一种大数据资讯聚合阅读推荐方法与流程
本发明涉及互联网技术领域,具体涉及一种大数据资讯聚合阅读推荐方法。
背景技术:
随着云时代的来临,大数据相关资讯也吸引了越来越多的关注,人们对大数据资讯也越来越关心,但是伴随互联网的发展,各网站报道大数据相关的文章也越来越多,造成大数据相关信息的爆炸。当今的社会随着生活节奏的加快,人们无法投入很多的时间阅读大数据资讯,更无法对相关资讯进行仔细地阅读。因此往往无法抓住资讯重点。本发明提供一种大数据资讯聚合阅读推荐方法,汇总其他网站的特定类别的信息,把这些相关类别的信息存储到环境的数据库中,然后再在微信订阅号中进行显示以及推送。
技术实现要素:
本发明的目的在于针对当今大数据资讯爆炸的时代,提供一种大数据相关资讯聚合阅读推荐方法,汇聚各网站大数据资讯相关文章,提取文章中关键词,找出各类新颖的文章,并推送相关文章给读者。其包括如下步骤:
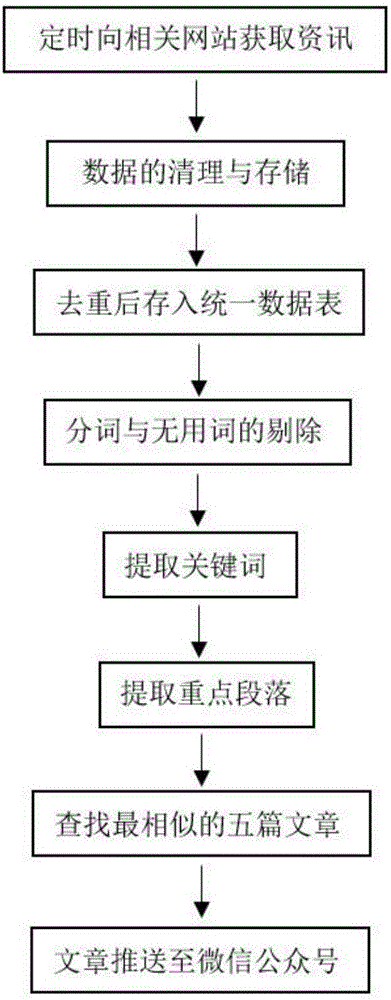
步骤1:采用爬虫工具每天定时向相关网站获取资讯。
步骤2:对相关数据进行清理,整理格式后存储到数据库中。
步骤3:再将各网站对应表中的数据存入统一数据表中,存入之前使用simhash(相似哈希)算法(特征字的距离参数为3)进行去重操作。
步骤4:使用jieba(结巴)中文分词对入库的数据进行分词操作,获取得到的分词使用自建的停用词词表将无用词剔除。
步骤5.提取关键词。
步骤6.提取文章中的重点段落。
步骤7.查找相关文章列举最相似的五篇文章。
步骤8.将筛选后的文章置于网站上,每周将网站中点击量最多的七篇文章推送至微信公众号。
进一步的,所述步骤1采用爬虫工具每天定时向“数据猿”、“雷锋网”等相关网站获取资讯,优选的,爬取文章时间为2:00、6:00、10:00、14:00、18:00、22:00。
进一步的,所述步骤2的对相关数据进行清理,其清理相关数据如下:1.清理网站中存在的广告信息2.清理网站中存在的招聘信息3.清理网站中存在的公告信息4.清理文章中各网站的标识。
进一步的,所述步骤2的清理方法如下:1.首先判断文章字数,如果文章字数过少,小于50字是网站的广告等之类无用信息,进行删除清理2.字数小于100以内的文章进行关键词匹配,如果出现招聘、公告等之类的词语时,则为无用文章,进行统一清理3.根据各网站所特有的标识,如“雷锋网报道”等这些标识性词语进行屏蔽。
进一步的,所述步骤3的存储方式以各网站名字作为表名,爬取的数据存入对应的数据表中。
进一步的,所述步骤3依次读取数据库中各网站的数据,将读取的数据依次与已入库的数据做比较,查看是否存在重复的数据,重复的数据就不入库;若无重复数据直接入库。
进一步的,所述步骤5提取关键词中,首先对分词在百度文库中获取权重,获得权重步骤如下:1.首先获取百度文库该类所有文章的总数量n2.利用各分词在百度文库中查找存在该词的文库数量m3.计算权重w=m/n,获得的权重添加到tf-idf(termfrequency–inversedocumentfrequency词频-逆向文件频率)算法中改善。
进一步的,所述步骤5提取关键词中,百度文库搜索得到的词占到总库中该类文章的50%以上,则该词没有意义置成停用词,动态维护停用词词表。
进一步的,所述步骤5提取关键词中,最后根据文章篇幅提取关键词(小于300字提取两个关键词,小于600字提取三个关键词,大于600字提取5个关键词)。
进一步的,所述步骤6提取文章重点段落的方法,首先统计各段落存在关键词的次数,提取前三个出现次数最多的段落,再比较这三个段落中出现关键词的种类,种类越多,选择该段落为文章的重点段落。
进一步的,所述步骤7筛选出五篇相似文章的步骤:
步骤1.在存储的数据中利用knn(k-nearestneighbork最近邻)算法计算与爬取文章的距离
步骤2.比较距离的大小,并进行降序排序
步骤3.筛选出距离最小的五篇文章,距离最小的文章为与爬取的文章最为相似。
进一步的,所述步骤8将步骤7中筛选出的相似五篇文章以链接形式附于微信公众号中文章的末尾。
本发明的有益效果在于,本发明提供一种大数据资讯聚合阅读推荐方法,汇总一些相关网站的相关类别的信息,把这些相关类别的信息存储到本发明的数据库中,然后再在微信订阅号中进行显示以及推送;利用本发明的方法,可以科学有效地筛选出相关有价值的、符合大众心理的文章,且能进一步地筛选出关键词以及关键段落,节省了用户搜寻有意信息的时间,节省了读者了解信息的时间,提高了信息利用率。
附图说明
图1为本发明方法执行流程图
具体实施方式
具体实施案例1:
如图1所示,本发明一种大数据资讯聚合阅读推荐方法,包括如下步骤:
步骤1:采用爬虫工具每天定时向相关网站获取资讯。
步骤2:对相关数据进行清理,整理格式后存储到数据库中。
步骤3:再将各网站对应表中的数据存入最终统一数据表中,存入之前使用simhash(相似哈希)算法(特征字的距离参数为3)进行去重操作。
步骤4:使用jieba(结巴)中文分词对入库的数据进行分词操作,获取得到的分词使用自建的停用词词表将无用词剔除。
步骤5.提取关键词。
步骤6.提取文章中的重点段落
步骤7.查找相关文章列举最相似的五篇文章
步骤8.将筛选后的文章置于微信公众号中,并对每周点击量最多的七篇文章进行推送。
所述步骤1采用爬虫工具每天定时向“数据猿”、“雷锋网”等相关网站获取资讯,优选的,爬取文章时间为2:00、6:00、10:00、14:00、18:00、22:00。
所述步骤2的对相关数据进行清理,其清理相关数据如下:1.清理网站中存在的广告信息2.清理网站中存在的招聘信息3.清理网站中存在的公告信息4.清理文章中各网站的标识。
所述步骤2的清理方法如下:1.首先判断文章字数,如果文章字数过少,小于50字可是网站的广告等之类无用信息,进行删除清理2.字数小于100以内的文章进行关键词匹配,如果出现招聘、公告等之类的词语时,为无用文章,进行统一清理3.根据各网站所特有的标识,如“雷锋网报道”等这些标识性词语进行屏蔽。
所述步骤3的存储方式以各网站名字作为表名,爬取的数据存入对应的数据表中。
所述步骤3依次读取数据库中各网站的数据,将读取的数据依次与已入库的数据做比较,查看是否存在重复的数据,重复的数据就不入库;若无重复数据直接入库。
所述步骤5提取关键词中,首先对分词在百度文库中获取权重,获得权重步骤如下:1.首先获取百度文库该类所有文章的总数量n2.利用各分词在百度文库中查找存在该词的文库数量m3.计算权重w=m/n,获得的权重添加到tf-idf(termfrequency–inversedocumentfrequency词频-逆向文件频率)算法中改善。
所述步骤5提取关键词中,在百度文库中搜索相关分词,所述搜索得到的词占到总库中该类文章的50%以上,则该词没有意义,设置成停用词,动态维护停用词词表。
所述步骤5提取关键词中,最后根据文章篇幅提取关键词(小于300字提取两个关键词,小于600字提取三个关键词,大于600字提取5个关键词)。
所述步骤6提取文章重点段落的方法,首先统计各段落存在关键词的次数,提取前三个出现次数最多的段落,再比较这三个段落中出现关键词的种类,种类越多,选择该段落为文章的重点段落。
所述步骤7筛选出五篇相似文章的步骤:
步骤1.在存储的数据中利用knn(k-nearestneighbork最近邻)算法计算与爬取文章的距离
步骤2.比较距离的大小,并进行降序排序
步骤3.筛选出距离最小的五篇文章,距离最小的文章为与爬取的文章最为相似。
所述步骤8将步骤7中筛选出的相似五篇文章以链接形式附于微信公众号中文章的末尾。
所述步骤1定时爬取“数据猿”、“雷锋网”等相关网站前100条数据,之后会跟本发明中已存的数据库中的数据作比较,重复的不会入库。所述步骤4进行分词操作过程中,设置停用词的目的是在分词时,可以先把没有实际意义的词如“的”字去掉,这样后面会减少计算量,所述步骤6提取文章重点段落的目的是方便读者在阅读文章时可以快速浏览文章,直接标注重点段落,读者阅读时可以直接看重点段落就了解文章,节省了阅读时间。
本发明的有益效果在于,本发明提供一种大数据资讯聚合阅读推荐方法,汇总其他网站的一些类别信息,把这些相关类别的信息存储到环境的数据库中,然后在微信订阅号中进行显示以及推送;利用本发明的方法,可以科学有效地筛选出相关有价值的、符合大众心理的文章,可以使得更加精准、更加具有针对性的文章在微信平台上推送,节省了用户搜寻有意信息的时间,标注的重点段落和关键词节省了用户的阅读时间,提高了信息的利用率。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!