针对井下工作安全监测的大数据挖掘系统的制作方法
本发明属于大数据挖掘技术领域,涉及一种针对井下工作安全监测的大数据挖掘系统。
背景技术:
我国许多大、中型煤矿都建立了通风安全监测系统、井下突水监控系统、井下煤与瓦斯突出监测系统等煤炭安全决策系统,这些系统中积累了大量的原始数据,如何将数据演变成可以科学决策的信息是煤矿安全生产要考虑的问题。
而粗糙集理论作为能够定量分析不确定和不完备信息与知识的方法,为数据挖掘提供了一种新的方法。
粗糙集理论是波兰数学家z.pawlak于1982年提出的一种数据分析理论,它作为一种刻画具有不完整性和不确定性的信息的全新的数学工具,是具有很强的定性分析能力,已广泛应用于数据挖掘、信息融合、决策分析和决策支持、模式识别、机器学习、故障诊断和控制算法获取等各种应用领域。
技术实现要素:
本发明目的在于提供一种针对井下工作安全监测的大数据挖掘系统,针对如何将之前积累的大量原始数据演变成可以科学决策井下工作安全生产关键信息的问题,引入基于属性简约的缺省规则挖掘模型,采取一定的搜索策略搜索约简格,根据已有的信息在格中逐层进行匹配,按照某种优先级判定算法,得出问题的最优解,有效地解决在决策表不完备和不一致情况下的推理和决策问题,实现了把海量数据进行有效分析后成功地运用到井下工作安全决策中。
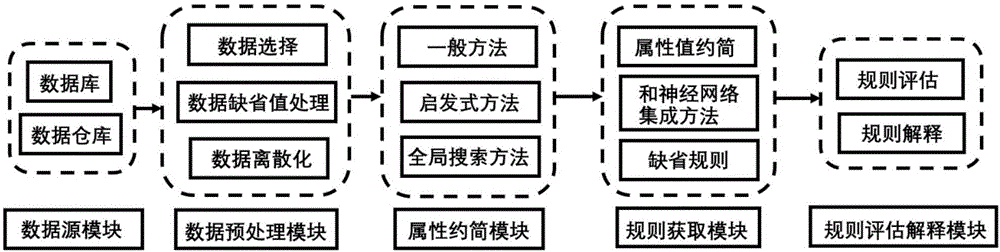
为解决上述技术问题,本发明采用如下的技术方案:一种针对井下工作安全监测的大数据挖掘系统,该系统包括:数据源模块、数据预处理模块、属性约简模块、规则获取模块以及规则评估解释模块;其中,所述数据源模块由各原始系统所采集数据累计组合而成,负责提供安全策略分析的数据支持;所述数据预处理模块负责对所述数据源模块提供的原始数据进行一定的初始化处理;所述属性约简模块主要负责对所述数据预处理模块处理后的数据属性进行约简,达到数据的浓缩与泛化;所述规则获取模块主要负责从所述属性约简模块提交的数据集中提取规则;所述规则评估解释模块负责对所述规则获取模块提取的规则进行最终解释。
进一步地,所述数据预处理模块包含数据选择、数据缺省值处理和数据离散化3个功能。
进一步地,所述属性约简模块基于粗糙集理论框架,是一切粗糙集理论应用的核心,包括一般方法、启发式方法和全局搜索属性方法3种方法。
进一步地,所述规则提取模块采用基于粗糙集理论的属性值约简方法。
进一步地,所述规则评估解释模块包括对分类规则的预测精度、可信度和支持度的分析、规则的个数和规则的平均条件个数的评估等方法。
本发明与现有技术相比具有以下的有益效果:
本发明方案针对如何将之前积累的大量原始数据演变成可以科学决策井下工作安全生产关键信息的问题,引入基于属性简约的缺省规则挖掘模型,采取一定的搜索策略搜索约简格,根据已有的信息在格中逐层进行匹配,按照某种优先级判定算法,得出问题的最优解,有效地解决在决策表不完备和不一致情况下的推理和决策问题。
附图说明
图1是针对井下工作安全监测的大数据挖掘系统的整体架构图。
具体实施方式
下面结合附图及具体实施例对本发明进行更加详细与完整的说明。可以理解的是,此处所描述的具体实施例仅用于解释本发明,而非对本发明的限定。
为了更好地解决在决策表不完备和不一致情况下的推理和决策问题,提出了一种基于属性简约的缺省规则挖掘模型,设计了如图1所示的针对井下工作安全监测的大数据挖掘系统体系结构。
参照图1,针对井下工作安全监测的大数据挖掘系统实现了数据挖掘的主要过程:数据预处理,数据挖掘,模型解释及模型评估等,整个系统有数据源模块、数据预处理模块、属性约简模块、规则获取模块以及规则评估解释模块;其中,所述数据源模块由各原始系统所采集数据累计组合而成,负责提供安全策略分析的数据支持;所述数据预处理模块负责对所述数据源模块提供的原始数据进行一定的初始化处理;所述属性约简模块主要负责对所述数据预处理模块处理后的数据属性进行约简,达到数据的浓缩与泛化;所述规则获取模块主要负责从所述属性约简模块提交的数据集中提取规则;所述规则评估解释模块负责对所述规则获取模块提取的规则进行最终解释。
数据预处理模块包含数据选择、数据缺省值处理和数据离散化3个功能,数据选择包括数据表的选择、数据表中数据对象的选择等;缺省值补充包括缺省值的几种填充方法和忽略方法;属性连续值的离散其实是一个决策表的泛化过程,这里采用的启发式遗传算法。算法如下:①设置最大进化代数g,群体规模psize,初始温度t0,pc1、pc2、pm1、pm2等遗传算法参数;②设进化代数计数t=0,根据初始候选断点选择的规则,选择初始候选断点集,初始化群体p(t);③计算初始群体p(t)的各个个体的适应度值;④在群体p(t)上进行选择操作,得到群体p'(t);⑤对群体p'(t)进行交叉和变异操作,得到群体p″(t);⑥对群体p″(t)进行修正操作,得到下一代群体p(t+1);⑦如果t=g或最优个体满足问题要求则结束,否则计算群体p(t+1)的各个个体的适应度值,转④。
属性约简模块是基于粗糙集理论框架,主要是对数据属性的约简,达到数据的浓缩与泛化,属性约简是一切粗糙集理论应用的核心。属性约简包括一般约简方法、启发式约简方法和全局搜索属性约简方法3种方法,这里采用启发式免疫算法。算法如下:①首先求决策表的相对差异比较表,然后根据相对差异比较表计算出决策表属性约简的核属性;②初始化算法参数:抗体群规模为n,记忆库规模m,迭代次数epochs,交叉概率pc,变异概率pm,权衡因子γ;③定义抗体ag为属性约简集中属性的个数;④对属性约简进行编码:每个抗体都包含核属性,只对非核属性进行编码,设定抗体群a1规模为n+m;⑤修正操作:对新抗体群a1中抗体通过修正策略进行修正,使得每个抗体为有效抗体;⑥亲和力计算:计算ak(n+m)中各个抗体abj的亲和度fj与浓度cj;⑦抗体评价:计算抗体abj的期望繁殖率为prj=prfj+γprcj;⑧记忆库更新:用抗体群ak中识别亲和力较大的m个优秀抗体替换记忆库的较差抗体,保证记忆库现存抗体的平均亲和力大于等于更新前的;⑨中止条件判断:迭代次数是否达到,连续迭代一定次数后抗体亲和度函数值是否没有变化。输出记忆库中所得到的所有约简属性集,结束运行。否则继续下一步操作;⑩遗传操作:对ak中的抗体采取基于亲和度和浓度的综合评价方式,在ak中通过期望繁殖率pr采用轮盘赌选择方法选出n个抗体作为父代群体bk。对bk分别按照交叉概率pc和变异概率pm选择相应抗体,进行交叉和变异操作得到bk+1;
规则提取模块主要从数据集中提取规则,这里采用了基于粗糙集理论的属性值约简方法。规则评估及解释模块包括对分类规则的预测精度、可信度和支持度的分析、规则的个数和规则的平均条件个数的评估等方法以及对规则进行最终解释。
以上所述仅为本发明的优选实施例,并不用于限制本发明,对于本领域技术人员而言,本发明可以有各种改动和变化。凡在本发明的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!