:对三角形图元在像素tile层次进行属性插值运算。
本发明的技术效果是:本发明能够提升光栅化单元属性插值计算资源的利用率,从而提升光栅化单元的三角形图元的处理吞吐率和像素生成能力,尤其对于完全在三角形内像素tile与三角形边界像素tile比例较大的三角形图元来说,性能提升更为明显。
附图说明
图1是本发明一种三角形图元并行光栅化定序方法示意图;
图2是本发明一种三角形图元并行光栅化定序方法实施方案图。
具体实施方式
下面结合附图和具体实施例,对本发明的技术方案进行清楚、完整地表述。显然,所表述的实施例仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提所获得的所有其它实施例,都属于本发明的保护范围。
本发明能够监控像素tile扫描阶段输出的,且未进入像素属性插值阶段进行处理的所有像素tile;能够对三角形图元在像素tile层次进行并行属性插值运算,并在属于前一个三角形的所有像素tile未进入像素属性插值阶段进行处理前,能够拒绝属于后一个三角形的任何一个像素tile进入像素属性插值阶段进行处理。
本发明所述的三角形图元并行光栅化定序方法,至少包括三角形像素tile扫描阶段、边界像素tile处理阶段、完全在内像素tile处理阶段、像素tile属性插值请求仲裁阶段和像素tile属性插值阶段,或者具有类似功能的阶段。
本发明能够识别出位于边界像素tile处理阶段进行处理的所有像素tile属于一个或者几个不同的三角形。
本发明具备对在一个三角形所覆盖的多个像素tile的范围内进行乱序属性插值的能力。
本发明具备对属于多个三角形所覆盖的多个像素tile以三角形为单位进行排序,并按顺序进行属性插值的能力。
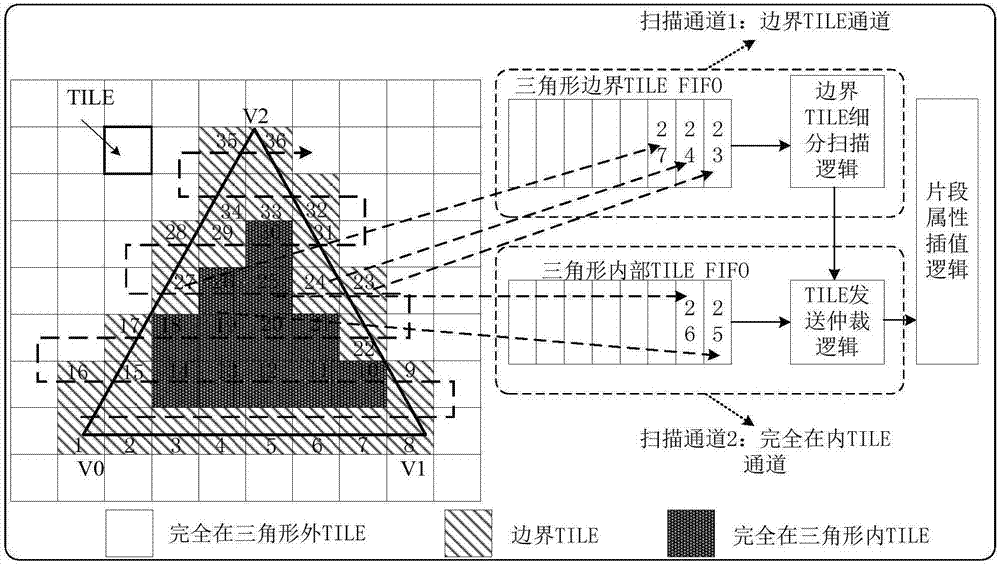
如图1所示,tile属性插值请求仲裁逻辑的请求源有两个:边界像素tile和完全在内tile。如果发出请求的边界像素tile属于δ1,而发出请求的完全在内tile属于δ2,而δ1的绘制顺序在δ2之前,由于边界像素tile处理单元的处理速度较tile扫描单元慢,则δ2的tile有可能先于δ1的tile被绘制,从而可能导致在三角形空间位置重叠,且深度相同的情况下发生绘制错误。
如图2所示,tile的扫描路径基于zigzag算法进行,串行扫描时遇到的边界像素tile送入边界像素tile通道fifo中;遇到的完全在内tile送入完全在内tile通道fifo中。只要边界像素tile处理单元中已经容纳的tile属于同一个三角形,且未超出边界像素tile处理单元的缓冲能力,扫描过程就不会停止。扫描到的后续tile如果仍然是边界像素tile,则继续进入扫描通道1的边界像素tilefifo中,如tile24和tile27;如果是完全在三角形内的tile,则进入扫描通道2的完全在内tilefifo中,如tile26和tile27。否则,tile扫描单元输出的后续完全在内tile需要暂停被发往属性插值单元,这是为了保证绘制顺序性,而不会影响性能,因为边界像素tile处理单元已经缓冲了足够多的tile等待处理。
三角形总是先从边界像素tile开始扫描,然后才会扫描到完全在内tile。也就是说,如果像素tile处理单元中正在处理的三角形边界像素tile属于两个或两个以上的三角形,此时如果tile扫描单元输出一个完全在内的tile,则tile扫描输出单元不能向tile属性插值请求仲裁单元发出属性插值请求,直到边界tile处理单元中正在处理的三角形边界tile都属于同一个三角形后,tile扫描单元才能输出完全在内的tile;如果边界tile处理单元中正在处理的三角形边界tile属于两个或两个以上的三角形,此时如果tile扫描单元输出一个边界tile,则可以直接送入边界tile地址fifo中,因为边界tile单元是完全串行处理tile的。
可以看出,关键问题在于如何判断边界tile处理单元中处理的tile到底属于几个三角形。一种方法是tile扫描单元每次输出一个三角形第一个边界tile时,同时也向边界tile处理单元发送一个三角形首tile标志信号fben(firsttileenable),而边界tile处理单元在每次收到fben=1时,边界tile处理单元内部三角形数量计数器bbtn(boardtiletrianglenumber)加1;而每当tile扫描单元每次输出一个三角形最后一个边界tile时,同时也向边界tile处理单元发送一个三角形末tile标志信号lben(lasttileenable),每当一个三角形最后一个边界tile流出边界tile处理单元时,bbtn减1。当然,如果边界处理单元为空闲,bbtn=0。通过判断bbtn的值,tile扫描单元就可以得到当前边界tile处理单元中正在处理的tile属于几个三角形。
最后应说明的是,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述各实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!