一种时序数据访问系统及方法与流程
本发明涉及数据访问技术领域,特别涉及一种时序数据访问系统及方法。
背景技术:
采用开源的OpenTSDB可支持时序数据的秒级存储,支持数据永久存储,即保存的数据不会主动删除,并且原始数据会一直保存。支持从大规模的集群中获取相应metrics进行存储、索引以及服务,支持数据查询时的图形化界面展示。但是,使用开源OpenTSDB进行时序数据查询时,除过图形化界面展示数据点之外,可通过URL接口进行数据访问,但是通过此种方式用户可以查询到所有存储在OpenTSDB时序数据库中的数据,不保证所有时序数据的安全性。
技术实现要素:
本发明提供了一种时序数据访问系统,解决了现有技术的技术问题。
本发明解决上述技术问题的技术方案如下:
一种时序数据访问系统,包括:时序数据服务引擎和数据仓库,所述时序数据服务引擎包括:接口配置模块、写数据模块和读数据模块;
所述写数据模块用于接收数据源通过Kafka集群发送的订阅消息,通过自身的Flume模块将所述订阅消息中包括的源数据写入所述数据仓库;
所述接口配置模块用于在所述源数据写入所述数据仓库之后,根据所述源数据在所述数据仓库中的URL地址信息和数据参数进行接口配置、接口测试和接口发布,生成接口文档,将所述接口文档存储在缓存数据库中,同时根据所述接口文档生成UID源数据信息,将所述UID源数据信息作为所述接口文档的主键,还用于接收用户终端发送的下载请求,根据所述下载请求向所述用户终端返回所述接口文档中的所述URL地址信息和所述UID源数据信息;
所述读数据模块用于接收所述用户终端发送查询请求,根据所述查询请求中包括的所述UID源数据信息从所述缓存数据库中获取所述接口文档中包括的所述数据参数,根据所述数据参数和所述查询请求中包括的所述URL地址信息得到查询数据地址,根据所述查询数据地址从所述数据仓库中获取所述源数据并返回给所述用户终端。
本发明的有益效果是:通过时序数据服务引擎只需界面配置需要访问的接口,无需开发新的接口,同时保证时序数据的安全性,用户可以通过该接口完成对源数据实时获取。在时序数据的存储过程中,数据源可由kafka集群传递到Flume,进而落地到数据库中,在存储过程中实现Flume的负载均衡,从而达到高效的数据采集。在时序数据服务引擎中,数据的存储和获取实现分离,在大数据进行实时数据存储和访问操作时,更高效地实现数据的传递。
在上述技术方案的基础上,本发明还可以做如下改进。
优选地,所述接口配置模块用于在所述源数据写入所述数据仓库之后,根据所述源数据在所述数据仓库中的存储地址和数据参数进行接口配置,得到已配置的接口,通过访问所述数据仓库对所述已配置的接口进行接口测试,测试通过后,根据所述数据参数对所述已配置的接口进行接口发布,生成接口文档。
优选地,所述接口配置模块还用于接收所述用户终端发送接口查看请求,根据所述接口查看请求向所述用户终端发送接口详细内容,还用于接收所述用户终端发送的日志查看请求,根据所述日志查看请求向所述用户终端发送日志内容。
优选地,所述接口配置模块还用于在对接收到所述用户终端发送的请求作出响应之前,对所述用户终端进行权限验证,验证通过后根据所述请求作出响应。
优选地,所述写数据模块还用于通过Zookeeper服务器给所述Flume模块的每个节点设置监视器,当每个节点的状态发生改变时,触发对应的监视器,向引起每个节点的状态发生改变的客户端发送通知。
优选地,所述写数据模块还用于通过Zookeeper服务器给所述Flume模块开启两个控制进程,当其中一个控制进程宕机时,自动切换到另一个控制进程。
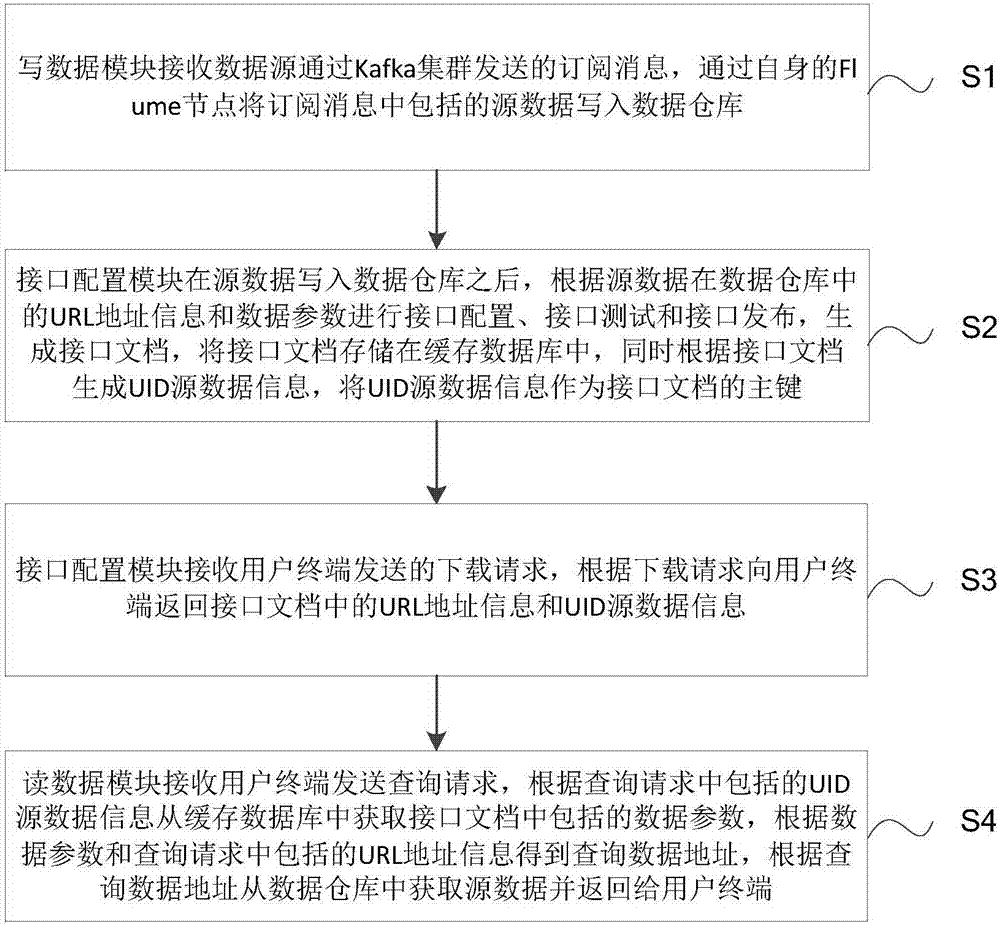
一种时序数据访问方法,包括:
S1、写数据模块接收数据源通过Kafka集群发送的订阅消息,通过自身的Flume模块将所述订阅消息中包括的源数据写入所述数据仓库;
S2、接口配置模块在所述源数据写入所述数据仓库之后,根据所述源数据在所述数据仓库中的URL地址信息和数据参数进行接口配置、接口测试和接口发布,生成接口文档,将所述接口文档存储在缓存数据库中,同时根据所述接口文档生成UID源数据信息,将所述UID源数据信息作为所述接口文档的主键;
S3、接口配置模块接收用户终端发送的下载请求,根据所述下载请求向所述用户终端返回所述接口文档中的所述URL地址信息和所述UID源数据信息;
S4、读数据模块接收所述用户终端发送查询请求,根据所述查询请求中包括的所述UID源数据信息从所述缓存数据库中获取所述接口文档中包括的所述数据参数,根据所述数据参数和所述查询请求中包括的所述URL地址信息得到查询数据地址,根据所述查询数据地址从所述数据仓库中获取所述源数据并返回给所述用户终端。
优选地,步骤S2之后,步骤S3之前,还包括:对所述用户终端进行权限验证,验证通过后执行步骤S3。
附图说明
图1为本发明实施例提供的一种时序数据访问系统的结构示意图;
图2为本发明另一实施例提供的一种时序数据访问方法的流程示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
如图1所示,一种时序数据访问系统,包括:时序数据服务引擎1和数据仓库2,时序数据服务引擎1包括:接口配置模块11、写数据模块12和读数据模块13;
写数据模块12用于接收数据源通过Kafka集群发送的订阅消息,通过自身的Flume模块将订阅消息中包括的源数据写入数据仓库2;
接口配置模块11用于在源数据写入数据仓库2之后,根据源数据在数据仓库2中的URL地址信息和数据参数进行接口配置、接口测试和接口发布,生成接口文档,将接口文档存储在缓存数据库中,同时根据接口文档生成UID源数据信息,将UID源数据信息作为接口文档的主键,还用于接收用户终端发送的下载请求,根据下载请求向用户终端返回接口文档中的URL地址信息和UID源数据信息;
读数据模块13用于接收用户终端发送查询请求,根据查询请求中包括的UID源数据信息从缓存数据库中获取接口文档中包括的数据参数,根据数据参数和查询请求中包括的URL地址信息得到查询数据地址,根据查询数据地址从数据仓库2中获取源数据并返回给用户终端。
通过时序数据服务引擎只需界面配置需要访问的接口,无需开发新的接口,同时保证时序数据的安全性,用户可以通过该接口完成对源数据实时获取。在时序数据的存储过程中,数据源可由kafka集群传递到Flume,进而落地到数据库中,在存储过程中实现Flume的负载均衡,从而达到高效的数据采集。在时序数据服务引擎中,数据的存储和获取实现分离,在大数据进行实时数据存储和访问操作时,更高效地实现数据的传递。
当用户数据访问量过高时,时序数据服务引擎在数据存储和查询负载上支持弹性伸缩,即结合Haproxy、Nginx以及keepalived进行数据访问负载,当某一台查询引擎出现宕机后自动切换到另一台查询引擎。
优选地,接口配置模块11用于在源数据写入数据仓库之后,根据源数据在数据仓库中的存储地址和数据参数进行接口配置,得到已配置的接口,通过访问数据仓库对已配置的接口进行接口测试,测试通过后,根据数据参数对已配置的接口进行接口发布,生成接口文档。
优选地,接口配置模块11还用于接收用户终端发送接口查看请求,根据接口查看请求向用户终端发送接口详细内容,还用于接收用户终端发送的日志查看请求,根据日志查看请求向用户终端发送日志内容。
优选地,接口配置模块11还用于在对接收到用户终端发送的请求作出响应之前,对用户终端进行权限验证,验证通过后根据请求作出响应。
优选地,写数据模块12还用于通过Zookeeper服务器给Flume模块的每个节点设置监视器,当每个节点的状态发生改变时,触发对应的监视器,向引起每个节点的状态发生改变的客户端发送通知。
优选地,写数据模块12还用于通过Zookeeper服务器给Flume模块开启两个控制进程,当其中一个控制进程宕机时,自动切换到另一控制进程。
数据存储时通过Flume进行数据存储负载,当Controller在启动时会在Zookeeper需要管理的Topic目录下创建相应的临时节点,表明需要在该节点上启动一定数量的对应进程,然后计算需要启动的进程数量。而其他的节点会监控hosts数量,并且计算出需要启动的进程,并且对当前的进程数量进行调整,从而实现数据存储的负载均衡。
初始时,Flume Controller 1(以下简称FC1)为active进程。当FC1宕机时,其所创建的相应临时节点将会被超时删除,同时FC2将收到active节点被删除的通知。随后,FC2将重新创建active节点,并接管成为active进程的功能。在FC2接管成为active进程时,将重新拉起FC1进程,从而实现控制进程间的负载切换。
如图2所示,一种时序数据访问方法,包括:
S1、写数据模块接收数据源通过Kafka集群发送的订阅消息,通过自身的Flume节点将订阅消息中包括的源数据写入数据仓库;
S2、接口配置模块在源数据写入数据仓库之后,根据源数据在数据仓库中的URL地址信息和数据参数进行接口配置、接口测试和接口发布,生成接口文档,将接口文档存储在缓存数据库中,同时根据接口文档生成UID源数据信息,将UID源数据信息作为接口文档的主键;
S3、接口配置模块接收用户终端发送的下载请求,根据下载请求向用户终端返回接口文档中的URL地址信息和UID源数据信息;
S4、读数据模块接收用户终端发送查询请求,根据查询请求中包括的UID源数据信息从缓存数据库中获取接口文档中包括的数据参数,根据数据参数和查询请求中包括的URL地址信息得到查询数据地址,根据查询数据地址从数据仓库中获取源数据并返回给用户终端。
优选地,步骤S2之后,步骤S3之前,还包括:对用户终端进行权限验证,验证通过后执行步骤S3。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!