图像处理的制作方法
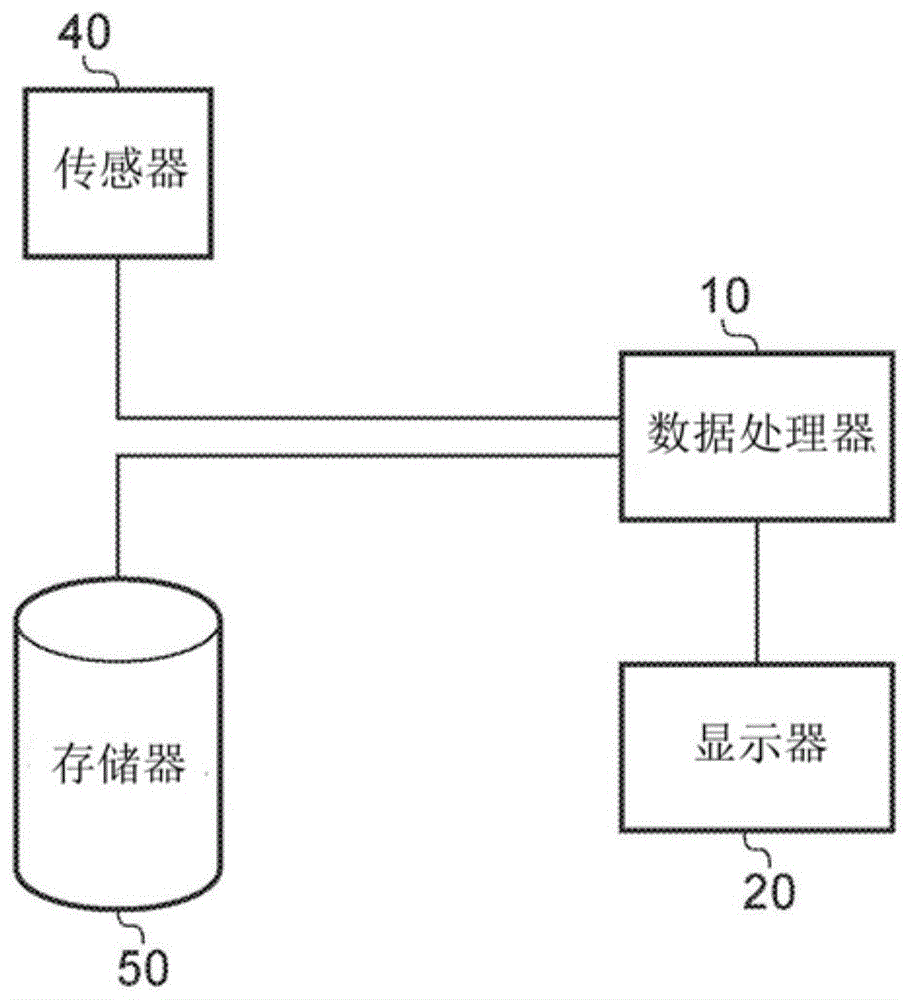
本发明涉及成像方法、成像装置和计算机程序产品。
背景技术:
:图像处理是已知的。通常,成像设备或传感器对对象成像并提供图像数据,该图像数据提供对象的表示。可以查看该图像数据以识别对象的元素。尽管存在图像处理技术以帮助识别对象的元素,但它们各自具有其自身的缺点。因此,期望提供改进的图像处理技术。技术实现要素:根据第一方面,提供了一种成像方法,包括:接收三维对象的图像数据;并且使用机器学习算法将置信水平分配给图像数据的图像帧的至少一部分,该置信水平指示具有通过三维对象在指定平面上成像的指定元素的图像帧的可能性。第一方面认识到随着对象的复杂性增加,识别对象中的元素变得更加复杂。而且,已知提供三维对象的图像数据,这使得识别那些三维对象中的元素更加复杂。此外,找到三维对象的元素的特定视图增加了这种复杂性。因此,提供了一种图像处理方法。该方法可以包括接收图像数据的步骤。图像数据可以是或表示三维对象的图像。该方法可以包括分配或确定图像数据的图像帧的一部分(aportionorapart)的置信水平。可以使用机器学习算法确定置信水平。置信水平可以指示当通过三维对象在指定或特定平面上成像或观看时图像帧具有指定的、定义的或特定的元素或特征的可能性或概率。换句话说,机器学习算法可以在通过三维对象以特定方式成像或观看时识别三维对象的特定元素或特征的存在。以这种方式,可以从三维对象的图像数据识别以期望方式成像的特定元素。在一个实施例中,分配包括将多个置信水平分配给图像数据的图像帧,每个置信水平指示该图像帧具有通过三维对象在相应的指定平面上成像的相应指定元素的可能性。因此,可以分配或指定置信水平,其指示当通过三维对象在它们自己的相关平面上成像时,多个不同元素中的每一个是否存在于图像帧中。在一个实施例中,分配包括将置信水平分配给图像数据的多个图像帧中的每一个。因此,置信水平可以分配或指定给图像数据的一系列图像帧中的每一个,例如将由视频流或图像帧序列通过三维图像数据提供。在一个实施例中,图像数据由图像捕获装置的操作者捕获,并且该方法包括向操作者指示每个置信水平。因此,图像数据可以由图像捕获装置、传感器或设备的操作者获得。该方法可以向操作者指示每个置信水平以提供操作者反馈。在一个实施例中,该方法包括向操作者指示图像帧之间的每个置信水平的变化。因此,不仅可以向操作者指示绝对置信水平,而且还可以向操作者识别从图像帧到图像帧的置信水平的任何变化。在一个实施例中,该方法包括向操作者指示每个置信水平的增加和减少之一。因此,可以向操作者识别不同置信水平的增加和/或减少。在尝试获取特定元素时,这可能对操作者有帮助。在一个实施例中,该方法包括向操作者指示增加置信水平所需的图像捕获装置的移动。因此,可以向操作者提供如何移动图像捕获设备以便增加一个或多个置信水平的指示。在一个实施例中,该方法包括向操作者指示每个置信水平何时超过阈值量。可以设置阈值,使得当超过阈值时,可以假设已经获取了元素的合适图像,并且这可以识别给操作者。在一个实施例中,该方法包括当该图像帧的置信水平超过阈值量时,存储至少一个图像帧,和将该图像帧与其指定元素相关联。因此,可以存储置信水平超过阈值量的图像帧,并将其与在这些图像帧内成像的指定元素相关联,以供将来参考和/或选择。在一个实施例中,该方法包括当该图像帧的置信水平未能超过阈值量时,存储至少一个图像帧,和将该图像帧与其指定元素相关联。因此,还可以存储未达到阈值量的一个或多个图像帧以供将来参考和/或选择,因为这些在重新训练机器学习算法时可能是有用的。在一个实施例中,该方法包括利用其指定元素的指示来注释所存储的图像帧。因此,可以使用所存储的图像帧来注释或提供在该图像帧内成像哪个元素的指示。在一个实施例中,机器学习算法为每个指定元素生成特征图,该特征图具有图分量,并且该方法包括为该图像帧生成显著性图,该图像帧将激活的图分量从特征图映射到该图像帧中的像素上。在一个实施例中,机器学习算法为每个指定元素生成特征图,该特征图具有图分量,并且该方法包括,当置信水平超过该图像帧的阈值量时,为该图像帧生成显著性图,该图像帧将激活的图分量从特征图映射到该图像帧中的像素上。因此,可以为每个元素生成特征图。每个特征图可以具有图分量或神经元,其可以用于生成该图像帧的显著性图。显著性图可以在特征图上在空间上将激活的图分量映射到从其导出特征图的源图像帧的像素上,以帮助识别已经识别的图像帧中的元素。在一个实施例中,生成显著性图包括将所选百分比的最激活的图分量从特征图映射到该图像帧中的像素上。因此,可以忽略特征图上的那些最少激活的图分量或神经元,并且仅将更多激活的图分量在空间上映射到源图像帧中的像素上。在一个实施例中,该方法包括通过使用显著性图突出显示其指定元素来注释图像帧。因此,显著性图可用于在图像帧内在空间上突出显示元素,以帮助识别那些图像帧内的元素。在一个实施例中,突出显示包括覆盖围绕该指定元素的边界框。在一个实施例中,突出显示包括覆盖定义该指定元素的图像帧内的像素的颜色变化。在一个实施例中,突出显示包括覆盖指定元素的测量。在一个实施例中,该方法包括指示每个置信水平何时落入置信水平的不同范围内。这提供了向操作者指示置信水平的简单且直观的方式。在一个实施例中,该方法包括向操作者指示指定元素的列表。因此,可以向操作者指示要获取的所有元素。在一个实施例中,该方法包括在列表中指示何时存储了至少一个图像帧并将其与其指定元素相关联。在列表中指示在图像帧中识别了哪些元素以及存储的那些图像帧,帮助操作者保持跟踪哪些元素在图像帧中已经识别和尚未识别。在一个实施例中,该方法包括在列表中指示何时尚未存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,该方法包括,对于每个指定元素,呈现与该指定元素相关联的每个存储图像帧以供操作者选择。因此,提供了已经存储并与元素相关联的每个图像帧以供操作者选择。在一个实施例中,一旦为每个指定元素存储了至少一个图像帧,则发生呈现步骤。在一个实施例中,该方法包括丢弃与由操作者选择的图像帧之外的指定元素相关联的图像帧。因此,可以忽略那些未被操作者选择的图像。在一个实施例中,该方法包括使用所选择的图像帧来训练机器学习算法。因此,为每个元素的所选图像可以用于机器学习算法的后续训练。在一个实施例中,图像数据包括三维图像数据集,并且该方法包括从三维图像数据集生成图像帧。因此,可以从用于处理的三维图像数据集生成图像帧。在一个实施例中,生成包括通过三维图像数据集生成表示平行平面序列的图像帧。在一个实施例中,产生包括通过三维图像数据集生成表示第一平行平面序列的图像帧,以及通过与第一平行平面序列正交的三维图像数据集生成表示至少第二平行平面序列的图像帧。因此,三维图像数据集可以表示为例如x、y和z平面中的平行平面序列。在一个实施例中,该方法包括组合来自每个序列的显著性图并执行三维变换以获得具有通过三维对象在该指定平面上成像的指定元素的图像帧。因此,可以组合来自每个图像帧序列的显著性图,并且执行三维变换以通过包含最大显著性的三维图像数据获得平面的参数。然后可以通过机器学习算法处理平面上的图像帧并分配置信水平。在一个实施例中,该方法包括使用批量的源训练数据训练机器学习算法,源训练数据包括通过三维对象在指定平面上成像的每个指定元素的图像帧,一个指定元素是不存在感兴趣项目的背景元素。因此,可以使用批次或训练数据组。当在所需平面上成像时,训练数据可包括每个元素的一个或多个图像帧,并且其中一个元素可以是不存在感兴趣的项目或元素的背景元素。以这种方式创建批量训练数据有助于确保能够识别每个元素并确保机器学习算法能够识别不存在指定元素的背景图像。在一个实施例中,每批训练数据包括用于包括背景元素的每个指定元素的相似数字的图像帧。为了充分地建模背景元素类(通常更复杂并且可以具有多种外观),数据集由数字比前景元素大得多的背景元素组成。为了确保机器学习算法学会强有力地区分前景和背景元素,应该避免在仅包含背景元素的批次上进行训练。创建包含相似数字的每个元素的图像帧的批次可以防止这种陷阱。在一个实施例中,用于背景元素的图像帧的格式不同于用于其他指定元素的图像帧的格式,并且该方法包括调整用于其他指定元素的图像帧的格式以与背景元素的格式对齐。因此,可以将图像帧改变为视觉上类似的每种格式。在一个实施例中,该方法包括:包括用于背景元素的图像帧,来自源训练数据的图像帧,其中在源训练数据的相邻图像帧之间发生大于阈值的移动量。应当理解,当在图像帧之间发生高度移动时,更有可能从一般图像数据中识别背景图像。在一个实施例中,该方法包括修改每批训练数据之间的每个指定元素的图像帧。通常,每个指定元素的图像帧的数量通常可以小于背景元素的帧的数量。修改每个元素的图像帧使这些图像帧可以重新用于训练,并有助于防止过度拟合。修改图像帧有助于有效地增加数据集的大小。在一个实施例中,修改包括旋转、裁剪、缩放、平移、镜像、滤波、添加噪声和调整图像帧的亮度和对比度中的至少一个。在一个实施例中,图像数据包括通过三维对象拍摄的超声波、磁共振成像、x射线计算机断层摄影、正电子发射断层摄影和单光子发射计算机断层摄影图像数据中的一个。应当理解,可以提供各种不同的图像数据类型。在一个实施例中,图像数据包括记录和实时图像数据中的一个。在一个实施例中,三维对象包括有生命和无生命对象中的一个。应当理解,可以对各种不同的对象进行成像。在一个实施例中,三维对象包括胎儿、器官和植入物中的一个。在一个实施例中,机器学习算法包括卷积神经网络。根据第二方面,提供了一种成像装置,包括:接收逻辑,可操作以接收三维对象的图像数据;和逻辑,可操作以使用机器学习算法将置信水平分配给图像数据的图像帧的至少一部分,置信水平表示该图像帧具有通过三维对象在指定平面上成像的指定元素的可能性。在一个实施例中,逻辑可操作以将多个置信水平分配给图像数据的图像帧,每个置信水平指示该图像帧具有通过三维对象在相应的指定平面上成像的相应指定元素的可能性。在一个实施例中,逻辑可操作以将置信水平分配给图像数据的多个图像帧中的每一个。在一个实施例中,图像数据由图像捕获装置的操作者捕获,并且逻辑可操作以向操作者指示每个置信水平。在一个实施例中,逻辑可操作以向操作者指示图像帧之间的每个置信水平的变化。在一个实施例中,逻辑可操作以向操作者指示每个置信水平的增加和减少中的一个。在一个实施例中,逻辑可操作以向操作者指示增加置信水平所需的图像捕获装置的移动。在一个实施例中,逻辑可操作以向操作者指示每个置信水平何时超过阈值量。在一个实施例中,逻辑可操作以在该图像帧的置信水平超过阈值量时存储至少一个图像帧并将该图像帧与其指定元素相关联。在一个实施例中,逻辑可操作以在该图像帧的置信水平未超过阈值量时存储至少一个图像帧并将该图像帧与其指定元素相关联。在一个实施例中,逻辑可操作以利用其指定元素的指示来注释所存储的图像帧。在一个实施例中,机器学习算法可操作用于为每个指定元素生成特征图,当置信水平超过该图像帧的阈值量时,该特征图具有图分量并且逻辑可操作,以为该图像帧生成显著性图,该图像帧将激活的图分量从特征图映射到该图像帧中的像素上。在一个实施例中,逻辑可操作以将选定百分比的最激活的图分量从特征地图映射到该图像帧中的像素上。在一个实施例中,逻辑可操作以通过使用显著性图突出显示其指定元素来注释图像帧。在一个实施例中,逻辑可操作以通过覆盖围绕该指定元素的边界框来突出显示其指定元素。在一个实施例中,逻辑可操作以通过覆盖定义该指定元素的图像帧内的像素的颜色变化来突出显示其指定元素。在一个实施例中,逻辑可操作以通过覆盖指定元素的测量来突出显示其指定元素。在一个实施例中,逻辑可操作以指示每个置信水平何时落入置信水平的不同范围内。在一个实施例中,逻辑可操作以向操作者指示指定元素的列表。在一个实施例中,逻辑可操作以在列表中指示何时已存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,逻辑可操作以在列表中指示何时尚未存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,对于每个指定元素,逻辑可操作以呈现与该指定元素相关联的每个存储的图像帧以供操作者选择。在一个实施例中,逻辑可操作以一旦为每个指定元素存储了至少一个图像帧就呈现每个存储的图像帧。在一个实施例中,逻辑可操作以丢弃与由操作者选择的图像帧之外的指定元素相关联的图像帧。在一个实施例中,逻辑可操作以使用所选择的图像帧来训练机器学习算法。在一个实施例中,图像数据包括三维图像数据集,并且逻辑可操作以从三维图像数据集生成图像帧。在一个实施例中,逻辑可操作以通过三维图像数据集生成表示平行平面序列的图像帧。在一个实施例中,逻辑可操作以通过三维图像数据集生成表示第一平行平面序列的图像帧以及通过与第一平行平面序列正交的三维图像数据集生成表示至少第二平行平面序列的图像帧。在一个实施例中,逻辑可操作以组合来自每个序列的显著性图并且执行三维变换以获得具有通过三维对象在该指定平面上成像的指定元素的图像帧。在一个实施例中,逻辑可操作以使用批量的源训练数据训练机器学习算法,源训练数据包括通过三维对象在指定平面上成像的每个指定元素的图像帧,一个指定元素是不存在感兴趣项目的背景元素。在一个实施例中,每批训练数据包括用于包括背景元素的每个指定元素的相似数字的图像帧。在一个实施例中,用于背景元素的图像帧的格式不同于用于其他指定元素的图像帧的格式,并且逻辑可操作以调整用于其他指定元素的图像帧的格式以与背景元素的格式对齐。在一个实施例中,逻辑可操作以包括作为背景元素的图像帧,来自源训练数据的图像帧,其中在源训练数据的相邻图像帧之间发生大于阈值的移动量。在一个实施例中,逻辑可操作以修改每批训练数据之间的每个指定元素的图像帧。在一个实施例中,逻辑可操作以使用旋转、裁剪、缩放、平移、镜像、滤波、添加噪声和调整图像帧的亮度和对比度中的至少一个来修改图像帧。在一个实施例中,图像数据包括通过三维对象拍摄的超声波、磁共振成像、x射线计算机断层摄影、正电子发射断层摄影和单光子发射计算机断层摄影图像数据中的一个。在一个实施例中,图像数据包括记录和实时图像数据中的一个。在一个实施例中,三维对象包括有生命和无生命对象中的一个。在一个实施例中,三维对象包括胎儿、器官和植入物中的一个。在一个实施例中,机器学习算法包括卷积神经网络。根据第三方面,提供了一种成像方法,包括:向操作者指示三维对象的图像帧具有通过三维对象在指定平面上成像的指定元素的置信水平。在一个实施例中,指示包括向操作者指示多个置信水平,即三维对象的图像帧具有通过三维对象在相应的指定平面上成像的多个指定元素中的相应一个。在一个实施例中,该方法包括向操作者指示图像帧之间的每个置信水平的变化。在一个实施例中,该方法包括向操作者指示每个置信水平的增加和减少中的一个。在一个实施例中,该方法包括向操作者指示增加置信水平所需的图像捕获装置的移动。在一个实施例中,该方法包括向操作者指示每个置信水平何时超过阈值量。在一个实施例中,该方法包括通过使用显著性图突出显示其指定元素来注释图像帧。在一个实施例中,突出显示包括覆盖围绕该指定元素的边界框。在一个实施例中,突出显示包括覆盖定义该指定元素的图像帧内的像素的颜色变化。在一个实施例中,突出显示包括覆盖指定元素的测量。在一个实施例中,该方法包括指示每个置信水平何时落入置信水平的不同范围内。在一个实施例中,该方法包括向操作者指示指定元素的列表。在一个实施例中,该方法包括在列表中指示何时存储了至少一个图像帧并将其与其指定元素相关联。在一个实施例中,该方法包括在列表中指示何时尚未存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,该方法包括,对于每个指定元素,呈现与该指定元素相关联的每个存储的图像帧以供操作者选择。在一个实施例中,一旦为每个指定元素已经存储了至少一个图像帧,则发生呈现步骤。在一个实施例中,图像数据包括通过三维对象拍摄的超声波、磁共振成像、x射线计算机断层摄影、正电子发射断层摄影和单光子发射计算机断层摄影图像数据中的一个。在一个实施例中,图像数据包括记录和实时图像数据中的一个。在一个实施例中,三维对象包括有生命和无生命对象中的一个。在一个实施例中,三维对象包括胎儿、器官和植入物中的一个。根据第四方面,提供了一种成像装置,包括:逻辑,可操作以向操作者指示三维对象的图像帧具有通过三维对象在指定平面上成像的指定元素的置信水平。在一个实施例中,逻辑可操作以向操作者指示多个置信水平,即三维对象的图像帧具有通过三维对象在相应的指定平面上成像的多个指定元素中相应的一个。在一个实施例中,逻辑可操作以向操作者指示图像帧之间的每个置信水平的变化。在一个实施例中,逻辑可操作以向操作者指示每个置信水平的增加和减少中的一个。在一个实施例中,逻辑可操作以向操作者指示增加置信水平所需的图像捕获装置的移动。在一个实施例中,逻辑可操作以向操作者指示每个置信水平何时超过阈值量。在一个实施例中,逻辑可操作以通过使用显著性图突出显示其指定元素来注释图像帧。在一个实施例中,逻辑可操作以通过覆盖围绕该指定元素的边界框,定义该指定元素的图像帧内的像素的颜色变化和指定元素的测量中的至少一个来突出显示。在一个实施例中,逻辑可操作以指示每个置信水平何时落入置信水平的不同范围内。在一个实施例中,逻辑可操作以向操作者指示指定元素的列表。在一个实施例中,逻辑可操作以在列表中指示何时已存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,逻辑可操作以在列表中指示何时尚未存储至少一个图像帧并将其与其指定元素相关联。在一个实施例中,对于每个指定元素,逻辑可操作以呈现与该指定元素相关联的每个存储的图像帧以供操作者选择。在一个实施例中,逻辑可操作以一旦为每个指定元素已经存储了至少一个图像帧就呈现。在一个实施例中,图像数据包括通过三维对象拍摄的超声波、磁共振成像、x射线计算机断层摄影、正电子发射断层摄影和单光子发射计算机断层摄影图像数据中的一个。在一个实施例中,图像数据包括记录和实时图像数据中的一个。在一个实施例中,三维对象包括有生命和无生命对象中的一个。在一个实施例中,三维对象包括胎儿、器官和植入物中的一个。根据第五方面,提供了一种计算机程序产品,当在计算机上执行时,可操作以执行第一或第三方面的方法。在所附独立和从属权利要求中阐述了进一步的特定和优选方面。从属权利要求的特征可以适当地与独立权利要求的特征组合,并且可以与权利要求中明确阐述的特征之外的特征组合。在装置特征描述为可操作以提供功能的情况下,应当理解,这包括提供该功能的装置特征或者适配或配置为提供该功能的装置特征。附图说明现在将参考附图进一步描述本发明的实施例,其中:图1示出了根据一个实施例的图像处理装置的布置;图2概括了根据一个实施例的cnn的架构;图3是表示根据一个实施例的由数据处理器10执行的主要处理步骤的流程图;图4提供了根据实施例的两个标准视图示例的概述;图5示出了根据实施例的从输入帧获得的显著性图;图6示出了根据一个实施例的每个特定元素的置信水平的示例显示;以及图7示出了根据一个实施例的两个志愿者的检索帧的示例。具体实施方式在更详细地讨论实施例之前,首先将提供概述。实施例提供了一种用于定位已经成像并且在图像数据中表示的三维对象的元件、零件、部件或特征的技术。通常,不仅需要在图像数据内识别三维对象的那些元素,而且还需要通过三维对象在特定方向或特定成像平面中识别或查看那些元素。例如,考虑对复杂的三维零件(例如机械组件)进行成像。不仅需要在该机械组件内识别诸如o形环的元件,而且还希望在平面图中而不是在横截面图中观察时识别o形环。同样,考虑对复杂的三维零件进行成像,例如人体或动物体。不仅需要识别心脏瓣膜,而且还希望在横截面视图中而不是平面图中识别瓣膜。因此,实施例利用机器学习算法,该算法被训练为当通过三维对象在指定平面上成像时识别图像帧中的这些元素。通常,训练机器学习算法以从三维对象的图像数据识别多于一个这样的元素,每个元素在其自己的特定平面上成像。一旦执行了机器学习算法的初始训练,就可以将实时或存储的图像数据提供给机器学习算法,然后提供置信水平,指示特定图像帧是否包含在其相关平面上成像的每个元素。通常,机器学习算法为要识别的每个元素生成特征图,该元素的置信水平来自该特征图。可以向人或机器人操作者指示每个元素的置信水平的指示。也可以向操作者指示置信水平的变化或改善置信水平所需的成像方向变化的指示。当元素的置信水平超过阈值量时,可以利用该元素的特征图来生成显著性图。特别地,利用特征图中最激活的图分量或神经元,因为它们与图像帧中的像素在空间上相关。通常通过改变它们的颜色和/或放置边界框和/或将所有其他像素设置为背景值来增强图像帧中的对应像素。如果图像帧的置信水平超过阈值量,则可以存储该图像帧和/或执行图像帧增强以帮助识别该图像帧内的元素。当在图像数据中识别每个元素并存储相关图像时,可以在显示器上向操作者指示。特别地,可以向用户指示已经识别或未识别的每个元素的指示。这使得能够快速可靠地识别各个元素。总体架构图1示出了根据一个实施例的图像处理装置的布置。提供数据处理器10,其与用户显示器20耦合。图像数据从传感器40或从存储器50实时提供给数据处理器10。图像数据可以以多种不同格式中的任何格式从各种不同的源提供。图像数据可以包括单独的2维图像帧,或者可以是3维图像数据。通常,图像数据由传感器40提供。应当理解,可以使用各种不同传感器中的任何一种,例如超声波、磁共振成像、x射线计算机断层摄影、正电子发射断层摄影(pet)或单光子发射计算机断层摄影(spect)装置。机器学习算法架构实施例利用在数据处理器10上执行的卷积神经网络(cnn)或模型来对图像数据执行图像识别。cnn的架构总结在图2中,并在表1中进行了描述。如图2所示,卷积内核的尺寸和步幅在顶部表示(符号:内核尺寸/步幅)。最大池化步骤由mp表示(2x2箱,步幅为2)。除c6以外的所有卷积的激活函数是整流的非线性单元(relu)。c6之后是全局平均池化步骤。每个图像/特征图底部的尺寸指的是训练阶段,并且由于输入图像较大,在推理过程中会略大一些。层类型输入尺寸滤波步幅pad输出尺寸c1卷积225x225x17x7x3220110x110x32m1最大池化110x110x322x22055x55x32c2卷积55x55x325x5x642026x26x64m2最大池化26x26x642x22013x13x64c3卷积13x13x643x3x1281113x13x128c4卷积13x13x1283x3x1281113x13x128c5卷积13x13x1281x1x641013x13x64c6卷积13x13x641x1xk1013x13xkap平均池化13x13xk---1xksmsoftmax1xk---1xk表1其中k是扫描平面的数量(在我们的案例中k=13),ap是全局平均池化层,它平均了前两个维度上的所有激活,无论尺寸如何。cnn是一个完全卷积的网络架构,其使用1x1内核用卷积层替换传统完全连接层[5,9]。在最终的卷积层(c6)中,输入减化为k13×13特征图fk,其中k是类的数量。然后对这些特征图中的每一个进行平均以获得最终softmax层的输入。该架构使网络在输入图像的尺寸方面具有灵活性。较大的图像将简单地产生较大的特征图,然而它将被映射到最终网络输出的标量上。这个事实用于训练裁剪的方形图像而不是有利于数据增强的完整视野。网络架构的一个关键方面是在每个特征图fk和相应的预测yk之间实施一对一的对应关系。由于特征图fk中的每个神经元在原始图像中具有感受野,因此在训练期间,只有当类k的对象在该场中时,神经元才会学习激活。这允许将fk解释为类k的空间编码置信映射[5]。该事实用于生成如下所述的局部显著性图。胎儿成像尽管实施例的图像处理技术可适用于使用各种成像技术的医学和其他成像,但是以下示例参考超声胎儿成像中的标准扫描平面的识别来描述图像处理技术。胎儿发育异常是工业化国家和发展中国家围产期死亡的主要原因[11]。尽管许多国家在孕龄大约20周时引入了基于妊娠中期超声(us)扫描的胎儿筛查计划,但检出率仍然相对较低。例如,据估计,在英国,大约26%的胎儿异常在怀孕期间未被检测到[4]。据报道,不同机构的检出率差别很大[1],这表明至少部分地,培训的差异可能是造成这种差异的原因。此外,根据世界卫生组织,世界上许多us扫描很可能是由很少或没有接受过正规培训的人进行的[11]。在胎儿体内不同位置获得的许多标准化2dus视平面上进行生物测量和异常识别。在英国,选择这些平面的指南在[7]中定义。标准扫描平面通常很难定位,即使对于有经验的超声医师也是如此,并且已经证明其具有低重现性和较大的操作者偏差[4]。因此,自动化或帮助该步骤的系统可能具有显著的临床影响,特别是在几乎没有高技能超声医师可用的地理区域中。它也是进一步处理的重要步骤,例如自动测量或异常的自动检测。训练如上所述,尽管参考超声波胎儿成像中的标准扫描平面的识别来说明实施例的图像处理技术,但是应当理解,这些技术同样适用于使用各种成像技术的医学和其他成像。为了对在不同平面上成像的不同元素执行不同三维对象的图像处理,将使用在不同平面上成像的那些不同元素的代表数据来训练机器学习算法。在该示例中,总数据集由同意志愿者的1003个2dus扫描结果组成,其孕龄在18-22周之间,这已经由使用gevolusone8系统的专业超声医师团队获得的。总数据集的80%用于训练(802个案例),总数据集的20%(201个案例)用于评估。对于每次扫描,记录整个过程的屏幕捕获视频。另外,超声医师为每个受试者保存了许多标准视图的“冻结帧”。这些帧的很大一部分已经注释,允许推断出正确的地面实况(gt)标签。所有视频帧和图像都被下采样到225x273像素的尺寸,以匹配用于后续识别提供的图像的尺寸。基于[7]中的指南考虑了12个标准扫描平面。特别是,选择了以下内容:在心室(vt)和小脑(cb)水平的两个脑部视图、标准腹部视图、横向肾脏视图、冠状唇、中间轮廓、以及股骨和矢状脊视图。还包括四种常见的心脏视图:左心室和右心室流出道(lvot和rvot)、三血管视图(3vv)和4室视图(4ch)。除了标记的冻结帧之外,还从每个视频中采样50个随机帧,以便对背景类进行建模,即“非标准扫描平面”类。因此,提供数据以训练cnn以识别13个不同的元素或类别;上面提到的胎儿器官的12个视图加上不包含12个视图的背景视图。数据集分成包含20%扫描的测试集和包含80%扫描的训练集。10%的培训数据用作验证集来监控培训进度。总共建模了12个标准视图平面,加上一个背景类,结果是k=13个类别。使用小批量梯度下降和分类交叉熵成本函数训练cnn模型。如果发生过度拟合,则可以在c5和c6层之后添加50%的丢失。为了解释背景类别引入的显著的类不平衡,使用偶数类采样创建了小批量。另外,通过采用具有随机水平和/或垂直平移的225×225方形子图像和/或以小的随机旋转和/或沿垂直和/或水平轴翻转来对它们进行变换,每个批次增加了5倍。与在整个视野上进行训练相比,采用随机方形子图像有助于为增强批次引入更多变化。这有助于减少网络的过度拟合。对网络进行了50次的训练,并选择了网络参数,这些参数在验证集上产生了最低的误差。如下面将更详细地提到的,可以使用操作者选择的图像帧来执行进一步的训练。图像识别操作图3是示出根据一个实施例的数据处理器10执行的主要处理步骤的流程图。尽管该实施例描述了获得图像数据的各个帧,但是应当理解,也可以提供成像的三维对象的三维数据集,并且通过作为图像帧提供的该三维数据集的部分或平面。获得图像在步骤s10,获得图像数据。在该实施例中,一次一帧地提供包含输入视频的全视场的视频帧(即225x273像素的有用us数据,包括帧中心,边框被裁剪以排除医院、患者和扫描仪数据)。这些帧可以直接从传感器40提供或从存储器50取回。特征图在步骤s20,将单独的图像帧100(参见图4)提供给cnn以进行处理。这导致13x16的更大的类别特定特征图110。每个帧的预测yk和置信水平ck由具有最高概率和概率本身的预测给出。可以为操作者显示每个特定元素的置信水平,如图6所示,其中示出了要成像的每个元素,以及这些元素的置信水平的图形表示。在该实施例中,这些由一系列条140指示。此外,使用文本160以及置信水平160指示具有最大置信水平的元素。实施例提供了一种交通灯系统,其中针对两个阈值水平评估每个元素的置信水平。当元素的置信水平低于第一阈值水平时,则提供红色指示。当元素的置信水平高于第一阈值水平但低于第二阈值水平时,则提供黄色指示。当元素的置信水平高于第二阈值水平时,则提供绿色指示。可以计算置信水平的变化,并且向操作者提供关于置信水平是增加还是减少的指示,以帮助定位特定元素。帧之间的置信水平和图像移动的变化可以用于导出方向矢量,该方向矢量可以指示给操作者以帮助引导传感器40定位特定元素。在步骤s30,确定该帧的置信水平是否超过特定元素的阈值量,这意味着图像帧提供该元素的合适图像。如果没有置信水平超过阈值量(意味着图像帧不提供任何元素的合适图像),则处理进行到步骤s20,其中将下一帧提供给机器学习算法。如果在步骤s30置信水平超过阈值(意味着图像帧提供至少一个元素的合适图像),则处理进行到步骤s40。显著性图在步骤s40,发生图像增强以帮助操作者识别由cnn识别的元素。在从正向通过网络获得当前帧x的类别k之后,检查对应于预测类别k的特征图fk(即,c6层的输出)。图4提供了两个标准视图示例的概述。给定视频帧(a),训练的卷积神经网络提供预测和置信度值(b)。通过设计,每个分类器输出具有相应的低分辨率特征图(c)。从最活跃的特征神经元反向传播误差形成显著性图(d)。可以使用阈值转换法导出边界框(e)。因此,图4c中示出了特征图110的两个示例。应当理解,特征图fk已经可以用于对类似于[9]的相应解剖结构的位置进行近似估计。然而,代替直接使用特征图,实施例利用原始输入图像的分辨率获得局部显著性。对于特征图中位置p、q处的每个神经元可以计算每个原始输入像素x(i,j)对该神经元的激活贡献了多少。这对应于计算偏导数这可以使用额外的向后传播通过网络有效地解决。[12]提出了一种通过仅允许有助于增加较高层(即,更接近网络输出的层)中的激活的误差信号以引导方式执行该反向传播的方法。特别是,如果神经元x的输入以及高层δl中的误差为正,则误差仅通过每个神经元的relu单元反向传播。也就是说,每个神经元的反向传播误差δl-1由δl-1=δlσ(x)σ(δl)给出,其中σ(·)是单位阶跃函数。与从最终输出反向传播的[12]相反,实施例利用类别特定特征图中的空间编码,并且仅反向传播10%最活跃的特征图神经元的误差,即预测胎儿解剖结构的空间位置。与[12]相比,得到的显著性图120、130明显更加局部化,如图4d和图5所示。特别地,图5示出了从输入帧100(lvot类)获得的显著性图,其显示在左侧。使用来自平均池化层输出的引导反向传播获得中间图140[12]。通过上述实施例获得右侧的图120。这些显著性图120、130可以用作各种图像分析任务的起始点,例如自动分割或测量。特别地,它们可以用于使用图像处理的近似定位。显著性图的绝对值图像|sk|使用25x25高斯核模糊并使用otsu方法应用阈值转换法[10]。然后计算阈值化图像中的分量的最小边界框180。如图4e所示,显著性图120、130可用于增强源图像以突出显示所识别的元素。例如,边界框180可以位于源图像上的所识别元素周围。可选地或另外地,在显著性图内具有大于阈值的像素可以在源图像上着色。可选地或另外地,在显著性图内具有小于阈值的那些像素可以在源图像上设置为恒定值。可选地或另外地,可以显示显著性图本身。可选地或另外地,可以显示显著性图中所示元素的测量值。可选地或另外地,可以显示元素和/或置信水平160的描述150。图像帧存储当超过阈值时,可以询问操作者是否存储所示的图像帧和/或可以自动存储所示的图像帧,通常在存储器50中(具有或不具有图像增强和/或显著性图)。也可以存储还超过阈值的其他图像帧。在一个实施例中,还可以存储未能超过阈值的图像帧-这可以有助于后续学习,如下面将更详细地提到的。对于回顾性帧检索,对于每个主题,计算每个类的置信度并在输入视频的整个持续时间内记录。随后,检索并存储对每个类具有最高置信度的帧。当存储每个元素的图像帧时,这可以向操作者指示(例如使用条140),以便清楚哪些元素仍然是突出的。在步骤s50,确定是否已经捕获了每个所需图像,如果没有,则处理返回到步骤s20,在步骤s20中分析下一个图像帧。如果已经捕获了每个图像,则处理进行到步骤s60,在步骤s60中将捕获的图像显示给操作者。图像选择在步骤s70,操作者为每个元素选择捕获的最佳图像帧,并且通常丢弃未选择的图像帧。如上所述,那些图像帧中的一些可以包括cnn认为不是最佳匹配的图像帧。如果选择其中一个图像帧,那么这可以通过在训练批次中包括那些来帮助重新训练cnn。在步骤s80,然后将由操作者选择的图像添加到用于机器学习算法的离线训练的训练集中。实验结果评估了实施例通过对包括随机采样的背景类别的测试数据进行分类来检测标准帧的能力。达到的精确度(pc)和召回率(rc)得分如表2所示。心脏视图得分最低,这也是专业超声医师最难扫描的。这一事实反映在严重心脏异常的低检出率(例如在英国只有35%)。[2]最近报告腹部标准视图的pc/rc得分为0.75/0.75,us扫描数据中4ch视图的pc/rc得分为0.77/0.61。获得了4ch视图的可比较值,并且腹部视图的值更好。然而,使用12个建模标准平面和徒手us数据,这要复杂得多。使用nvidiateslak80图形处理单元(gpu)实施例能够分类平均每秒113帧(fps),而时钟频率为3.6ghz的intelcorei7达到40fps,尽管可以理解,任何现代gpu都可用于加速分类。表2:精确度pc=tp/(tp+fp)以及召回率rc=tp/(tp+fn)用于建模的扫描平面的分类。背景类:pc=0.96,rc=0.93通过回顾性帧检索,从所有测试受体的视频中检索标准视图,并手动评估检索到的帧是否对应于每个类别的带注释的gt帧。有几个案例没有用于所有视图的gt,因为它们不是原始扫描中超声医师手动包括的。对于这些案例,未评估检索到的帧。结果总结在表3中。表3:所有201个测试受体的每个标准视图的正确检索帧的百分比两个志愿者的检索帧的示例在图7中示出,其示出了由专业超声医师为两名志愿者注释并保存的检索标准帧(ret)和gt帧。正确检索和错误检索的帧分别用复选标记或十字标记注释。指示没有gt注释的帧。置信度显示在每张图像的右下角。(b)中的帧还包含根据实施例的定位结果(框)。在许多情况下,检索到的平面几乎完全匹配专家gt。此外,一些未经专家注释的平面仍然被正确找到。和以前一样,与其他观点相比,大多数心脏视图得分较低。对于一个代表性案例,在所检索的帧中相应胎儿解剖结构的近似定位的结果显示在图7b中。执行本地化平均将帧速率降低到39fps。应当理解,在其他实施例中,可以提供表示对象的三维图像的数据集。在那些实施例中,可以提供来自该数据集的图像帧。例如,可以提供第一组图像帧,其表示通过数据集的平行部分。然后可以提供另外的图像帧集,其表示通过与其他集正交的数据集的平行部分。组合来自每个序列的显著性图,并且执行三维(例如,霍夫)变换以通过包含该指定元素的三维数据获得平面的参数。因此,实施例提供了一种用于从真实临床胎儿us扫描中自动检测十二个胎儿标准扫描平面的系统。采用的完全cnn架构允许强大的实时推断。此外,通过将类别特定的特征图中的信息与引导的反向传播步骤组合来获得局部显著性图。这使得能够从大量的徒手us扫描中对大量胎儿标准视图进行建模。但是在更具挑战性的情况下,该方法可用于对us数据进行鲁棒性注释,其分类得分超过某些标准平面的相关工作中报告的值。实施例可以潜在地用于辅助或训练没有经验的超声医师。实施例可用于回顾性地检索标准扫描平面。以这种方式,可以从由没有经验的操作者获取的视频中提取相关的关键帧,并将其发送给专家进行进一步的分析。局部显著性图也可用于提取胎儿解剖结构的近似边界框。实施例提供了一种实时系统,其可以在临床徒手2dus数据中自动检测12个通常获取的标准扫描平面。已经证明检测框架用于(1)us数据的实时注释以辅助超声医师,以及(2)用于从完整检查的记录中回顾性检索标准扫描平面。实施例采用完全卷积神经网络(cnn)架构,其允许以每秒超过100帧的鲁棒扫描平面检测。此外,该架构被扩展以获得显著性图,突出显示对预测贡献最大的图像部分(参见图4)。这种显著性图提供了相应胎儿解剖结构的定位,并且可以用作进一步自动处理的起点。该定位步骤是无人监督的,并且在训练期间不需要地面实况边界框注释。针对大型胎儿图像数据库提出了7个平面的标准扫描平面分类[13]。这与实施例显著不同,因为在那种情况下已知每个图像实际上是标准平面,而在视频数据中,大多数帧不显示标准平面。许多论文已经提出在胎儿2dus扫描视频中检测胎儿解剖结构的方法(例如[6])。在这些工作中,作者的目的是检测胎儿结构的存在,如头骨、心脏或腹部,而不是特定的标准化扫描平面。已经在2d胎儿us扫描中证实了1-3个标准平面的自动胎儿标准扫描平面检测[2,3,8]。[2,3]也采用了cnn。通过一次连续运动将us探针从子宫颈向上移动来获得us扫描[3]。然而,并非所有用于确定胎儿健康状态所需的标准视图都使用扫描协议充分可视化。例如,可视化股骨或嘴唇通常需要仔细的手动扫描平面选择。此外,使用扫描协议获得的数据通常只有2-5秒长,并且由少于50帧组成[3]。据信,从未对真正的徒手us数据执行胎儿标准扫描平面检测,该数据通常由10,000+帧组成。此外,没有相关的工作证明是实时运行的,通常每帧需要多秒。如上所述,胎儿中期妊娠扫描通常根据固定协议进行。准确检测异常并纠正生物特征测量取决于正确采集明确定义的标准扫描平面。定位这些标准平面需要高水平的专业知识。然而,世界范围内缺乏专业超声医师。因此,实施例提供了基于卷积神经网络的全自动系统,其可以检测由uk胎儿异常筛选程序定义的12个标准扫描平面。网络设计允许实时推断并且可以自然地扩展以提供图像中胎儿解剖结构的近似定位。这样的框架可用于自动化或辅助扫描平面选择,或用于从记录的视频中回顾检索扫描平面。该方法在1003名志愿者怀孕中期扫描的大型数据库中进行评估。结果表明,在临床情况下获得的标准平面可以精确地检测到,精确度和召回率分别为69%和80%,优于现有技术。此外,实施例回顾性地检索正确的扫描平面,对于心脏视图具有71%的准确度,对于非心脏视图具有81%的准确度。因此,可以看到,实施例提供了一种系统,其能够:自动检测胎儿标准扫描平面的存在(或不存在);预测可以以超过流2dus数据的速率获得,即实时地;预测可以在屏幕上显示给us操作员进行计算机辅助扫描;可以获得用任意手部运动获得的序列的预测(即,不需要固定的采集协议);标准扫描平面可以实时自动提取,也可以从记录的2dus流数据集中自动提取;每个检测到的标准扫描平面都可以被标记(也是实时的),并且具有该视图的置信度;置信度可以用来开发一个“交通灯系统”(绿色、橙色、红色),表明特定视图何时令人满意(绿色),并应记录以执行标准测量;产生“显著性”图像,可视化属于特定标准视图的胎儿解剖结构;显著性图像可以以超过流2dus数据的速率获得;屏幕视图可以通过显著性图像来增强,例如以热图的形式可视化胎儿解剖结构的可能位置;和/或近似指示胎儿解剖位置的边界框的提取:(1)增大屏幕视图,(2)创建包含解剖结构的裁剪图像,用于随后的图像分析,例如,骨骼的轮廓。以上所有要点都具有自动分析非专家获取的视频的潜在应用,例如,在未经训练的操作者进行大量扫描的发展中国家中。系统可以向us操作者指示移动探针的方向以便到达特定视图。该系统可以提供机器人手臂的自动引导。例如,将探针移向包含特定视图的更高置信区域。因此,实施例执行:检测3d体积中的标准视图(存在哪些标准视图?);从3d体积(如果存在)中提取一个或多个2d标准视图并显示给us操作者;有能力实时完成上述任务。尽管本文已经参考附图详细公开了本发明的说明性实施例,但是应当理解,本发明不限于精确的实施例,并且本领域技术人员可以在其中实现各种改变和修改而不脱离由所附权利要求及其等同物限定的本发明的范围。参考文献[1]bull,c.,etal.:currentandpotentialimpactoffoetaldiagnosisonprevalenceandspectrumofseriouscongenitalheartdiseaseattermintheuk.thelancet354(9186),1242–1247(1999)[2]chen,h.,dou,q.,ni,d.,cheng,j.z.,qin,j.,li,s.andheng,p.a.:automaticfoetalultrasoundstandardplanedetectionusingknowledgetransferredrecurrentneuralnetworks.in:procmiccai,pp.507–514.springer(2015)[3]chen,h.,ni,d.,qin,j.,li,s.,yang,x.,wang,t.,heng,p.:standardplanelocalizationinfoetalultrasoundviadomaintransferreddeepneuralnetworks.ieeejbiomedhealthinform19(5),1627–1636(2015)[4]kurinczuk,j.,hollowell,j.,boyd,p.,oakley,l.,brocklehurst,p.,gray,r.:thecontributionofcongenitalanomaliestoinfantmortality.nationalperinatalepidemiologyunit,universityofoxford(2010)[5]lin,m.,chen,q.,yan,s.:networkinnetwork.arxiv:1312.4400(2013)[6]maraci,m.,napolitano,r.,papageorghiou,a.,noble,j.:searchingforstructuresofinterestinanultrasoundvideosequence.in:procmlmi,pp.133–140(2014)[7]nhsscreeningprogrammes:fetalanomaliescreenprogrammehandbookpp.28–35(2015)[8]ni,d.,yang,x.,chen,x.,chin,c.t.,chen,s.,heng,p.a.,li,s.,qin,j.,wang,t.:standardplanelocalizationinultrasoundbyradialcomponentmodelandselectivesearch.ultrasoundmedbiol40(11),2728–2742(2014)[9]oquab,m.,bottou,l.,laptev,i.,sivic,j.:isobjectlocalizationforfree?-weakly-supervisedlearningwithconvolutionalneuralnetworks.in:ieeeproccvpr.pp.685–694(2015)[10]otsu,n.:athresholdselectionmethodfromgray-levelhistograms.automatica11(285-296),23–27(1975)[11]salomon,l.,alfirevic,z.,berghella,v.,bilardo,c.,leung,k.y.,malinger,g.,munoz,h.,etal.:practiceguidelinesforperformanceoftheroutinemid-trimesterfoetalultrasoundscan.ultrasoundobstgyn37(1),116–126(2011)[12]springenberg,j.,dosovitskiy,a.,brox,t.,riedmiller,m.:strivingforsimplicity:theallconvolutionalnet.arxiv:1412.6806(2014)[13]yaqub,m.,kelly,b.,papageorghiou,a.,noble,j.:guidedrandomforestsforidentificationofkeyfoetalanatomyandimagecategorizationinultrasoundscans.in:procmiccai,pp.687–694.springer(2015)当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1