一种基于用户登录行为分析的风控方法与流程
本发明涉及信息技术领域,涉及一种基于用户登录行为分析的风控方法。
背景技术:
近年来,伴随着互联网金融的风生水起;国家出台相关文件,要求加大互联网交易风险防控力度;鼓励通过大数据分析、用户行为建模等手段建立和完善交易风险检测模型。但是目前大数据风控还存在有效性差,准确性不高等问题。基于用户登录行为分析的风控方法,通过多特征多模型融合,多数据的智能处理方法能提高风险预测准确性,更符合信息发展时代风控业务的发展需求。
技术实现要素:
本发明解决的技术问题在于提供一种基于用户登录行为分析的风控方法;实现用户按键风险识别、用户登录地风险识别、密码重试风险识别和设备来源风险识别
本发明解决上述技术问题的技术方案是:
所述的方法包括用户按键风险识别、用户登录地风险识别、密码重试风险识别、设备来源风险识别四种模型;
所述用户按键风险识别是通过计算用户按键行为数据与用户历史按键行为数据的距离对用户的按键行为习惯进行分析;
所述用户登录地风险识别是通过对用户登录地的变化建立模型识别登录地风险;
所述密码重试风险识别是通过计算用户输入密码与用户历史密码的相似度来分析密码风险;
所述设备来源风险识别是通过对用户登录设备的变化建立模型识别设备来源风险;
通过融合以上四种模型得出最后的风险预警值;当四种模型中有任何2种异常时风险值为低危,有3种异常时风险值为中危,有4种异常时风险值为高危。
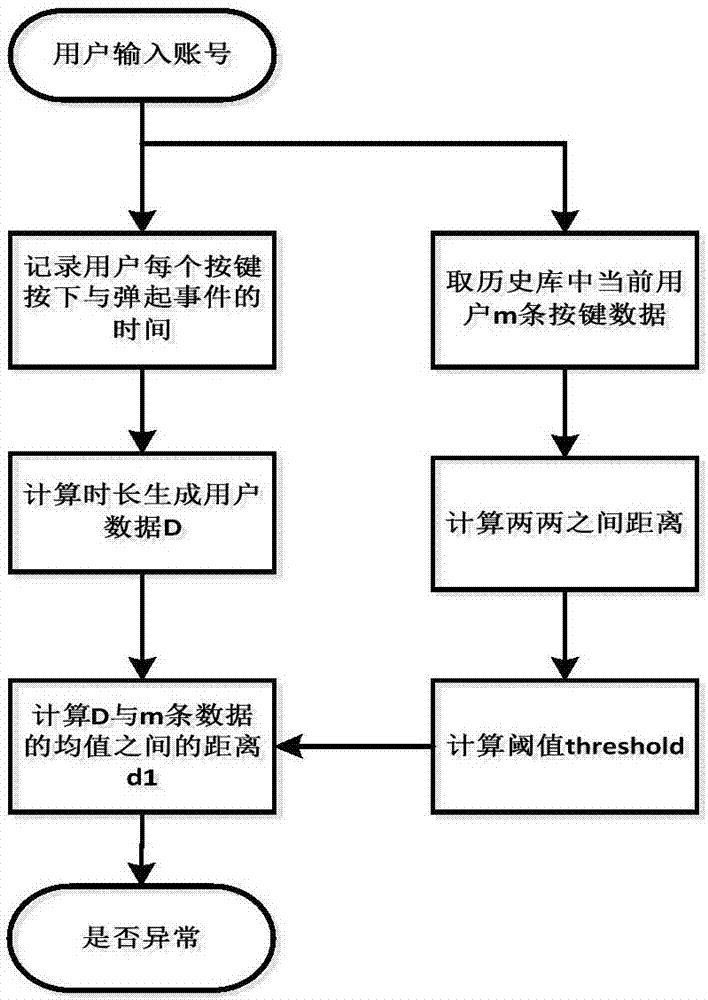
所述的用户按键风险识别包括如下步骤:
第一步,登录页面通过javascript采集用户输入用户名密码时的按键行为,第i个按键按下与弹起的时间分别为pri与upi;
第二步,计算第i个字符的按键时长prti与间隔时长upti,计算方法为prti=upi-pri,即按下与弹起的时间之差;upti=pri+1-upi,即弹起与下次按下时间之差;用户输入特征数据为d={prt1,upt1,prt2,upt2,...,uptn-1,prtn},用户输入字符集c={c1,c2,...,cn}其中cn为第n个字符;
第三步,取按键历史数据库中最近的m条按键记录;
第四步,计算m条数据中两两之间的欧式距离,总共m(m-1)/2个距离;
第五步,根据距离进行排序,取m(m-1)/6处的距离作为阈值,记为threshold;
第六步,对m条数据计算均值;
第七步,计算用户输入的键盘数据与做均值后的数据的欧式距离d1;
第八步,比较阈值,如果d1>threshold则此次登录设置为异常,否则无异常。
所述的用户登录地风险识别包括如下步骤:
第一步,服务端后台获取用户的ip地址;
第二步,根据ip地址找到地理位置;
第三步,在登录地历史数据中取该账户的历史登录地数据;
第四步,计算当前登录地与历史登录地数据的距离d2,其中计算公式如下:
第五步,如果d2<0.5则此次登录设置为异常,否则无异常。
所述的密码重试风险识别包括如下步骤:
第一步,服务端后台获取用户密码;
第二步,在用户密码历史数据中取出该账号的历史密码数据;
第三步,使用词袋模型将密码数据向量化,具体操作如下:选取历史数据中密码以及现有密码中的所有字符作为词袋b={c1,c2,c3,...,cj,...,cn},则第i个密码可向量表示为(bi1,bi2,bi3,...,bij,...,bin),其中bij表示第i个密码中是否存在cj字符,如果存在则第j位向量值为1否则为0;
第三步,分别计算用户输入密码与历史密码的相似度s={s1,s2,...,si,...,sm},其计算公式如下:
第四步,计算风险,规则为只要存在s中有一个si>0.8,则此次登录无异常,否则有异常。
所述的设备来源风险识别包括如下步骤:
第一步,服务端后台获取用户的登录设备,设备包括pc浏览器,m站,app,微信,其他;
第二步,在登录设备历史数据中取该账户的历史登录设备数据;
第三步,计算当前登录设备与历史设备数据的距离d3,其中计算公式如下:
第四步,如果d3<0.5则此次登录设置为异常,否则无异常。
本发明通过用户潜在的行为特征融合了四种模型对用户登录行为进行分析,提高了预测的准确性。
附图说明
下面结合附图对本发明进一步说明:
图1是本发明风险识别框架图;
图2是本发明用户按键风险识别流程图;
图3是本发明用户登录地风险识别流程图;
图4是本发明密码重试风险识别流程图;
图5是本发明设备来源风险识别流程图。
具体实施方式
如图1-5所示,本发明包括用户按键风险识别、用户登录地风险识别、密码重试风险识别、设备来源风险识别四种模型。用户按键风险识别是通过计算用户按键行为数据与用户历史按键行为数据的距离对用户的按键行为习惯进行分析;用户登录地风险识别是通过对用户登录地的变化建立模型识别登录地风险;密码重试风险识别是通过计算用户输入密码与用户历史密码的相似度来分析密码风险;设备来源风险识别是通过对用户登录设备的变化建立模型识别设备来源风险。通过融合以上四种模型得出最后的风险预警值。
如图2所示所述的用户按键风险识别是通过计算用户按键行为数据与用户历史按键行为数据的距离对用户的按键行为习惯进行分析,包括如下步骤:
第一步,登录页面通过javascript采集用户输入用户名密码时的按键行为,监听用户名与密码框中的keydown与keyup事件并记录时间;第i个按键按下与弹起的时间分别为pri与upi;
第二步,计算第i个字符的按键时长prti与间隔时长upti,计算方法为prti=upi-pri即按下与弹起的时间之差,upti=pri+1-upi即弹起与下次按下时间之差,用户输入特征数据为d={prt1,upt1,prt2,upt2,...,uptn-1,prtn},用户输入字符集c={c1,c2,...,cn}其中cn为第n个字符;
第三步,取按键历史数据库中最近的m条按键记录;
第四步,计算n条数据中两两之间的欧式距离,总共m(m-1)/2个距离;
第五步,根据距离进行排序,取m(m-1)/6处的距离作为阈值,记为threshold;
第六步,对m条数据计算算数均值
为第i个数据的第n-1个字符的弹起时间,
第七步,计算用户输入的键盘数据与做均值后的数据的欧式距离d1;
第八步,比较阈值,如果d1>threshold则此次登录设置为异常,否则无异常;
如图3所示所述的用户登录地风险识别是通过对用户登录地的变化频率建立模型识别登录地风险,包括如下步骤:
第一步,服务端后台获取用户的ip地址,具体先使用消息头中的中的
request.getheader(″x-forwarded-for″)获取,如果不为空,用逗号分隔后获取第一个作为ip地址,否则使用request.getheader(″x-real-ip″)获取,如果不为空则是当前获取ip,否则使用request.getremoteaddr()获取;
第二步,根据ip地址找到地理位置,在ip与地理位置对应表中查找;
第三步,在登录地历史数据中取该账户的历史登录地数据;
第四步,计算当前登录地与历史登录地数据的距离d2,其中计算公式如下:
第五步,如果d2<0.5则此次登录设置为异常,否则无异常。
如图4所示所述的密码重试风险识别是通过计算用户输入密码与用户历史密码的相似度来分析密码风险,包括如下步骤:
第一步,服务端后台获取用户密码;
第二步,在用户密码历史数据中取出该账号的历史密码数据;
第三步,使用词袋模型将密码数据向量化,具体操作如下:选取历史数据中密码以及现有密码中的所有字符作为词袋b={c1,c2,c3,...,cj,...,cm},则第i个密码可向量表示为(bi1,bi2,bi3,...,bij,...,bim),其中bij表示第i个密码中是否存在cj字符,如果存在则第j位向量值为1否则为0;
第三步,分别计算用户输入密码与历史密码的相似度s={s1,s2,...,si,...,sn},其计算公式如下:
第四步,计算风险,规则为只要存在s中有一个si>0.8,则此次登录无异常,否则有异常。
如图5所示所述的设备来源风险识别是通过对用户登录设备的变化频率建立模型识别设备来源风险,包括如下步骤:
第一步,服务端后台通过request.getheader(″user-agent″)获取用户的登录设备,设备包括pc浏览器,m站,app,微信,其他;
第二步,在登录设备历史数据中取该账户的历史登录设备数据;
第三步,计算当前登录设备与历史设备数据的距离d3,其中计算公式如下:
第四步,如果d3<0.5则此次登录设置为异常,否则无异常。
所述的通过融合以上四种模型得出最后的风险预警值,其特征如下:
四种模型中有任何2种异常时风险值为低危,有3种异常时风险值为中危,有4种异常时风险值为高危。
- 还没有人留言评论。精彩留言会获得点赞!