一种基于全覆盖粒计算的K‑medoids文本聚类方法与流程
本发明涉及全覆盖粒计算和文本挖掘技术,特别是涉及全覆盖粒计算的粒化以及文本聚类的方法。
背景技术:
互联网快速发展带来的信息过载、缺乏结构性等问题,使得人们很难在海量的信息中快速、准确地获取用户感兴趣的、潜在有用的内容,依靠手工对这些信息进行处理是不可能的。目前,绝大多数的网络信息都表现为文本形式,文本数据作为非结构化的数据,不像结构化的数据便于处理,因此大大降低了文本数据的利用率,而且大多数传统的信息检索技术不能处理海量的文本数据。数据挖掘是一门从大量有效数据中挖掘隐藏信息的有效技术,文本挖掘则是对文本信息进行数据挖掘的过程,随着文本数据的增长,文本挖掘成为数据挖掘领域中一个重要的研究方向,文本聚类是文本挖掘的预处理步骤,是文本进一步挖掘与分析的关键环节。文本聚类主要是对样本文档集计算相似性,并根据相似性程度将样本划分成若干类簇,同类簇的文档间相似性较大,不同内簇间的文档相似性则较小。
文本聚类一直是国内外研究学者关注的热点、难点问题,研究已经取得巨大的成果,但是还是存在一系列亟待解决的关键问题,如样本的词向量空间维度过大,聚类中心的随机选取问题和计算复杂度大等。如何对数据降维,提高聚类质量,降低计算复杂度等都需要我们做进一步的研究。
技术实现要素:
本发明为了解决传统聚类方法随机选取聚类中心和文本聚类方法准确率较低的问题,提供一种基于全覆盖粒计算的k-medoids文本聚类方法,该方法包括以下步骤:
1.对文本进行预处理,包括中文分词,去停用词;
2.对文本进行特征提取,设置高频词与低频词阈值,滤除区分度不够的高频词和代表性不强的低频词,然后利用tf-idf算法建立词向量空间模型;
3.利用singlepass算法对文档聚类,得到粗聚类集c1,c2,..cp,构成全覆盖计算c={ci:i=1,…,p},按照全覆盖粒计算的相关定义分别计算粒度重要性和平均粒度重要性,选择
4.按照公式(1)计算s中每个粒子的中心,任意两个中心粒子间的欧式距离记为矩阵d;
5.选择包含更多粒子对应的中心作为第一个聚类中心v1,选择距v1最远的粒子中对应的中心作为第二个聚类中心v2;对于s中剩余粒子,根据矩阵d分别求出其中心到v1,v2距离为di1,di2,取di=min(di1,di2),d=max(di)对应的粒子中心为vi,依此类推计算vk,此时找到k个初始聚类中心
6.对于任意xi∈u,首先寻找与其最近的类心vm(m=1,2,...k),此时样本分为k类;
7.选每个类簇中与该簇其他对象距离之和最小的对象作为新的聚类中心,在k类中用新中心代替原始中心;
8.重新分配每个对象到距离最近的中心点,获得聚类结果;
9.计算所有对象到其类簇中心的距离之和,如果该值不变或者达到最大迭代次数则算法结束,否则转到第8步。
所述的文本特征提取,具体包括以下操作:首先滤除区分度不够的高频词和代表性不强的低频词,即假设词j的频率为m,m1为低频词频率,m2为高频词频率,若m1<m<m2则保留该词,否则剔除,达到降维的目的。
所述的tf-idf算法,具体包括以下操作:
xij表示第i篇文档中词j出现的频率,|xi|表示该篇文档中所有词的词频总数,n表示样本总数,|xj|表示词j包含的样本总数,n表示文档所有词的数量。
所述的single-pass聚类,具体包括以下操作:
1)从文档集n中输入第一篇文档d1作为第一类中的中心;
2)输入第二篇文档与第一篇文档做相似性处理,得到相似结果θ,若θ>σ,则第二篇分到第一类中并重新计算中心,否则第二篇作为新的一类;
3)输入第i篇文档,分别与已有类别中的中心文档做相似性处理,得到与di相似度最大的类别m且记录相似结果θ,若θ>σ,则di分配到类别m中并重新计算中心,否则成为新的一类;
4)重复第三步,直至最后一篇文档分配类别,即整个聚类过程结束。
所述的全覆盖粒计算理论的粒度重要性概念,具体包括以下操作:
设
centerc(x)=∩{nc(x)|x∈nc(x),nc(x)∈gx}
center(c)={centerc(x)|x∈u}
其中,|centerp(x)|表示centerp(x)的基数。
基于上述全覆盖粒计算模型的相关基础概念,定义全覆盖平均粒度重要性,设c={ci:1,...,m}是非空论域u上的一个全覆盖,定义平均粒度重要性为:
全覆盖粒计算是信息处理的一种新概念和计算范式,主要通过建立合适的粒度来寻找解决问题的有效方法,降低问题的求解难度。全覆盖粒计算的基本问题归纳为两个方面,即粒化和粒的计算。粒化是求解空间的一个构造性过程,处理粒度的形成、粗细、表示和语义解释,粒的计算主要是指如何有效的利用粒度去解决复杂问题。
本发明引入全覆盖粒计算模型,对文档集进行合理的粒化,利用粒的计算解决文本聚类问题。
具体的文档粒化对应关系如表1所示:
所述的密度算法和最大最小距离算法,具体包括以下操作:
1).n个样本分为c1,c2,..,cp共p类(p>k),计算每类的中心(z1,z2,...,zp)并选取c1,c2,..,cp中包含样本数最多的类的中心作为第一个聚类中心v1;
2).选取距离第一个聚类中心v1最远的中心作为第二个聚类中心v2;
3).计算其余中心与v1、v2之间的距离,并求出它们中的最小值,即:
dij=||zi-vj||,j=1,2
di=min(di1,di2),i=1,2,...p
4).若dl=max(di)则相应的中心zl作为第三个聚类中心v3;
5).依此类推若存在k个聚类中心,计算各中心到各个聚类中心的距离dij,并算出:
dk=max(min(di1,di2,...,di(k-1))),i=1,2,...p
zk为第k个聚类中心;
所述的k-medoids算法,具体包括以下操作:
1)从n个样本中随机选取k个样本作为初始聚类中心;
2)针对剩余的每一个样本,分别计算该样本到k个初始聚类中心的距离,该样本并入到距离最小的类簇中,所有样本计算完毕后n个样本被分为k类;
3)重新计算每类的聚类中心,计算每类中的样本中心,距离该中心最近的样本成为新的聚类中心;
4)反复重复上述第2)、3)步骤,直到所有的聚类中心不变时算法结束。其中,更新的聚类中心公示:
本发明基于全覆盖粒计算的k-medoids文本聚类方法,通过single-pass方法以及全覆盖粒计算的相关理论,找到有效的初始聚类中心,降低聚类方法的复杂度,提高聚类方法的准确率。
附图说明
图1为本发明整体示意图;
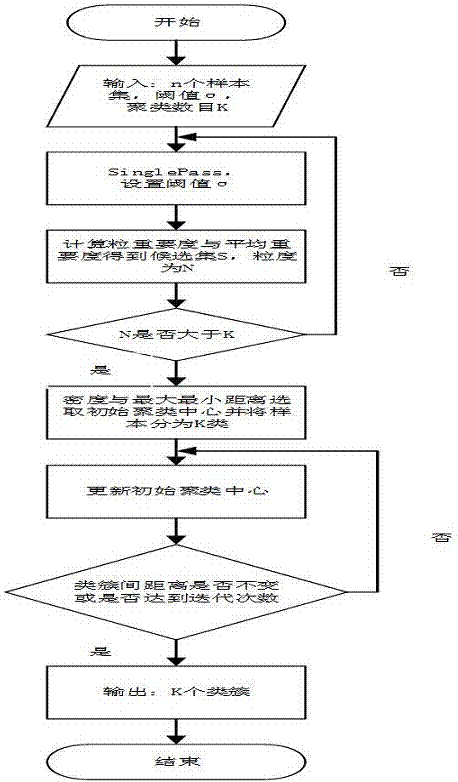
图2为本发明中基于全覆盖粒计算的k-medoids文本聚类方法的流程图。
具体实施方式
为更进一步阐述本发明为实现预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明的具体实施方式、特征及其功效,详细说明如后。
如图1所示,本发明的整体流程详述如下:
步骤1:使用jieba分词对中文文本分词,对“哈工大停用词词库”、“四川大学机器学习智能实验室停用词库”、百度停用词表“等各种停用词表整理去重后提取新的中文词词表。
步骤2:对步骤1去停用词后的分词结果进行tf-idf特征提取。tf-idf是一种统计加权方法,公式为
xij表示第i篇文档中词j出现的频率,|xi|表示文档i中所有词的词频总数,n表示样本总数,|xj|表示词j包含的样本总数,n表示文档所有词的数量。
这样就得到由样本的所有特征词组成的“样本—特征”矩阵。
步骤3:对步骤2的“样本—特征”矩阵进行聚类,首先利用singles-pass粗聚类,接着利用全覆盖粒计算理论的粒度重要性概念计算初始聚类中心候选集,然后基于密度和最大最小距离算法计算初始聚类中心,最后利用k-medoids算法进行文本聚类。
步骤4:通过步骤3得到所有的聚类结果,利用聚类精度检测聚类效果。使用查全率(recall)、查准率(precision)以及值三个指标来衡量聚类的效果,具体公式
如下:
|ai∩bi|表示聚类类别ai中包含对应人工类别bi的文本个数,|ai|表示聚类类别ai包含的样本个数,|bi|表示人工类别bi包含的样本个数。
在该实施例中,利用本发明的方法分别对1400篇复旦语料库。语料库的具体分布和统计结果如下表2和表3:
表2:样本类别信息
表3:样本统计信息
表2中分词结果经过简单的降维后得到特征词集,样本集的“文档—特征”矩阵分别为1400×172324。
表3实验对比结果
根据表3的实验对比结果,本文算法的准确率、召回率与f值均高于k-medoids算法,表明聚类结果受初始聚类中心选取的影响,且k-medoids算法的正确率波动范围较大,易陷入局部最优。本文算法先是采用single-pass算法对文本集粗聚类,相关的文本集分别聚成簇,根据初始聚类中心一定在形成的大簇中的原则,利用全覆盖粒度重要性和平均粒度重要性选出初始聚类中心,也克服了初始聚类中心容易位于同一类簇的缺陷,取得较好的聚类结果。
- 还没有人留言评论。精彩留言会获得点赞!