基于FPGA加速卷积神经网络框架的图片处理方法与流程
本发明属于计算机设计技术领域,特别涉及一种卷积神经网络实现方法,可用于图像分 类、目标识别、语音识别和自然语言处理。
背景技术:
随着集成电路设计和制造工艺的进步,具有高速、高密度可编程逻辑资源的现场可编程 门阵列得到了快速发展,单个芯片的集成度越来越高。为了进一步提高FPGA性能,主流 的芯片厂商在芯片内部集成了具有高速数字信号处理能力的数字信号处理芯片DSP定制计 算单元,DSP硬核是能够高效低成本的实现定点运算部件,使得FPGA在视频与图像处 理、网络通信与信息安全、生物信息学等应用领域被广泛采用。
卷积神经网络CNN是人工神经网络的一种结构,广泛的应用于图像分类、目标识别、 语音识别、自然语言处理等等领域,在近几年时间内,随着计算机能力的大幅度提升以及神 经网络结构的发展,CNN的性能和准确率大幅度提升,但是对于运算单元的并行计算能力 要求也越来越高,因此具有并行计算能力的GPU,FPGA成为一个主流方向。
基于FPGA的可配置计算体系结构能够开发人工神经网络的并行性并通过配置来改变 卷积神经网络的权重和拓扑结构。用FPGA实现的人工神经网络既有软件设计的灵活性又在 计算性能上接近专用集成电路ASIC,同时利用片上可编程连线资源还可以实现高效的互联, 因此FPGA是硬件实现人工神经网络的一种重要选择。
目前的专利和研究方向中,基本以OpenCL编程语言作为构建核心,目的在于减少卷积 神经网络算法转换为硬件描述语言的实现时间,但并没有涉及对于FPGA算法中的硬件描述 语言代码的加速,同时由于OpenCL编程语言并不是实际在FPGA上运行的语言,所以在实 际的FPGA运行速度并不理想。目前基于OpenCL编程实现的现有技术中,主要集中于FPGA 中DSP模块的加速,并没有对卷积神经网络算法进行整体实现和对底层硬件描述语言的优 化,不能充分的利用FPGA的计算资源,导致FPGA计算时间增加,加速效果不明显。
技术实现要素:
本发明的目的在于提出一种基于FPGA加速的卷积神经网络实现方法,以通过硬件描述 语言对卷积神经网络进行整体实现,并对底层硬件描述语言的进行优化,充分利用FPGA运 算资源,实现FPAG加速效果的最大化。
为实现上述目的,本发明的技术方案包括如下:
(1)参数处理:
1a)读取用户输入的图片和FPGA板子资源参数,该资源参数包括:图片大小N,总块 ram资源Ssum,同步动态动态随机存取内存DDR3数目P和计算功能芯片DSP数目A;
1b)设计FPGA运算频率f,卷积核大小m、卷积层数J、通道数T、池化层数C、激活 函数层数E、多分类函数softmax层数G、softmax层输入数Iin、softmax层输出数Iout、全连 接层数Q、池化函数、激活函数;
1c)根据1a)读取的数据和1b)设计的参数,计算每层图片大小值集合X,最大卷积 可并行数L,理论运算速度带宽D,理论数据传输带宽Z;
(2)计算图片分割的固定值:
2a)根据(1)中计算得到每层图片大小值集合X,计算每层图片大小公约数M;
2b)根据2a)得到的公约数和(1)中读取的总块ram资源Ssum,计算满足FPGA的块 ram资源限制的图片公约数C;
2c)根据2b)得到的资源限制公约数和(1)中读取的DSP资源,计算满足DSP资源 限制的最大公约数作为图片分割固定值n;
(3)确定DDR3数目:
根据图片分割固定值n计算实际数据传输带宽H,并将该实际数据传输带宽H与理论数 据传输带宽Z进行比较:
如果H>Z,则确定DDR3的数目B为2或者1+2j,j≥1的整数
如果H≤Z,则确定DDR3的数目B为3或者1+4i,i≥1的整数;i≠j
(4)对FPGA上的块ram进行资源分配:
4a)根据(2)确定的图片分割固定值n和(1)中的通道数T,计算图片存储块ram资 源Spic;
4b)根据4a)的图片存储块ram资源Spic和(1)中总块ram资源Ssum,计算余下的块 ram存储资源Slast,以及最大存储参数块ram资源Sne,并比较两者大小:如果Slast≥Sne,则 将Sne作为参数存储块ram资源Spar,如果Slast<Sne,则将Slast减去0.5Mbit,作为参数存储块 ram资源Spar;
(5)构建卷积神经网络框架,结合上述1a),1b),2c),(3),4a),4b)中的参 数对输入的图片进行处理:
5a)设置图片存储模块,用于根据2c)、4a)和(3)中的图片分割固定值n、卷积层数 J、通道数T、图片存储块ram资源Spic和DDR3数目B,实现从DDR3中取出输入图片的像 素点并存储;
5b)设置图片数据分配模块,用于根据2c)、4a)和4b)的图片分割固定值n、图片存 储块ram资源Spic和参数存储块ram资源Spar,对5a)存储的图片数据进行分配;
5c)设置卷积模块,用于根据2c)的图片分割固定值n,对5b)中的分配图片数据进行 卷积计算功能;
5d)设置池化模块,用于根据1b)的池化函数,实现对5c)卷积计算之后的图片数据 进行池化处理;
5e)设置图片存回模块,根据(3)和2c)中的DDR3数目B和图片分割固定值n,将 5d)中池化处理之后的图片数据存回DDR3中;
5f)设置指令寄存组模块,根据1a)、1b)和2c)中的图片大小N,卷积核大小m、卷 积层数J、池化层数C、激活函数层数E、softmax层数G、softmax层输入数Iin、softmax层 输出数Iout、全连接层输出值Q,图片分割大小n,构建控制指令并分配给5a)、5b)、5c)、 5d)、5e)所设置的模块。
本发明与现有技术相比具有如下优点:
1.本发明通过硬件描述语言实现了基于FPGA加速的卷积神经网络框架;
2.本发明通过参数处理中的图片分割固定值n和卷积模块的流水线结构,保证了利用最 多的DSP资源,并保证了卷积计算不间断,通过计算不间断,可使DSP资源和传输效率最大 化,实现了卷积神经网络框架的加速效果;
3.本发明通过对图片存储模块中的图片分割,保证了DDR3传输带宽处于最大值,实现 传输效率最大化;
4.本发明通过指令寄存组模块,更改参数处理中的设计参数,可实现具有不同图片大小N,不同卷积层数J参数的卷积神经网络。
附图说明
图1是本发明的实现流程图;
图2是本发明实施例的仿真结果图。
具体实施方式
下面结合附图对本发明实施例和效果进行详细描述;
步骤1,处理参数。
1.1)读取用户输入的图片和FPGA板子资源参数,FPGA参数包括:图片大小N,总块 ram资源Ssum,同步动态动态随机存取内存DDR3数目P和计算功能芯片DSP数目A;
1.2)设计参数,其包括:FPGA运算频率f,卷积核大小m、卷积层数J、通道数T、池 化层数C、激活函数层数E、多分类函数softmax层数G、softmax层输入数Iin、softmax层 输出数Iout、全连接层数Q、池化函数和激活函数;
1.3)计算机根据读取的参数值,计算每层图片大小值集合X,最大卷积可并行数L,理 论运算速度带宽,理论数据传输带宽:
1.3a)通过如下公式,求每层图片大小值集合X:
X=N/2i+2 i=0,1,2...
其中,N为1.1)的图片大小,X和i均为整数;
1.3b)通过如下公式,求最大可并行数L:
其中,A为1.1)的DSP资源数目,m为1.2)的卷积核大小;
1.3c)通过如下公式,求最大运算速度带宽D:
D=f×m2×32×L,
其中,f为1.2)的FPGA运算频率,m为1.2)的卷积核大小,L为1.3b)的最大可并 行数目;
1.3d)通过如下公式,求数据传输带宽Z:
Z=4×(P-1),
其中,P为1.2)的DDR3个数;
步骤2,计算图片分割固定值。
2.1)通过如下公式,求每层图片大小公约数M:
M=GCD(X)
其中,X为1.3a)的每层图片大小值集合,GCD()表示取公约数;
2.2)通过如下公式,求满足块ram资源限制的图片公约数C:
C=max(M)
st.
其中,M为2.1)的每层图片大小公约数,T为1.2)的通道数,m为1.2)的卷积大小,
Ssum为1.2)的FPGA中块ram大小,max()为取最大值;
2.3)通过如下公式,求满足DSP资源限制的图片分割固定值n:
n=max(C)<L,
其中,C为2.2)的图片公约数C,L为1.2)的最大可并行数。
步骤3,确定DDR3数目
3.1)通过如下公式,求实际数据传输带宽H:
H=n2×32×max(T),
其中,n为2.3)的图片分割固定值,T为1.2)的通道数;
3.2)比较实际数据传输带宽H与理论数据传输带宽Z的大小,求DDR3数目B:
如果H>Z,则确定DDR3的数目B为2或者1+2j,j为大于等于1的整数;
如果H≤Z,则确定DDR3的数目B为3或者1+4i,i为大于等于1的整数;i≠j,Z 为1.2)的理论数据传输带宽。
步骤4,对FPGA上的块ram资源进行分配。
4.1)通过如下公式,求图片存储块ram资源Spic:
Spic=max(M)×max(T)×32,
其中,M为2.1)的每层图片大小公约数,T为1.2)的通道数;
4.2)通过如下公式,求余下块ram存储资源Slast:
Slast=Ssum-2×Spic,
其中,Spic为4.1)的图片存储块ram资源,Ssum为1.1)的FPGA块ram大小;
4.3)求存储参数块ram资源Sne:
4.3a)通过如下公式,求中间变量U
其中,n为2.3)的图片分割固定值n,,X为1.3a)每层图片大小值集合X,T为1.2) 的通道数,max()为取最大值;
4.3b)通过如下公式,求存储参数块ram资源Sne:
其中,U是4.3a)的中间变量,Ssum为1.1)的块ram大小,Spic为4.1)的图片存储块 ram资源,Slast为4.2)余下块ram存储资源;
步骤5,设置图片存储模块。
5.1)将B个DDR3分成两部分,并将B-1个DDR3作为存储图片像素点,其余1
个DDR3作为存储参数,B为3.2)的DDR3数目;
5.2)每次从B-1个DDR3的每个DDR3中各取长为n,宽为矩阵大小的图片像素点, 共取T次,其中取图片像素点的起始地址从0开始,每次取完T次图片之后,起始地址自增 n-1,取完T次之后,起始地址归0,T为1.2)的通道数,n为2.3)的图片分割固定值;
5.3)将从DDR3里面取出来的图片像素点存储于Spic大小的块ram资源中,存储地 址从0开始,依次递增加1,Spic为4.1)的图片存储块ram资源;
5.4)重复步骤5a2)-5a3)共J次,J为1.2)的卷积层数。
步骤6,设置图片数据分配模块。
6.1)构建m×(n+1)的寄存器组,其中将前m×n的寄存器组作为计算组,将最后m×1寄 存器组作为缓存组,n为2.3)的图片分割固定值,m为1.2)的卷积核大小;
6.2)在图片存储块ram资源中取长为m,宽为n的矩阵大小图片数据,存储于6.1)构 建的计算组中,其中取图片数据的起始地址是从0开始,每次取完图片数据后,起始地址增 加m,m为1.2)的卷积核大小,n为2.3)的图片分割固定值。
6.3)计算组每次将长宽为n的图片数据输出到卷积模块中,同时从图片存储块ram中 取长为m,宽为1的图片数据,存入到缓存组中,其中取地址从0开始,每次自动加1,当 计算组输出m-1次后,舍弃计算组的第一行寄存器数据,计算组第二行寄存器数据向第一行 寄存器赋值,第三行寄存器数据向第二行寄存器赋值,同理,其他行依次向上一行寄存器赋 值,m为1.2)的卷积核大小。
步骤7,设置卷积模块。
将步骤6输入的长宽为n的矩阵图片数据输入到n2个DSP中,进行两两相乘,并采用 流水线结构,将相乘后的数据进行相邻两两相加,完成卷积计算,将卷积计算结果输入池化 模块,其中n为2.3)的图片分割固定值;
所述流水线结构,是指在系统处理数据时,每个时钟脉冲都接受下一条处理数据的 指令。
步骤8,设置池化模块。
获取步骤7输入的图片数据,根据输入的顺序,将每4个图片数据进行任意两两相减,
得出6个结果,并判断这6个结果的数据最高位是否为1:
如果是1,则将减数去掉,
如果是0,将被减数去掉,依次对这6个结果进行处理,最后剩下的一个图片数据是 这4个图片数据中的最大值,并将该最大值传递给图片存回DDR3模块。
步骤9,设置图片存回DDR3。
将步骤8的图片数据存储于块ram资源Spic中,从块ram资源Spic中取出长为n,宽为的图片数据,存储回DDR3中,其中取图片数据地址从0开始,每次自动递增加1,存DDR3 地址从0开始,每次自动递增加8,其中n为2.3)的图片分割固定值,B为3.2)的DDR3数 目。
步骤10,设置指令寄存器组。
10.1)构建长为128,宽为J+C+G+Q+1的寄存器组来存储控制指令,其中J为1.2) 的卷积层数,C为1.2)的池化层数,G为1.2)的softmax层数,Q为1.2)的全连接层输出 值;
10.2)构建128位的二进制码控制指令:该指令按从高到底的顺序依次是:10位的输入 图片大小N、8位的图片分割大小n、4位的卷积核大小m、6位的卷积层数J、6位的池化 层数C、4位的激活函数层数E、4位的softmax层数G、16位的softmax层输入数Iin、16 位的softmax层输出数Iout及54位的全连接层输出值Q,其中N为1.1)输入图片的大小值, n为2.3)的图片分割固定值,m为1.2的卷积核大小m,J为1.2)的卷积层数,C为1.2) 的池化层数,E为1.2)的激活函数层数,G为1.2)的softmax层数,Iin为1.2)softmax层 输入数,Iout为1.2)softmax层输出数,Q为1.2)全连接层输出值;
10.3)通过握手信号,将控制指令同时传递给步骤5-9所设置的模块。
所述握手信号,是指两个模块在通信之前,模块要互相的确认使能信号,然后才能互相 传送数据。
本发明的效果可通过以下仿真进一步说明。
1.仿真条件
本次仿真使用紫光同创的FPGA平台,型号PGT180H;
计算机读取用户输入的FPGA资源参数以及设计参数:
FPGA资源参数包括:图片大小N=224,总块ram资源Ssum=9.2M,同步动态动态随机 存取内存DDR3数目P=3和计算功能芯片DSP数目A=424。
设计参数包括:FPGA运算频率f=150M,卷积核大小m=3、卷积层数J=8、通道数T=524、 池化层数C=8、激活函数层数E=8、多分类函数softmax层数G=2、softmax层输入数Iin=5120、 softmax层输出数Iout=1024、全连接层数Q=100、池化函数为最大值池化函数、激活函数为 线性修正relu激活函数;
2.仿真内容
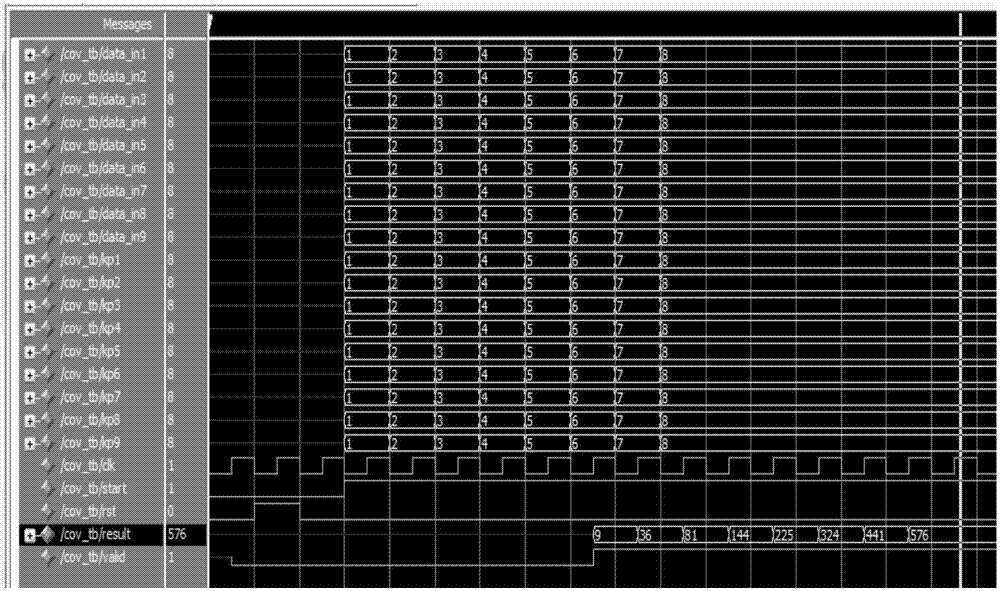
仿真1,通过MODLESIM软件,基于以上参数,用本发明方法在150M的时钟频率下, 对输入长宽为N=224,像素点大小均为1的图片进行仿真处理,得到卷积模块的输出结果, 如图2所示。
从图2可见,卷积模块的输出结果值为9,36,81,144...,符合在cpu中,输入同样图 片和设计参数的情况下,卷积神经网络算法的结果,验证得本方法可以正确实现卷积神经网 络结构。
仿真2,通过MODLESIM软件,基于以上参数,用本发明方法在150M的时钟频率下, 对输入长宽为N=224的图片进行仿真处理,得到仿真时间和FPGA的资源利用率,如表1 所示。
从下表1可见,仿真时间为0.4s,时钟频率最高为187MHz,DDR3带宽为3.73Gbit/s, 实现了传输效率最大化;DSP数目为390,其资源利用率为87%,块ram资源为9.1M,其 资源利用率为98.9%,最终计算速度为6.2Gbit/s,实现了卷积神经网络框架的加速效果。
表1
- 还没有人留言评论。精彩留言会获得点赞!