一种人脸表情分类方法、装置及存储介质与流程
本发明涉及用于识别图形的数据识别技术,尤其涉及一种人脸表情分类方法、装置及存储介质。
背景技术:
人脸表情分为高兴、生气、惊恐、平静等表情特征,不同的表情特征,提取的纹理信息也不相同,传统的分类人脸表情的方法采用机器学习方法,将人脸表情的图像的纹理信息提取出来,运算量大,且不同表情的纹理信息很类似,对于数据量大、人脸表情接近的人脸表情,进行分类的计算过程繁琐,算法复杂,计算时间长。
因此,现有技术还有待于改进和发展。
技术实现要素:
鉴于上述现有技术的不足之处,本发明为解决现有技术缺陷和不足,提出了一种人脸表情分类方法、装置及存储介质,对基于卷积神经网络的squeezenet网络模型的现有网络模型,重新组建了一种新的网络模型,有效解决了人脸表情识别分类问题,大大缩短了计算时间,算法复杂度大大降低,更有利于人脸表情的分类。
本发明解决技术问题所采用的技术方案如下:
一种人脸表情分类方法,用于对人脸表情的识别和分类,包括如下步骤:
a、获取不同种类人脸表情图像并设置标签;
b、将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练;
c、将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别。
作为进一步的改进技术方案,上述步骤a获取不同种类人脸表情图像并设置标签中具体包括如下步骤:
读取不同种类的人脸表情图像;
对所述不同种类的人脸表情图像设置不同的标签;
截取所述不同种类的人脸表情图像大小为224*224。
作为进一步的改进技术方案,上述步骤b将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练中的改进型squeezenet网络模型是将squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器,不同种类人脸表情图像输入squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器进行训练,以得到人脸表情图像信息集合。
作为进一步的改进技术方案,所述将squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器中,各卷积层顺序执行并设置如下:
b1、卷积层一,采用步长大小为3,卷积核为7*7,卷积后输出尺寸大小为111*111*96;
b2、最大值提取层一,输出尺寸大小为55*55*96;
b3、fire1模型,输出尺寸大小为55*55*128,其中,squeeze为16,expand1为64,expand2为64;
b4、最大值提取层二,输出尺寸大小为27*27*128;
b5、fire2模型,输出尺寸大小为27*27*256,其中,squeeze为32,expand1为128,expand2为128;
b6、最大值提取层三,输出尺寸大小为27*27*256;
b7、fire3模型,输出尺寸大小为13*13*384,其中,squeeze为48,expand1为192,expand2为192;
b8、最大值提取层四,输出尺寸大小为7*7*384;
b9、卷积层三,采用步长大小为3,卷积核为3*3,卷积后输出尺寸大小为3*3*512;
b10、全连接层一、全连接层二、全连接层三分别输出的大小均为1000。
作为进一步的改进技术方案,上述步骤c中将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别是将所述人脸表情图像的分类的图像信息集合输入到svm分类器中进行分类识别。
本发明还提供一种人脸表情分类装置,用于对人脸表情的识别和分类,所述装置包括人脸表情图像标签设置模块、人脸表情图像训练模块、人脸表情图像识别分类模块;
所述人脸表情图像标签设置模块用于获取不同种类人脸表情图像并设置标签;
所述人脸表情图像训练模块用于将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练;
所述人脸表情图像识别分类模块用于将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别。
作为进一步的改进技术方案,所述人脸表情图像标签设置模块具体用于读取不同种类的人脸表情图像;对所述不同种类的人脸表情图像设置不同的标签;截取所述不同种类的人脸表情图像大小为224*224。
作为进一步的改进技术方案,所述人脸表情图像训练模块用于将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练中具体是将不同种类人脸表情图像输入squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器进行训练,以得到人脸表情图像信息集合。
作为进一步的改进技术方案,所述人脸表情图像识别分类模块用于将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别,是将所述人脸表情图像的分类的图像信息集合输入到svm分类器中进行分类识别。
本发明还提供一种存储介质,所述存储介质存储有人脸表情分类程序,该人脸表情分类程序被处理器执行时实现上述人脸表情分类方法的步骤。
与现有技术计算过程繁琐,算法复杂,计算时间长相比较,本发明利用现有的基于卷积神经网络模型的squeezenet网络模型和alexnet网络模型的特点,将这两个网络模型的优点结合起来,构成新的网络结构,在保持squeezenet网络模型结构的基础上,修改squeezenet网络模型,重新组建了一种经改进的新的网络模型,简化了计算过程,大大缩短了计算时间,算法复杂度大大降低,更有利于人脸表情图像的识别分类。
附图说明
图1是本发明一种人脸表情分类方法优选实施例的流程图。
图2是本发明方法改进型squeezenet网络模型各卷积层执行的过程流程图。
图3是本发明一种人脸表情分类装置优选实施例的原理结构图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
目前传统的分类人脸表情图像的方法是采用机器学习方法,将人脸表情图像的纹理信息提取出来,但人脸表情丰富,人脸表情图像数据量大,表情纹理信息接近,不同人脸表情图像的纹理信息很类似,识别区分难度大,算法复杂,计算量大;而人脸表情图像接近的人脸表情图像,识别分类更是麻烦。squeezenet是在利用现有的基于卷积神经网络(convolutionalneuralnetworks,cnn)模型并以有损的方式压缩的一种小型模型的网络结构,利用少量的参数训练网络模型,实现模型的压缩。它采用firemodle模型结构,利用squeeze和expand相连接形成一种fire模块中组织卷积过滤器。而alexnet模型是将cnn的基本原理应用到了很深很宽的网络中,alexnet模型成功的用relu作为cnn的激活函数,成功解决了sigmoid在网络较深时的梯度弥散问题,进行训练时使用dropout随机忽略一部分神经元,避免了模型过拟合。最大值池化层(max-pooling)是提取规定的滤波尺寸大小内的最大值替换原滤波尺寸数值的方法,避免了平均池化(average-pooling)的模糊化效果,提升了特征的丰富性。全连接层(fully_connect_layer)可将学到的“分布式特征表示”映射到样本标记空间的作用,它能将人脸表情中相似的特征进行微调,也即迁移学习技术。在预测目标和真实目标中,保持较大模型的容量。本发明对基于卷积神经网络模型的squeezenet网络模型进行了改进,将squeezenet网络模型与alexnet网络模型进行连接形成改进型的squeezenet网络模型,改进后的squeezenet网络模型用于人脸表情分类计算,简化了计算过程,大大缩短了计算时间,算法复杂度大大降低。本发明利用squeezenet网络模型的参数量小,alexnet模型可以避免模型的过拟合的优点,提出在保持squeezenet模型结构的基础上,修改squeezenet模型,通过将不同人脸表情图像输入到新创建的模型中进行训练,得到人脸表情分类的图像信息集合,大大减少了计算量,缩短了计算时间。
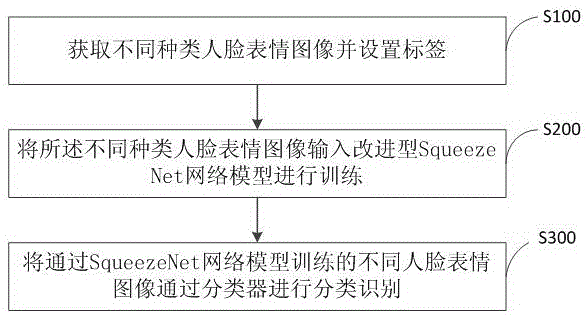
图1示出可了本发明一种人脸表情分类方法优选实施例的流程图,本发明方法优选实施例包括如下步骤:
步骤s100,获取不同种类人脸表情图像并设置标签。
读取不同种类的人脸表情图像,根据所述不同种类的人脸表情图像,设置不同的标签,并截取所述不同种类的人脸表情图像大小为224*224。
人脸表情是极为丰富的,可以分为高兴、生气、惊恐、平静、痛苦、愤怒等表情特征,相对应地为高兴、生气、惊恐、平静、痛苦、愤怒等人脸表情图像,根据不同种类的人脸表情图像,把它们归类设置为相对应的标签,例如,高兴标签为l1,生气标签为l2,惊恐标签为l3……。
步骤s200,将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练。
将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练中的改进型squeezenet网络模型是将squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器,不同种类人脸表情图像输入squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器进行训练,以得到人脸表情图像信息集合。
squeezenet网络模型是在利用现有的基于卷积神经网络(convolutionalneuralnetworks,cnn)模型并以有损的方式压缩的一种小型模型的网络结构,利用少量的参数训练网络模型,实现模型的压缩,而alexnet网络模型证明了cnn在复杂模型下的有效性,成功的用relu作为cnn的激活函数,成功解决了sigmoid在网络较深时的梯度弥散问题,训练时使用dropout随机忽略一部分神经元,避免了模型过拟合。本发明方法利用现有的基于卷积神经网络模型的squeezenet网络模型和alexnet网络模型的特点,将这两个网络模型的优点结合起来,主要是利用squeezenet网络模型的参数量小,alexnet网络模型可以避免模型的过拟合的优点,构成新的网络结构,在保持squeezenet网络模型结构的基础上,修改squeezenet网络模型,重新组建了一种经改进的新的网络模型,将所述人脸表情图像输入到改进型squeezenet网络模型中进行训练,图2示出了所述改进型的squeezenet网络模型各卷积层执行的过程流程图。各卷积层顺序执行并设置如下:
s201,卷积层一,即cov1层,采用步长大小为3,卷积核为7*7,卷积后输出尺寸大小为111*111*96;
s202,最大值池化层一,即max-pooling1输出尺寸大小为55*55*96;
s203,fire1模型,输出尺寸大小为55*55*128,其中,squeeze为16,expand1为64,expand2为64;
s204,最大值池化层二,即max-pooling2,输出尺寸大小为27*27*128;
s205,fire2模型,输出尺寸大小为27*27*256,其中,squeeze为32,expand1为128,expand2为128;
s206,最大值池化层三,即max-pooling3,输出尺寸大小为27*27*256;
s207,fire3模型,输出尺寸大小为13*13*384,其中,squeeze为48,expand1为192,expand2为192;
s208,最大值提取层四,即max-pooling4,输出尺寸大小为7*7*384;
s209,卷积层三,即conv3采用步长大小为3,卷积核为3*3,卷积后输出尺寸大小为3*3*512;
s210,全连接层一fully_connect1、全连接层二fully_connect2、全连接层三fully_connect3分别输出的大小均为1000。
经过所述改进型squeezenet网络模型训练后,得到输出数据为1*1000,不同人脸表情图像样本经过如上述改进型squeezenet网络模型训练步骤的处理后,可以得到n*1*1000输出,其中n为输入的人脸表情图像样本的数量。
步骤s300,将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别。
其中,将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别是将所述人脸表情图像的分类的图像信息集合输入到svm分类器中进行分类识别。支持向量机svm(supportvectormachine)是一个由分类超平面定义的判别分类器,也就是说给定一组带标签的训练样本,算法将会输出一个最优超平面对新样本(测试样本)进行分类,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。直接利用squeezenet网络模型计算的时间为200s,而利用本发明方法改进型squeezenet网络模型计算的时间为100s,人脸表情图像分类的时间大幅度缩短。
本发明还提供一种人脸表情分类装置,用于对人脸表情图像的识别和分类,图3示出了本发明装置优选实施例的原理结构图。所述装置包括人脸表情图像标签设置模块10、人脸表情图像训练模块20和人脸表情图像识别分类模块30。
其中,所述人脸表情图像标签设置模块10用于获取不同种类人脸表情图像并设置标签;具体用于读取不同种类的人脸表情图像;对所述不同种类的人脸表情图像设置不同的标签;截取所述不同种类的人脸表情图像大小为224*224。
所述人脸表情图像训练模块20用于将所述不同种类人脸表情图像输入改进型squeezenet网络模型进行训练;具体是将不同种类人脸表情图像输入squeezenet网络模型与alexnet网络模型相连接形成的卷积过滤器进行训练,以得到人脸表情图像信息集合。
本发明利用现有的基于卷积神经网络模型的squeezenet网络模型和alexnet网络模型的特点,将这两个网络模型的优点结合起来,主要是利用squeezenet网络模型的参数量小,alexnet网络模型可以避免模型的过拟合的优点,构成新的网络结构,在保持squeezenet网络模型结构的基础上,修改squeezenet网络模型,重新组建了一种经改进的新的网络模型,将所述人脸表情图像输入到改进型squeezenet网络模型中进行训练,改进型squeezenet网络模型与上述方法优选实施例相同,参照图2示出的改进型的squeezenet网络模型各卷积层执行的过程流程图。各卷积层顺序执行并设置如下:
s201,卷积层一,即cov1层,采用步长大小为3,卷积核为7*7,卷积后输出尺寸大小为111*111*96;
s202,最大值池化层一,即max-pooling1输出尺寸大小为55*55*96;
s203,fire1模型,输出尺寸大小为55*55*128,其中,squeeze为16,expand1为64,expand2为64;
s204,最大值池化层二,即max-pooling2,输出尺寸大小为27*27*128;
s205,fire2模型,输出尺寸大小为27*27*256,其中,squeeze为32,expand1为128,expand2为128;
s206,最大值池化层三,即max-pooling3,输出尺寸大小为27*27*256;
s207,fire3模型,输出尺寸大小为13*13*384,其中,squeeze为48,expand1为192,expand2为192;
s208,最大值提取层四,即max-pooling4,输出尺寸大小为7*7*384;
s209,卷积层三,即conv3采用步长大小为3,卷积核为3*3,卷积后输出尺寸大小为3*3*512;
s210,全连接层一fully_connect1、全连接层二fully_connect2、全连接层三fully_connect3分别输出的大小均为1000。
经过所述改进型squeezenet网络模型训练后,得到输出数据为1*1000,不同人脸表情图像样本经过如上述改进型squeezenet网络模型训练步骤的处理后,可以得到n*1*1000输出,其中n为输入的人脸表情图像样本的数量。
所述人脸表情图像识别分类模块30则用于将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别。
其中,将通过squeezenet网络模型训练的不同人脸表情图像通过分类器进行分类识别是将所述人脸表情图像的分类的图像信息集合输入到svm分类器中进行分类识别。
本发明还提供一种存储介质,所述存储介质存储有人脸表情分类程序,该人脸表情分类程序被处理器执行时实现上述人脸表情分类方法的步骤。
应当理解的是,以上所述仅为本发明的较佳实施例而已,并不足以限制本发明的技术方案,对本领域普通技术人员来说,在本发明的精神和原则之内,可以根据上述说明加以增减、替换、变换或改进,而所有这些增减、替换、变换或改进后的技术方案,都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!