一种时序数据的压缩存储方法、电子设备及存储介质与流程
本发明涉及时序数据存储技术,尤其涉及一种时序数据的压缩存储方法、电子设备及存储介质。
背景技术:
在工业监控领域,所有需要对运行设备进行监控、控制的系统都可以定义为工业监控系统,这里面就包括火电厂厂级监控系统,在这类应用领域中,需要处理的测点非常多;假如一个火电厂监控系统需要处理的测点超过10000点,并且这些测点的变化周期在1s内,那么需要将超过10000点的时序数据在1s内存到实时数据库里面,其存储量非常巨大,会占用大量的磁盘空间,甚至还会降低数据的访问速度。因此,各个数据库厂家大都会开发自己的数据压缩算法,以对时序数据进行压缩。
开源数据库OpentsDB是基于HBase存储时序数据的开源数据库,是HBase的应用。其采用按指标建模的方式,即一个数据点由以下四部分组成:metricname,即指标的名称;value,即该指标的值;timestamp,即时间戳或者数据生成时间;tags,即一个或者多个标签,每个标签tag包括标签键tagKey和对应的标签值tagValue。
例如,在监控场景中,一个测点或者说监控指标可以这样定义:
名称name:cpu.server
标签tags:host=10.0.3.93cpu=1
那么这个测点的名称就表示对服务器的cpu使用情况进行监控,引入两个标签,用来描述该监控是对哪台服务器上的哪个核进行监控。
这个测点的一个时序数据如下:
测点名称name:cpu.server
测点标签tags:host=10.0.3.93cpu=1
时间戳timestamp:3660
值value:0.5
那么这个时序数据表示,地址为10.0.3.93的服务器上的编号为1的核,其在1小时01分的占用率为50%。
那么在将时序数据写入到存储文件时,以Key-Value的形式存储,其中Key采用rowKey+column name(列名)的形式,其行键rowKey可采用metric name+timestamp+tags的形式。其中,OpentsDB为了缩短rowKey,采用的策略就是为metric name、tagKey及tagValue均分配一个唯一标识UID(UniqueID),其中每个UID均默认为3个字节的固定长度。那么原先用String存储的metric、tagKey、tagValue现在均可以用3个字节的字节数组来代替,大大缩短了rowKey长度,节省存储空间。
时序数据有其自身的变化特征,例如趋势性或者周期性,对于工业监控产生的时序数据,由于其采集频率高并且采集量大,其在某些时间段内可能会具有线性变化的趋势即该时间段内时序数据的变化率接近一个常量,例如,处于较短时间段内的时序数据,其变化率可能会接近0,即变化十分缓慢,甚至保持不变,比如说一台服务器在1小时00分到1小时01分的这1分钟内,其CPU占用率可能就维持在50%左右。然而,OpentsDB未能利用时序数据的变化特征来进一步地提高压缩比。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种时序数据的压缩存储方法、电子设备及存储介质,通过旋转门算法来进行时序数据的线性拟合,是一种有损压缩,减少了时序数据的保存量,另外再合并压缩后的时序数据,以减少存储文件中Key-Value的个数,节省存储空间。
本发明所提供的方法,采用如下技术方案实现:
一种时序数据的压缩存储方法,包括以下步骤:
分配步骤:为测点的名称、标签键及标签值均分配一个唯一标识UID,每个UID的长度均在2-8个字节的范围内;
建表步骤:建立测点索引表,用于记录测点的名称、标签键及标签值与UID的映射关系,包括正向映射及反向映射;建立测点数据表,用于记录测点的时序数据,在测点数据表中,将同一测点属于同一时间周期的时序数据记录在同一行;在测点数据表中,每一时序数据行的rowKey包括两部分,其中之一是时序数据所属测点的UID信息,其中另一为时间标识,所述时间标识为该行所属时间周期的起始时间;
合并步骤:对测点数据表中属于同一行的时序数据,采用旋转门算法对该行的时序数据进行压缩,并且将压缩后的时序数据合并成一条记录;
存储步骤:将测点索引表及测点数据表以Key-Value的形式存储于存储文件。
进一步地,在合并步骤中,对属于同一行的时序数据,取这些时序数据的相邻差值的绝对值的平均值,作为该行的压缩阈值,并且所述旋转门算法通过以下步骤对该行的时序数据进行压缩:
按照数据生成时间的先后顺序压缩该行的时序数据,判断当前的待压缩时序数据是否为该行的第一个时序数据,如果是,那么保存该时序数据,并且以该时序数据作为压缩起点;
根据所述压缩阈值,计算出当前压缩起点的上轴点和下轴点,对于当前的待压缩时序数据,计算出该时序数据与所述上轴点的斜率K11,如果该时序数据的前一时序数据为当前的压缩起点,那么将K11作为当前的待压缩时序数据的上斜率,否则,若前一时序数据的上斜率为K10,取K11与K10中的较大值作为当前的待压缩时序数据的上斜率;对于当前的待压缩时序数据,计算出该时序数据与所述下轴点的斜率K21,如果该时序数据的前一时序数据为当前的压缩起点,那么将K21作为当前的待压缩时序数据的下斜率,否则,若前一时序数据的下斜率为K20,取K21与K20中的较小值作为当前的待压缩时序数据的下斜率;
如果当前的待压缩时序数据的上斜率大于或等于其下斜率,那么保存前一时序数据,并且以该时序数据作为新的压缩起点,继续压缩该行的时序数据,直至该行所有的时序数据压缩完毕。
进一步地,在测点数据表中,其时序数据行的时间周期的长度取为1小时,并且rowKey中的时间标识为整点时间。
进一步地,每个UID的长度均为3个字节。
进一步地,在测点索引表中,包括两个列族,其中一个列族,其包括三种类型的列成员,分别表示测点的名称、标签键及标签值;另一个列族,其包括三种类型的列成员,分别表示测点的名称、标签键及标签值这三者所对应的UID;在测点索引表中,其数据行的rowKey有6种类型,分别为测点的名称、标签键、标签值以及这三者所对应的UID。
本发明所提供的电子设备,采用如下技术方案实现:
一种电子设备,包括存储器、处理器以及存储在存储器上并且可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现上述的时序数据的压缩存储方法。
本发明所提供的存储介质,采用如下技术方案实现:
一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现上述的时序数据的压缩存储方法。
相比现有技术,本发明的有益效果在于:
本发明所提供的时序数据的压缩存储方法、电子设备及存储介质,采用旋转门算法,对测点数据表中属于同一行的时序数据进行压缩,旋转门算法是一种线性拟合算法,属于有损压缩,能够减少时序数据的保存量,节省存储空间,并且将该行压缩后的时序数据合并成一条记录,即把一行多列的时序数据合并成一列,以减少存储文件中Key-Value的个数,节省存储空间。
附图说明
图1为本发明实施例一的时序数据的压缩存储方法的流程图;
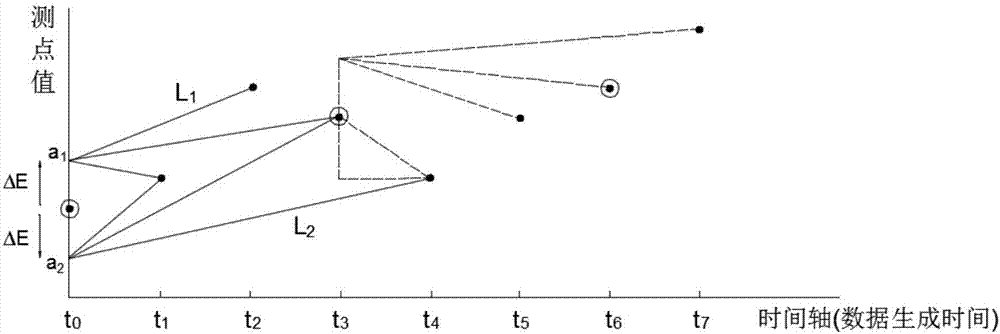
图2为图1所示方法中的旋转门算法的原理图;
图3为执行合并步骤前的测点数据表的表结构示意图;
图4为图3所示测点数据表经过旋转门算法压缩后的表结构示意图;
图5为图4所示测点数据表的存储结构示意图;
图6为将图4所示测点数据表的时序数据行合并成一条记录后的表结构示意图;
图7为图6所示测点数据表的存储结构示意图;
图8为本发明实施例一所采用的测点索引表的表结构示意图;
图9为图7所示测点数据表采用UID映射后的存储结构示意图。
具体实施方式
下面,结合附图以及具体实施方式,对本发明做进一步描述,需要说明的是,在不相冲突的前提下,以下描述的各实施例之间或各技术特征之间可以任意组合形成新的实施例。
实施例一
如图1所示,为本发明实施例一的时序数据的压缩存储方法的流程图,该方法包括以下步骤:
S1、分配步骤:为测点的名称、标签键及标签值均分配一个唯一标识UID,每个UID的长度均在2-8个字节的范围内;
S2、建表步骤:建立测点索引表,用于记录测点的名称、标签键及标签值与UID的映射关系,包括正向映射及反向映射;建立测点数据表,用于记录测点的时序数据,在测点数据表中,将同一测点属于同一时间周期的时序数据记录在同一行;在测点数据表中,每一时序数据行的rowKey包括两部分,其中之一是时序数据所属测点的UID信息,其中另一为时间标识,该时间标识为该行所属时间周期的起始时间;
S3、合并步骤,包括:
S31、对测点数据表中属于同一行的时序数据,取这些时序数据的相邻差值的绝对值的平均值,作为该行的压缩阈值,并且采用旋转门算法对该行的时序数据进行压缩,其中该旋转门算法通过以下步骤对该行的时序数据进行压缩:
S311、按照数据生成时间的先后顺序压缩该行的时序数据,判断当前的待压缩时序数据是否为该行的第一个时序数据,如果是,执行S312,否则执行S313;在这里需要说明的是,在本实施例中,每一时序数据行的压缩阈值是根据该行本身的数据波动变化来自动调整的,假如某个时间周期内(即某一时序数据行),时序数据的变化比较快,那么根据本实施例的压缩阈值的计算方法,该时间周期内的计算出的压缩阈值会比较大,能够提高压缩比,如果该时间周期内的时序数据变化比较慢,那么计算出的压缩阈值会比较小,能够提高压缩精度;
S312、保存该时序数据,并且以该时序数据作为压缩起点,并执行S313;在这里需要说明的是,因为当前的待压缩时序数据已经被选作为压缩起点,所以下一个待压缩时序数据,才是S313中的“当前的待压缩时序数据”;
S313、根据压缩阈值,计算出当前压缩起点的上轴点和下轴点,对于当前的待压缩时序数据,计算出该时序数据与上轴点的斜率K11,如果该时序数据的前一时序数据为当前的压缩起点,那么将K11作为当前的待压缩时序数据的上斜率,否则,若前一时序数据的上斜率为K10,取K11与K10中的较大值作为当前的待压缩时序数据的上斜率;对于当前的待压缩时序数据,计算出该时序数据与下轴点的斜率K21,如果该时序数据的前一时序数据为当前的压缩起点,那么将K21作为当前的待压缩时序数据的下斜率,否则,若前一时序数据的下斜率为K20,取K21与K20中的较小值作为当前的待压缩时序数据的下斜率;
S314、如果当前的待压缩时序数据的上斜率大于或等于其下斜率,那么执行S315,否则跳转到S313;在这里需要说明的是,如果当前的待压缩时序数据的上斜率小于其下斜率,当然不保存这个当前的待压缩时序数据,并且跳转到S313时,以下一个待压缩时序数据作为步骤S313中的“当前的待压缩时序数据”;
S315、保存前一时序数据,以该时序数据作为新的压缩起点,并且跳转到S313以继续压缩该行的时序数据,直至该行所有的时序数据压缩完毕,此时执行S32;在这里需要说明的是,当有了新的压缩起点之后,会跳转到S313,此时以这里的这个“新的压缩起点”作为S313中的“当前压缩起点”,换句话说,当有“新的压缩起点”时,步骤S313中的“当前压缩起点”也会相应地更新为这个“新的压缩起点”。
S32、将该行压缩后的时序数据合并成一条记录;
S4、存储步骤:将测点索引表及测点数据表以Key-Value的形式存储于存储文件。
当然,在这里需要说明的是,对于测点数据表中的任一时序数据行,若执行合并步骤之前,该时序数据行就已经被存储在存储文件中,那么在对该时序数据行执行合并步骤之后,就需要将该时序数据行存储在存储文件中的原数据删除;这是理所当然的常识。
图2所示,为本实施例所采用旋转门算法的原理图。图中共有8个时序数据,其数据生成时间分别为t0、t1、t2、t3、t4、t5、t6和t7。为了方便描述,在这里将这8个时序数据分别称为t0、t1、t2、t3、t4、t5、t6和t7。假设t0为上一个被存储的时序数据,那么将t0作为这里的第一个压缩起点,根据压缩阈值ΔE分别计算出t0的上轴点a1和下轴点a2,然后开始计算接下来的时序数据的上斜率和下斜率,当计算到t4时,此时能够得到t4的上斜率相当于直线L1的斜率,t4的下斜率相当于直线L2的斜率,那么其上斜率大于下斜率,所以保存前一时序数据t3,并且以t3作为新的压缩起点,同理得到下一个压缩起点是t6。在这里需要说明的是,对于时序数据t1来说,其上斜率就是其本身与上轴点a1的斜率;换句话说,对于当前的待压缩时序数据,若其前一时序数据是压缩起点,那么这个当前的待压缩时序数据的上斜率就是其本身与上轴点的斜率。
图3所示,为执行合并步骤前的测点数据表,即该表既未经过旋转门压缩其时序数据行也未合并成一条记录。为了方便描述,图3所示的测点数据表只有一行,该行的rowKey=cpu.server:2017121208:host=10.0.3.93,表示对地址为10.0.3.93的服务器的cpu使用率的监控,在本实施例中,该测点数据表的时间周期的长度为1个小时,并且rowKey中的时间标识为整点时间,例如2017121208表示2017年12月12日08时,该行共有3600列,例如第一列就表示2017年12月12日08时00分01秒的cpu使用率为5%。
采用旋转门算法对该行进行压缩后,得到的结果如图4所示,其时序数据行经压缩后剩余6个时序数据,分别为t0、t1、t2、t3、t4和t5,当然,一般而言不会这么少,这里只是为了方便解释,所以假定剩余6个时序数据。旋转门算法是一种线性拟合算法,属于有损压缩,能够减少时序数据的保存量,节省存储空间,并且拥有误差可控、实现简单的优点。
图5所示,为图4所示测点数据表的存储结构示意图,其共有6个Key-Value,其中每个key-Value的Key都会带有一个rowKey,这里的rowKey就是cpu.server:2017121208:host=10.0.3.93,共6个。如图6所示,为将图4所示的测点数据表的时序数据行合并成一条记录后的表结构示意图,形象地来说,其实就是把一行多列的数据合并成一行一列的数据。图7所示,为图6所示测点数据表的存储结构示意图,仅有1个Key,那么就只有一个rowKey。这意味着需要存储rowKey大大减少。
图8所示,为本发明实施例一所采用测点索引表的表结构示意图。该测点索引表包括两个列族,其中一个列族,其包括三种类型的列成员,分别表示测点的名称、标签键及标签值;另一个列族,其包括三种类型的列成员,分别表示测点的名称、标签键及标签值所对应的UID;在测点索引表中,其数据行的rowKey,为测点的名称、标签键及标签值的其中之一,或者为测点的名称、标签键及标签值所对应的UID之一。具体来说,每个UID的长度固定为3个字节。
图7所示的测点数据表,采用测点索引表所提供UID映射之后,所得到的存储结构示意图,如图9所示。
实施例二
本发明实施例二提供一种电子设备,包括存储器、处理器以及存储在存储器上并且可在处理器上运行的计算机程序,该处理器执行该计算机程序时,实现如本发明实施例一所述的时序数据的压缩存储方法。其中,该电子设备可以为但不限于个人计算机、服务器、智能手机及网络设备。
实施例三
本发明实施例三提供一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时,实现如本发明实施例一所述的时序数据的压缩存储方法。通过以上描述,所属领域技术人员能够清楚地了解到,本发明的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在计算机可读存储介质中,该存储介质可以为但不限于计算机的软盘、只读存储器、随机存取存储器、闪存、硬盘及光盘。
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!