一种基于学习社区对话流的成绩预测方法与流程
技术特征:
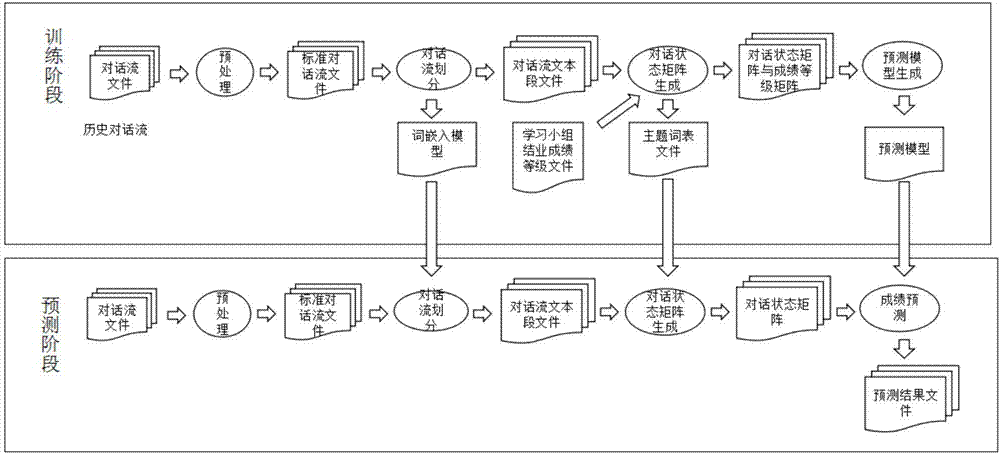
1.一种基于学习社区对话流的成绩预测方法,其特征在于:该方法针对输入的课程下的学习小组的对话流文件,输出该小组中的学习者成绩等级,该方法分为训练和预测两个阶段,训练阶段得到成绩预测模型,预测阶段应用此模型进行成绩预测;
该方法包括以下步骤:
(1)训练阶段,将某课程的历史对话流文件及每个对话流文件对应学习小组的课程结业成绩等级作为训练阶段的输入数据,在此基础上,首先通过预处理得到标准对话流文件;其次通过对话流划分算法,生成词嵌入模型并得到对话流文本段文件;接着,通过对话状态矩阵生成算法,生成主题词表文件、学习小组的对话状态矩阵和成绩等级矩阵;最后通过预测模型生成算法,得到预测模型;
(2)预测阶段,将该课程的对话流文件作为输入,利用训练阶段得到的多个模型和文件,通过采用与训练过程相同的处理步骤,即预处理、对话流划分算法、对话状态矩阵生成算法,最后应用训练阶段生成的成绩预测模型得到成绩等级。
2.根据权利要求1所述的基于学习社区对话流的成绩预测方法,其特征在于:所述预处理方法的输入为对话流文件,该文件中的一个对话包含两行内容:第一行为对话的时间戳和发言人;第二行为对话内容;
预处理方法具体步骤如下:
第一步,提取对话中的时间戳、发言人和发言内容,生成形如格式“<TS>时间<TS>发言人<TE><CS>发言内容<CE>”形式的对话;
第二步,合并对话之间时间差值小于阈值T,T=2min,且发言人相同的对话的发言内容,以生成标准对话;
第三步,删除发言内容长度小于阈值L的标准对话,L=10字长,最终获取标准对话流文件。
3.根据权利要求1所述的基于学习社区对话流的成绩预测方法,其特征在于所述对话流划分算法具体步骤如下:
第一步,遍历每一个标准对话流文件,将文件中标准对话的发言内容进行分词处理后作为一行写入词嵌入语料文件;
第二步,利用词嵌入语料文件训练CBOW模型;
第三步,依次处理每一个标准对话流文件;创建文本段ID及保存其对应对话链表的字典;依次遍历每一个标准对话,如果标准对话与当前ID对应对话链表中最后一个对话的时间差值小于T’,T’=2min,且标准对话的发言内容与当前ID对应对话链表的内容相似度大于S,S选用使得划分后的对话流文本段的文本段个数均值最接近前3个月教学大纲中的核心知识点数的相似度,将标准对话加入当前ID对应对话链表,否则,ID加1,将标准对话加入ID对应对话链表;计算字典中每个对话链表的发言内容长度和均值;将字典中发言内容长度和大于均值的对话链表中每个对话的发言内容拼接为一个文本段写入与其对应的对话流文本段文件;
按照如下公式计算标准对话与ID对应对话链表的内容相似度
DiaSim=MAX(Sim(Dia,Diai)),Diai∈Block_Map[ID]
其中,Dia为每次读取的标准对话,Diai为字典中ID对应对话链表中的对话;
按照如下公式计算每两个标准对话的内容相似度
其中,Word_List函数表述对话发言内容切分后的词链表,Wi、Wj分别是Dia1和Dia2中的词,n为Dia1发言内容切分词链表的长度,公式在计算时保证Dia1发言内容切分词链表的长度小于Dia2发言内容切分词链表的长度,MAX函数在计算时使用CBOW模型中Wi、Wj所对应向量,计算其余弦相似度,最大值累加到Sim。
4.根据权利要求1所述的基于学习社区对话流的成绩预测方法,其特征在于所述对话状态矩阵生成算法具体步骤如下:
第一步,利用对话文本段文件中的文本段训练LDA模型,设置主题的个数为K,K为前三个月课程核心知识点个数;
第二步,创建主题词集合,将LDA模型输出的K个主题中每个主题的前M个高频词写入集合,M选用使得主题词表大小最接近核心知识点*核心知识点下的一级子知识点的均值,对集合去重操作后,将每个主题词及其集合中的位置编号作为一行写入主题词表文件;
第三步,创建对话状态矩阵链表和成绩等级向量链表;依次处理每一个对话流文本段文件及其对应的结业成绩等级,将对话流文本段文件转换成对话状态矩阵并加入对话状态矩阵链表,将成绩等级转换成成绩等级向量加入成绩等级向量链表;
按照以下规则将对话流文本段文件转换成对话状态矩阵:建立R行C列的全0矩阵,R为对话流文本段文件中的文本段个数,C为主题词表文件中主题词个数,依次为对话流文本段文件中的文本段创立长度为C的文本段向量,使用LDA模型得到文本段对应的主题,得到前F个主题下的前M个高频词作为表示这个文本段的主题词,F取值为[1,3]中的整数,M与第二步的取值一致,查找每个主题词在主题词表中的编号,将文本段向量中对应主题词标号下标位置的0置为1,将文本段向量放入对话状态矩阵中;
按照以下规则生成成绩等级向量:为每个成绩等级创建长度为Q的全0向量,Q为进行预测的等级个数,并把成绩等级对应下标位置的0置为1。
5.根据权利要求1所述的基于学习社区对话流的成绩预测方法,其特征在于:所述预测模型生成算法基于LSTM的预测模型对成绩等级进行预测,该预测模型的每一次输入为一个对话状态矩阵,每个时间步的输入为对话状态矩阵对应时间步位置的对话状态向量,描述了对应对话文本段的核心语义内容;LSTM隐藏层的个数为主题个数K,K为课程前3个月内核心知识点个数,记录对话流中包含的课程核心知识点的语义信息,隐藏层H的激活函数选择sigmod,其个数设计为要预测的学习者成绩等级个数,记录对话流中的成绩等级信息,模型的深度为3层,记录课程前3个月对话流的语义信息;Softmax层输出学习者成绩属于不同等级的概率,损失函数选择交叉熵,并使用随机梯度下降方法进行优化,模型训练时,使用对话状态矩阵生成算法得到的对话状态矩阵链表作为训练数据,成绩等级矩阵作为标记数据。
- 还没有人留言评论。精彩留言会获得点赞!