一种基于深度学习的隧道裂缝快速识别方法与流程
本发明涉及一种隧道裂缝快速识别方法,并公开一种基于深度学习的隧道裂缝快速识别方法,应用于地下工程领域。
背景技术:
随着科技的进步和社会的发展,隧道工程的建设规模与日俱增,大大方便了人们的出行和生活,如地铁隧道、铁路隧道、公路隧道等,而大部分已建成的隧道工程已进入养护维修阶段,因此,随着隧道数量持续增加,隧道结构的运营状态与病害检测也变得尤为重要。在隧道的运营过程中,由于受到车辆的振动、周边荷载的扰动、围岩压力变化等影响,隧道表面会出现裂缝,裂缝不仅导致混凝土层对内部钢筋保护失效,还可能会导致混凝土掉落,造成行车安全问题,严重的裂缝更是隧道坍塌的前兆,因此隧道裂缝检测是隧道日常运营状态与病害检测的主要项目之一。
目前的隧道裂缝检测方法主要有:人工观察、数字图像处理识别、雷达检测法等。相对于其他两种方法,数字图像处理识别方法,尤其是基于深度学习的隧道裂缝检测方法具有实时性高,精度高,鲁棒性高等优点,已成为隧道裂缝检测业务的主流方法。近年来,有许多学者对基于深度学习的裂缝检测展开了研究。
公开号为CN106910186A的专利文献,公开了一种基于CNN深度学习的桥梁裂缝检测定位方法,该方法使用55000张16*16像素大小的图像集训练一个包含四个卷积层和两个全连接层的神经网络,并采用滑动窗口和高斯图像金字塔下采样方法对待检测图像进行检测,输出裂缝的外接矩形框坐标和像素级面积。
公开号为CN106841216A的专利文献,公开了基于全景图像CNN的隧道病害自动识别装置,该方法首先通过全景视觉传感器获取隧道内壁全景图像,然后使用传统数字图像处理技术提取出疑似病害的图像,最后通过卷积神经网络对疑似病害的图像进行检测,并输出被检测图像存在裂纹、裂缝、衬砌脱落、渗漏水四种病害类型的概率。
以上文献公开的裂缝检测方法,都没有直接输出裂缝分割的结果,因此无法直接获取裂缝的长度和宽度信息,而是裂缝的长度和宽度信息是裂缝病害等级评估的重要指标。以上方案获取裂缝的长度和宽度信息需要增加后处理方法(如图像分割),增加了裂缝检测流程和时间成本,同时后处理方法的效果直接影响着裂缝的长度和宽度信息的准确度,降低了整个裂缝检测系统的鲁棒性。因此,有必要通过端对端的卷积神经网络直接输出裂缝分割的结果,以直接获取裂缝的长度和宽度信息,以提高效率和鲁棒性。
技术实现要素:
针对目前基于深度学习的裂缝检测方法无法直接获取裂缝的长度和宽度信息的问题,本发明提供了一种基于深度学习的隧道裂缝快速识别方法,用于隧道裂缝检测,以提高隧道裂缝检测工作的效率。
本发明的技术方案:一种基于深度学习的隧道裂缝快速识别方法,其特征在于,包括以下步骤:
S1、创建深度学习图像训练集。
所述步骤S1的具体操作如下:
(1)采集隧道图像:通过移动检测装备拍摄隧道表面得到单通道的隧道图像,其分辨率一般要求不低于200万像素,图像的清晰度要求足够高,图像中的裂缝最小宽度不低于1像素;
(2)通过人工筛查隧道图像,选出5万张裂缝图像和5万张非裂缝图像,并调整图像大小,图像格式与原始隧道图像一致。原始隧道图像记为I,宽和高记为(W,H),调整后的图像记为I’,宽和高记为(w’,H’);
(3)使用Photoshop软件打开调整大小后的裂缝图像,并通过“快速选择”工具选出裂缝区域,记为,非裂缝区域记为;
(4)选出的裂缝区域标记为1,并设置裂缝区域填充颜色为白色。非裂缝区域标记为0,并设置非裂缝区域填充颜色为黑色;
(5)裂缝和非裂缝区域颜色填充完成后,保存为训练集标签图像,记为,其格式与原始隧道图像I一致,大小为(w’,H’)。
S2、训练深度卷积神经网络模型。
所述步骤S2的具体操作如下:
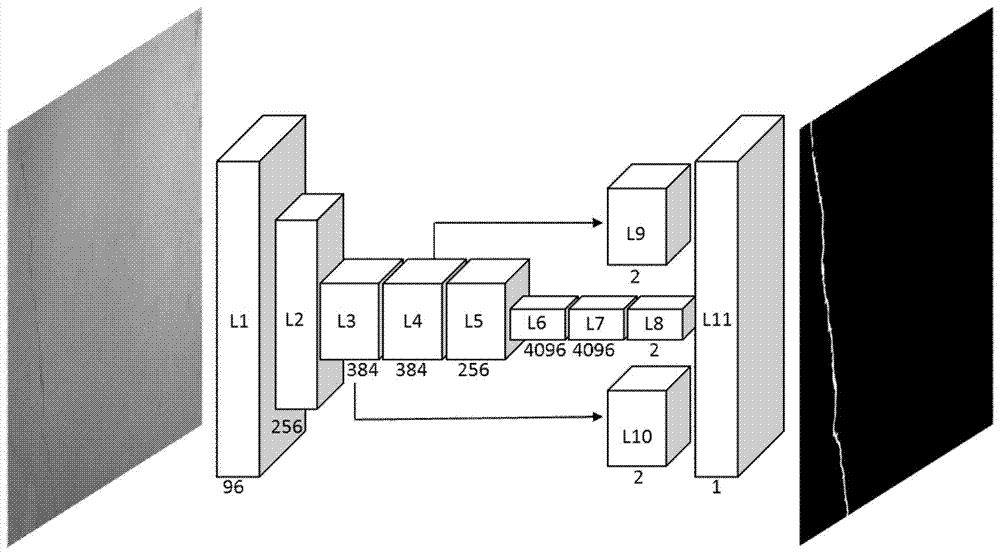
(1)搭建卷积神经网络结构:卷积神经网络通过改进AlexNet结构来实现,把3个全连接层换成3个卷积层,增加1个反卷积层,改进后的网络由10个卷积层,5个池化层,1个Dropout层,1个反卷积层,10个卷积层记为C1~C10,5个池化层记为P1~P5,1个反卷积层记为DC1。卷积层C1~C10的卷积核大小(宽,高,通道数)依次为(11,11,1)、(5,5,96)、(3,3,256)、(3,3,384)、(3,3,384)、(1,1,256)、(1,1,4096)、(1,1,4096)、(1,1,384)、(1,1,384)。反卷积层DC1使用插值方法对C8~C10输出的热力图进行上采样并整合,其中插值方法初始化为双线性插值法,其参数可以通过反向传播来学习。卷积神经网络的代价函数选择softmax loss函数,激活函数选择矫正线性单元(Rectified linear unit,ReLU)函数。为了防止卷积神经网络模型过拟合,在代价函数中加入权值衰减(weight decay)正则化项,并在第6个卷积层C6后加入Dropout层,Dropout比例设为0.5;
(2)选择训练策略:卷积神经网络训练使用随机梯度下降方法进行优化求解,实现模型参数更新,并使用动量方法(momentum)、批正则化方法来加速学习过程;
(3)选择深度学习库:使用深度学习库Caffe实现以上所述的卷积神经网络结构,并根据已选择的训练策略和图像训练集进行训练。
S3、使用训练好的卷积神经网络模型对待检测图像进行检测并输出预测标签图像,记为。
所述步骤S3的具体操作如下:
(1)选择一张隧道图像作为待检测图像,并使用双线性插值方法把待检测图像大小调整至(w’,H’)像素,其中待检测图像的采集要求与深度学习训练集图像一致;
(2)调用Caffe的C++接口加载训练好的卷积神经网络模型,对待检测图像进行推理预测,输出预测标签图像。
S4、根据预测标签图像输出检测结果,包括图像类别(有无裂缝)、裂缝的坐标信息以及裂缝的像素级宽度值和长度值,其中图像类别记为Class,裂缝的坐标信息记为,裂缝的像素级宽度值和长度值分别记为Wpixel、Lpixel。
所述步骤S4的具体操作如下:
(1)使用双三次插值方法把预测标签图像大小调整至隧道原始图像大小(W,H),调整后的预测标签图像记为, 其格式与I一致;
(2)遍历预测标签图像中所有连通域,即裂缝区域,使用连通域面积最小化策略提取裂缝区域的外接矩形,并计算外接矩形的宽高比,记为。若大于或等于线性判定阈值,标记为有效裂缝区域;若小于线性判定阈值,则标记为无效裂缝区域,其中线性判定阈值记为。若预测标签图像中无有效裂缝区域,图像类别Class设为0;否则图像类别Class设为1;
(3)遍历有效裂缝区域,提取其轮廓点坐标集,记为,轮廓点坐标的个数记为,并计算其外接矩形长边的角度,记为。计算方法如下:
(1)
其中,和是外接矩形长边的两个端点坐标;
(4)计算裂缝的像素级长度。对裂缝区域的轮廓点坐标集进行抽样,抽样间隔记为,抽样后的轮廓点坐标的个数记为。根据抽样后的轮廓点坐标集计算裂缝的像素级长度值,计算方法如下:
(2)
(5)计算裂缝的像素级宽度。对裂缝区域的轮廓点坐标集进行抽样,抽样间隔记为,抽样后的轮廓点坐标集记为,轮廓点坐标的个数记为。根据抽样后的轮廓点坐标集计算裂缝的像素级宽度值,具体的计算步骤如下:
(a)把抽样后的各轮廓点位置的裂缝像素级宽度值初始化为0;
(b)遍历抽样后的轮廓点坐标集,计算相邻两点的角度值,记为。比较和,若两者间的误差绝对值大于或等于角度偏差阈值,那么放弃计算当前轮廓点位置的裂缝的像素级宽度值,遍历下一个轮廓点,角度偏差阈值记为。若两者间的误差绝对值小于角度偏差阈值,则计算出当前轮廓点位置的裂缝的像素级宽度值。各轮廓点位置的裂缝的像素级宽度值记为,计算方法如下:
其中,。
(c)裂缝的像素级宽度值后处理。首先去除中的零值,然后计算的平均值,取此平均值作为最终的裂缝的像素级宽度值。
S5、根据检测结果输出病害记录结果,若待检测图像中存在裂缝,则记录图像名称、裂缝的坐标信息以及裂缝的实际宽度值和长度值;若待检测图像中没有裂缝,则不记录。其中裂缝的实际宽度值和长度值分别记为wreal、Lreal,计算方法如下:
其中,是尺度变换系数,表示图像中单个像素对应的实际距离值,一般可取0.2 mm/pixel。
与现有技术相比,本发明具有以下优点:(1)本发明能够直接输出裂缝分割预测结果,简化了裂缝病害检测流程,效率更高。(2)本发明使用改进的卷积神经网络实现端到端的裂缝识别,鲁棒性和准确率更高。(3)本发明能够直接获取裂缝的长度和宽度信息,且精度高,这对裂缝病害等级评估至关重要。
附图说明
图 1 是本发明方法的裂缝识别处理流程示意图。
图 2 是本发明方法的卷积神经网络结构图。
图 3 是本发明方法的裂缝宽度计算原理示意图。
具体实施方式
下面结合附图对本发明作进一步详细说明。
根据附图1,本发明是一种基于深度学习的隧道裂缝快速识别方法,其特征在于,所述的隧道裂缝快速识别方法包括以下步骤:
S1、创建深度学习图像训练集。
所述步骤S1的具体操作如下:
(1)采集隧道图像。通过移动检测装备拍摄隧道表面得到单通道的隧道图像,其分辨率一般要求不低于200万像素,图像的清晰度要求足够高,图像中的裂缝最小宽度不低于1像素;
(2)通过人工筛查隧道图像,选出5万张裂缝图像和5万张非裂缝图像,并调整图像大小,图像格式与原始隧道图像一致。原始隧道图像记为I,宽和高记为(W,H),调整后的图像记为I’,宽和高记为(w’,H’);
其中图像的宽和高根据相机的分辨率来设定,(W,H)一般为(2560,2048),(w’,H’)设为(2048,2048);
(3)使用Photoshop软件打开调整大小后的裂缝图像,并通过“快速选择”工具选出裂缝区域,记为,非裂缝区域记为;
(4)选出的裂缝区域标记为1,并设置裂缝区域填充颜色为白色。非裂缝区域标记为0,并设置非裂缝区域填充颜色为黑色;
(5)裂缝和非裂缝区域颜色填充完成后,保存为训练集标签图像,记为,其格式与原始隧道图像I一致,大小为(w’,H’);
图像训练集分成训练集、验证集和测试集三个部分,分配比例设为0.7:0.2:0.1。
S2、训练深度卷积神经网络模型。
所述步骤S2的具体操作如下:
(1)根据附图2,搭建卷积神经网络结构:卷积神经网络通过改进AlexNet结构来实现,把3个全连接层换成3个卷积层,增加1个反卷积层,改进后的网络由10个卷积层,5个池化层,1个Dropout层,1个反卷积层,10个卷积层记为C1~C10,5个池化层记为P1~P5,1个反卷积层记为DC1。卷积层C1~C10的卷积核大小(宽,高,通道数)依次为(11,11,1)、(5,5,96)、(3,3,256)、(3,3,384)、(3,3,384)、(1,1,256)、(1,1,4096)、(1,1,4096)、(1,1,384)、(1,1,384)。反卷积层DC1使用插值方法对C8~C10输出的热力图进行上采样并整合,其中插值方法初始化为双线性插值法,其参数可以通过反向传播来学习。卷积神经网络的代价函数选择softmax loss函数,激活函数选择矫正线性单元(Rectified linear unit,ReLU)函数。为了防止卷积神经网络模型过拟合,在代价函数中加入权值衰减(weight decay)正则化项,并在第6个卷积层C6后加入Dropout层,Dropout比例设为0.5;
(2)选择训练策略:卷积神经网络训练使用随机梯度下降方法进行优化求解,实现模型参数更新,并使用动量方法(momentum)、批正则化方法来加速学习过程;
(3)选择深度学习库:使用深度学习库Caffe实现以上所述的卷积神经网络结构,并根据已选择的训练策略和图像训练集进行训练;
卷积神经网络的Caffe超参数文件主要设定如下:
test_iter: 10000
test_interval: 40000
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0001
lr_policy: "inv"
gamma: 0.0001
power: 0.8
max_iter: 2000000
snapshot: 40000
snapshot_prefix: "./Crack_Detection_model"
solver_mode: GPU
type: "SGD"
关于卷积神经网络的大部分超参数设定,目前并无通用的选择方法,皆是根据具体训练情况而定。其中:
(1)test_iter为遍历完所有测试集需要的迭代次数,设定值为测试集大小除以mini-batch大小,mini-batch size设为2;
(2)test_interval为测试迭代间隔,即每迭代多少次进行测试,设定值为训练集大小除以mini-batch大小;
(3)base_lr为初始学习率,一般设为0.01,lr_policy为学习率更新策略,gamma、power是所选择的学习率更新策略的相关参数;
(4)momentum为动量方法的超参数,一般设为0.9;
(5)weight_decay为权值衰减的超参数,一般设为0.0001;
(6)max_iter为最大迭代次数,设定要足够大以保证模型能收敛,一般为test_interval的30~100倍;
(7)snapshot为保存训练快照的迭代间隔,一般可设定与test_interval一致,snapshot_prefix为保存训练快照的路径;
(8)solver_mode为运行模式,GPU模式比CPU更快;
(9)type为优化方法选择,根据训练情况而定,可选择随机梯度下降法(SGD)。
S3、使用训练好的卷积神经网络模型对待检测图像进行检测并输出预测标签图像,记为。
所述步骤S3的具体操作如下:
(1)选择一张隧道图像作为待检测图像,并使用双线性插值方法把待检测图像大小调整至(w’,H’)像素,其中待检测图像的采集要求与深度学习训练集图像一致;
(2)调用Caffe的C++接口加载训练好的卷积神经网络模型,对待检测图像进行推理预测,输出预测标签图像。
S4、根据预测标签图像输出检测结果,包括图像类别(有无裂缝)、裂缝的坐标信息以及裂缝的像素级宽度值和长度值,其中图像类别记为Class,裂缝的坐标信息记为,裂缝的像素级宽度值和长度值分别记为Wpixel、Lpixel。
所述步骤S4的具体操作如下:
(1)使用双三次插值方法把预测标签图像大小调整至隧道原始图像大小(W,H),调整后的预测标签图像记为, 其格式与I一致;
(2)遍历预测标签图像中所有连通域,即裂缝区域,使用连通域面积最小化策略提取裂缝区域的外接矩形,并计算外接矩形的宽高比,记为。若大于或等于线性判定阈值,标记为有效裂缝区域;若小于线性判定阈值,则标记为无效裂缝区域,其中线性判定阈值记为,一般可设为2。若预测标签图像中无有效裂缝区域,图像类别Class设为0;否则图像类别Class设为1;
(3)遍历有效裂缝区域,提取其轮廓点坐标集,记为,轮廓点坐标的个数记为,并计算其外接矩形长边的角度,记为。计算方法如下:
(1)
其中,和是外接矩形长边的两个端点坐标;
(4)计算裂缝的像素级长度值。对裂缝区域的轮廓点坐标集进行抽样,抽样间隔记为,抽样后的轮廓点坐标的个数记为。根据抽样后的轮廓点坐标集计算裂缝的像素级长度值,计算方法如下:
(2)
其中,一般可设为30,该值越大,长度计算准确率越高,效率越低,该值越小,长度计算准确率越低,效率越高;
(5)根据附图3,计算裂缝的像素级宽度值。对裂缝区域的轮廓点坐标集进行抽样,抽样间隔记为,抽样后的轮廓点坐标集记为,轮廓点坐标的个数记为。根据抽样后的轮廓点坐标集计算裂缝的像素级宽度值,具体的计算步骤如下:
(a)把抽样后的各轮廓点位置的裂缝像素级宽度值初始化为0;
(b)遍历抽样后的轮廓点坐标集,计算相邻两点的角度值,记为。比较和,若两者间的误差绝对值大于或等于角度偏差阈值,那么放弃计算当前轮廓点位置的裂缝的像素级宽度值,遍历下一个轮廓点,角度偏差阈值记为。若两者间的误差绝对值小于角度偏差阈值,则计算出当前轮廓点位置的裂缝的像素级宽度值。各轮廓点位置的裂缝的像素级宽度值记为,计算方法如下:
其中,可设为10,该值越大,宽度计算准确率越高,效率越低,该值越小,宽度计算准确率越低,效率越高。可设为300,该值过大或过小都会导致宽度计算准确率偏低,可根据实际的裂缝宽度值测试情况调整;
(c)裂缝的像素级宽度值后处理。首先去除中的零值,然后计算的平均值,取此平均值作为最终的裂缝的像素级宽度值。
S5、根据检测结果输出病害记录结果,若待检测图像中存在裂缝,则记录图像名称、裂缝的坐标信息以及裂缝的实际宽度值和长度值;若待检测图像中没有裂缝,则不记录。其中裂缝的实际宽度值和长度值分别记为wreal、Lreal,计算方法如下:
其中,是尺度变换系数,表示图像中单个像素对应的实际距离值,根据相机的分辨率调整,一般可取0.2 mm/pixel;
裂缝长度值和宽度值计算的控制参数可定义如下:
struct CrackGeoCtlPara
{
int nSamLen; //设定长度值计算的抽样间隔
int nSamNumWid; //设定宽度值计算的抽样点个数
double dLineTH; //设定线性判定阈值
double dScaleTran; //设定尺度变换系数
double dAngleBias; //设定角度偏差阈值
}。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!