一种网络爬虫伪装数据的生成方法及系统与流程
本发明涉及网络信息抓取领域,尤其涉及一种网络爬虫伪装数据的生成方法及系统。
背景技术:
互联网的高速发展使之汇聚了海量的用户数据。将互联网上的海量数据与自己相关的抓取下来,分析数据,就能产生有价值的数据结果,这是舆情分析的前提和基础。但是,由于各搜索引擎、门户网站从自身企业利益的角度出发,并不欢迎爬虫访问,会开发策略程序在确保不妨碍正常自然人用户访问下对爬虫进行封锁,但这样也导致了舆情分析、公共数据调查等正常的数据研究无法进行。
由于互联网企业在封锁网络爬虫程序的时候,普遍采用的原则是“封锁爬虫程序的访问,保证正常自然人用户不受影响,同时要考虑封锁措施的成本在合理的范围之内”。因此,要想实现网络数据抓取,开展舆情分析、公共数据调查等正常的数据研究,方法之一是研究如何让爬虫程序在互联网中的网络行为和网络痕迹像自然人一样,概括地说就是研究让爬虫程序在互联网上以拟人化的方式采集数据。
目前,爬虫程序伪装自己主要的方式就是通过切换代理ip,降低每个ip的访问频率;设置访问请求的时间间隔;或者在访问请求中手工添加cookie;这些方式都只是在某一个方面模拟了自然人用户人访问互联网的操作,如果互联网站的封锁策略变化,就需要重新修改爬虫代码,并不具有持久的稳定性。
技术实现要素:
鉴于上述不足,本发明提出了一种网络爬虫伪装数据的生成方法及系统,自动化批量产生网络爬虫伪装数据,多维度模拟真实自然用户访问互联网,使得网络爬虫在互联网上的访问请求行为不易被目标网站识别,实现舆情分析、公共数据调查等正常的数据获取。
为解决上述技术问题,本发明采用如下技术方案:
一种网络爬虫伪装数据的生成方法,其步骤包括:
从浏览器的用户代理useragent字串库中选择一useragent字串,从代理ip资源池中获取一代理ip;
利用所述useragent字串和所代理ip访问目标网站,根据cookie获取策略,获取cookie信息并存储于cookie资源池;
将所述cookie信息与所述useragent字串、所述代理ip、多个同城代理ip、referer信息关联存储,并打包成伪装数据;
根据调度策略将所述伪装数据供外部爬虫程序使用。
进一步地,根据操作系统类型、渲染引擎标志、版本信息等数据为useragent字串分类建立索引。
进一步地,所述useragent字串填充进访问http请求的header文件头的user-agent字段中。
进一步地,根据ip的地理位置将所述代理ip和所述同城代理ip按照市县两级地理位置索引存储。
进一步地,所述cookie获取策略包括:
1)对于登陆才可访问的网站,使用用户名、密码等用户身份认证信息进行访问;对于无需登陆就可访问的网站,可以不包含用户身份认证信息直接进行访问;
2)cookie获取操作信息,包括获取cookie的选择下拉框、点击按钮、输入文本等操作信息、操作之间的先后顺序信息以及与操作相关的网页元素在html网页上的路径位置,该路径位置可使用xpath、css选择器或者网页路径表达方式表示;
3)验证码破解策略,包括外接打码平台、图片ocr识别、滑动验证码识别等。
进一步地,通过使用浏览器自动化运行程序、驱动浏览器程序,加载cookie获取策略,获取访问目标网站的cookie。
进一步地,所述同城代理ip根据所述代理ip生成。
进一步地,所述referer信息在设置所述cookie获取策略时一同设置,包括为目标网站的首页url。
进一步地,所述调度策略包括:
1)在某段时间内以某种频率供外部程序调用;
2)cookie持续以某种频率供外部程序调用;
3)cookie在每天的固定某段时间供外部程序调用。
一种网络爬虫伪装数据的生成系统,包括:
浏览器的用户代理useragent字串库,用于存储useragent字串;
代理ip资源池,用于提供并维护代理ip;
cookie资源池,用于存储目标网站的cookie信息并进行维护;
cookie采集器,用于根据cookie获取策略自动获取cookie信息并存储于所述cookie资源池,使用验证码破解策略破解目标网站验证码;并将cookie信息、代理ip、useragent字串、referer信息统一打包为伪装数据进行存储;
外部获取接口,用于根据调度策略将所述伪装数据提供给外部爬虫程序使用。
根据http协议的设计,自然人用户的网络数据请求有一些特征,包括cookie是由web服务器保存在客户端的用户身份信息,web服务器可以根据访问请求携带的cookie信息检测当前访问请求是否具有合法权限;referer记录了当前网页请求是从哪个url的页面跳转过来的,ip地址展示了网络请求来自哪个网络机器的地址;useragent记录了网络请求是在什么版本的浏览器软件上发送出的。
本发明整合代理ip资源、浏览器版本信息资源,存储网站的用户名、密码等身份认证数据,以及存储网站的登录策略信息,构造出一套爬虫拟人化伪装数据,并以对外接口的形式,把打包的拟人化伪装数据发送给外部爬虫系统供其使用,爬虫系统可以在打包的拟人化伪装数据中有选择性地使用,将爬虫程序采集请求伪装为自然人用户的访问请求,正常访问网络。本方法使得爬虫程序与伪装数据生成系统的耦合度低,可以普遍应用,可以降低拦截可能性。
附图说明
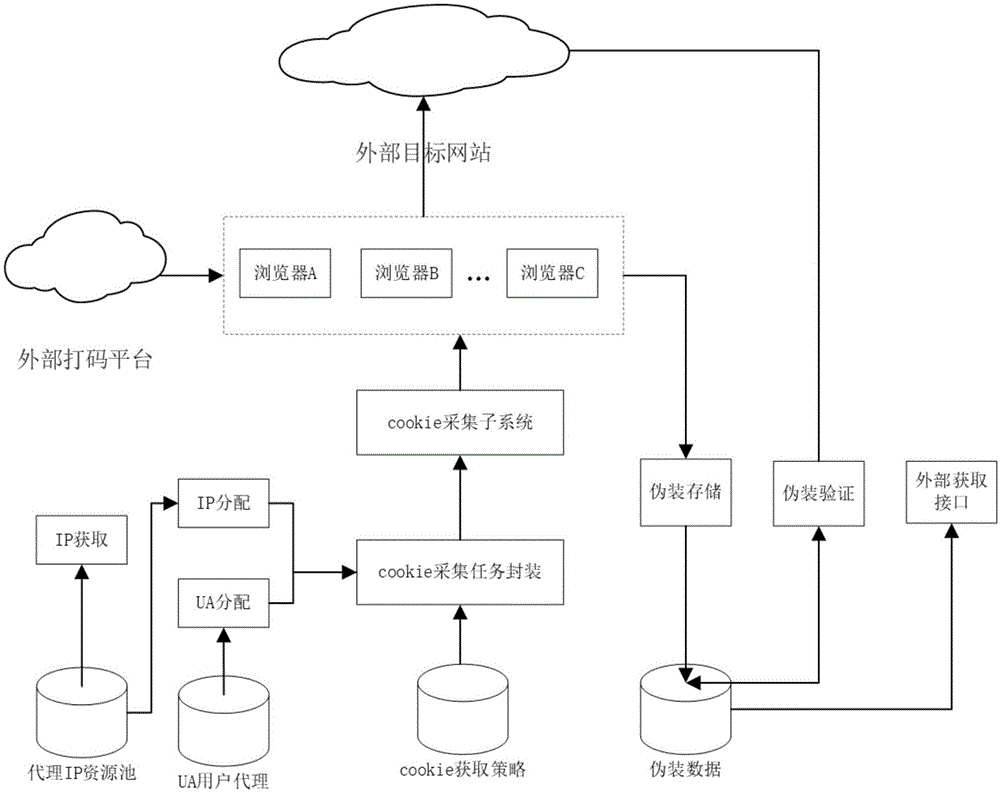
图1是一种网络爬虫伪装数据的生成系统架构图。
图2是一种网络爬虫伪装数据的生成方法流程图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本实施例提供一种网络爬虫伪装数据的生成方法及实现该方法的系统,系统架构如图1所示,方法如图2所示。
(1)在现有的服务器上安装有多个浏览器可供使用,基于这些浏览器运行本系统。
(2)尽可能多地收集浏览器的用户代理useragent字串存储在系统内部,建立useragent字串库,可称之为ua用户代理集合,内部存储收集的useragent。对于集合中的useragent字串,根据操作系统类型、渲染引擎标志、版本信息等数据分类建立索引,使之可根据这些特征获得符合要求的useragent字串。
(3)在系统内部建立代理ip资源池,对于获取的代理ip,根据ip的地理位置将代理ip按照两级地理位置索引存储,其中,地理位置精确到市/县级,例如湖北黄冈。系统内部可以根据一个ip生成在同一个城市/县的代理ip地址。
(4)cookie采集任务封装,系统从代理ip资源池取一个ip,从ua用户代理集合中获取一个用户代理useragent字串,根据cookie采集策略封装采集任务。将封装好的采集任务推进任务队列中。
该cookie获取策略包括:
i.用户的身份认证信息,对于需要登陆访问的网站,需要用户输入用户名、密码等身份信息才可以访问网站数据,对于不需要登陆访问的网站,可以包含身份认证信息;
ii.cookie获取操作信息,记录了获取cookie的选择下拉框、点击按钮、输入文本等操作,操作之间的先后顺序,以及与操作相关的网页元素在html网页上路径位置,路径位置可以使用xpath、css选择器或者网页路径表达方式表示。cookie获取操作信息是cookie获取策略不可或缺的内容;
iii.验证码破解策略,对于需要输入验证码的网页,针对简单图片验证码的策略、复杂图片验证码的策略、滑块图片验证码的策略,包括外接打码平台、图片ocr识别、滑动验证码识别。
(5)建立cookie采集子系统,cookie采集子系统是本系统的核心部分,从任务队列中获取任务,采集目标网站的cookie信息,cookie信息是网络爬虫伪装数据的重要组成部分。
(6)服务器上安装多个浏览器程序,例如phantomjs、chrome、firefox等。cookie采集器通过浏览器驱动模块,加载cookie获取策略,驱动浏览器程序,根据cookie策略获得访问目标网站,从而某一个目标网站的cookie。
(7)在获取目标网站cookie的过程中,系统从内部的浏览器用户代理useragent字串库中选择一个作为本次访问请求的useragent字串填充进访问http请求的header文件头的user-agent字段中,并且该useragent字串和返回的cookie关联存储在一起。
(8)在获取目标网站cookie的过程中,从代理ip资源池中获取一个ip,通过这个ip获取到cookie信息后,存储获取的cookie时关联存储这个代理ip。除此之外,再关联数个这个ip的同城代理ip,并存储到一起。模拟同一个自然人用户的上网设备在不同的网络环境下上网,例如移动设备或者笔记本设备连接不同的网络wifi,笔记本设备连接不同网络环境的网线等情况。
(9)对外发布cookie信息时,同时把cookie、useragent、代理ip和同城代理ip对外发布。多维度的爬虫伪装信息更加丰富详细。
(10)cookie调度:为了防止单一cookie频繁进行采集,系统内部在对外发布cookie伪装数据时,会根据不同的调度策略轮流调度cookie数据,供外部程序使用。
该调度策略包括:
i.在某段时间(例如某两个小时)内可以以某种频率供外部程序调用。
ii.cookie持续以某种频率供外部程序调用。
iii.cookie在每天的固定某段时间可以供外部程序调用。
通过不同调度策略,模拟自然人用户不同上网用户习惯,减少爬虫程序被目标网站封锁。
另外,定期对获取这些爬虫伪装数据进行有效性的伪装验证,清除失效数据,并且根据上述的策略重新生成新的伪装数据。
采用本方法生成多维度的网络爬虫身份数据,包括cookie、ip、访问频率、客户端浏览器版本信息、本次网络请求的来源页面信息等信息,并将这些信息打包发送给外部,供外部爬虫程序在抓取网络数据的过程中伪装为一个自然人用户的访问请求,达到对抗互联网后台服务程序对于爬虫程序访问请求的封锁策略。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!