一种基于并行运算的光伏发电功率预测方法与流程
本发明涉及风力发电领域,尤其是涉及一种基于并行运算的光伏发电功率预测方法。
背景技术
可再生能源将有可能逐步替代化石能源,成为人类可持续发展的能源。其中,太阳能是可再生能源中资源量最大并且分布最普遍的能源。光伏发电是利用太阳能的一种有效的方式,但是光伏发电系统输出功率具有不连续性和不确定性的特点。影响光伏发电功率的因素很多,其中气象因素是影响光伏发电功率最大的因素。由于太阳辐射强度与季节、地理位置、观测时刻的大气状况、太阳时角、观测日期、观测时间及云量等因素都密切相关,因此太阳辖射强度的变化随机性比较大,因而太阳能光伏发电装置的实际输出功率也随之发生变化。总之,由于气象条件变化的随机性,光伏发电功率的变化也具有一定的不确定性。同时光伏发电系统的输出功率还具有很强的周期性,光伏发电系统并网运行以后会对电网产生周期性的冲击,光伏发电系统输出功率的扰动将有可能对电网的稳定造成一定的影响。
越来越多的用户使用光伏发电系统来提供电能,电网规划人员想要准确预测光伏发电功率的增长情况就变得越来越困难,必然会影响电网系统的调度和机组工作的计划。因此,需要研究如何更准确地预测光伏发电功率,从而协调电力部门对电网进行合理的调度,减少光伏发电功率的随机性对电力系统的影响,从而提高系统的安全性和稳定性。
多点地质统计法(mps,multiple-pointstatistics)近年来在预测数据方面应用较广,而且取得了不错的成绩。在多点地质统计法使用过程中,训练图像的概率信息被复制到待预测区域,但是如果训练图像数据量大、维数较高,会给预测效率和质量带来极大挑战。
技术实现要素:
本发明的目的是针对上述问题提供一种基于并行运算的光伏发电功率预测方法。
本发明的目的可以通过以下技术方案来实现:
一种基于并行运算的光伏发电功率预测方法,所述方法包括下列步骤:
三维模式库训练步骤,根据光伏发电环境数据在主机端构建训练图像并进行存储,通过捕获训练图像的数据事件,在客户端并行处理建立三维模式库;
光伏发电功率预测步骤,在主机端建立光伏发电预测区域,利用三维模式库遍历风电预测区域内的未知节点,在客户端通过并行运算得到光伏发电功率的预测结果。
优选地,所述三维模式库训练步骤包括下列步骤:
a1)根据光伏发电环境数据,在主机端构建三维空间内的训练图像并进行存储;
a2)将主机端存储的训练图像拷贝至客户端,在客户端的第一处理内核内通过三维数据模板对步骤a1)内得到的训练图像进行扫描,得到训练图像的初始模式库;
a3)在客户端的第三处理内核内将步骤a2)得到的训练图像的初始模式库进行分类,得到对应的多个子空间,并计算得到每个子空间的代表模式,实现三维模式库的建立。
优选地,所述步骤a1)包括:
a11)将光伏发电环境数据内的每一个数据作为三维空间内的一个节点,每个节点以向量的形式进行存储,每个向量由该光伏发电环境数据的所有属性构成;
a12)在主机端,将所有光伏发电环境数据对应的所有节点共同构造得到三维空间内的训练图像,所述训练图像的长为节点的属性对应的种类的整数倍,所述训练图像的长、宽和高的积与节点的数量一致。
优选地,所述光伏发电环境数据的所有属性包括时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度和光伏发电功率。
优选地,所述步骤a3)包括:
a31)在客户端的第三处理内核内,通过基于密度的聚类方法对训练图像的初始模式库进行聚类分类,得到的每一个分类结果作为一个子空间;
a32)求取每一个子空间内的所有模式的平均值,得到的结果作为该子空间的代表模式,实现三维模式库的建立。
优选地,所述步骤a2)还包括:在客户端的第二处理内核内,将通过三维数据模板扫描后的训练图像进行降维处理,得到低维度下的训练图像的初始模式库。
优选地,所述降维处理具体为:通过等距特征映射的方式进行降维处理。
优选地,所述光伏发电功率预测步骤包括:
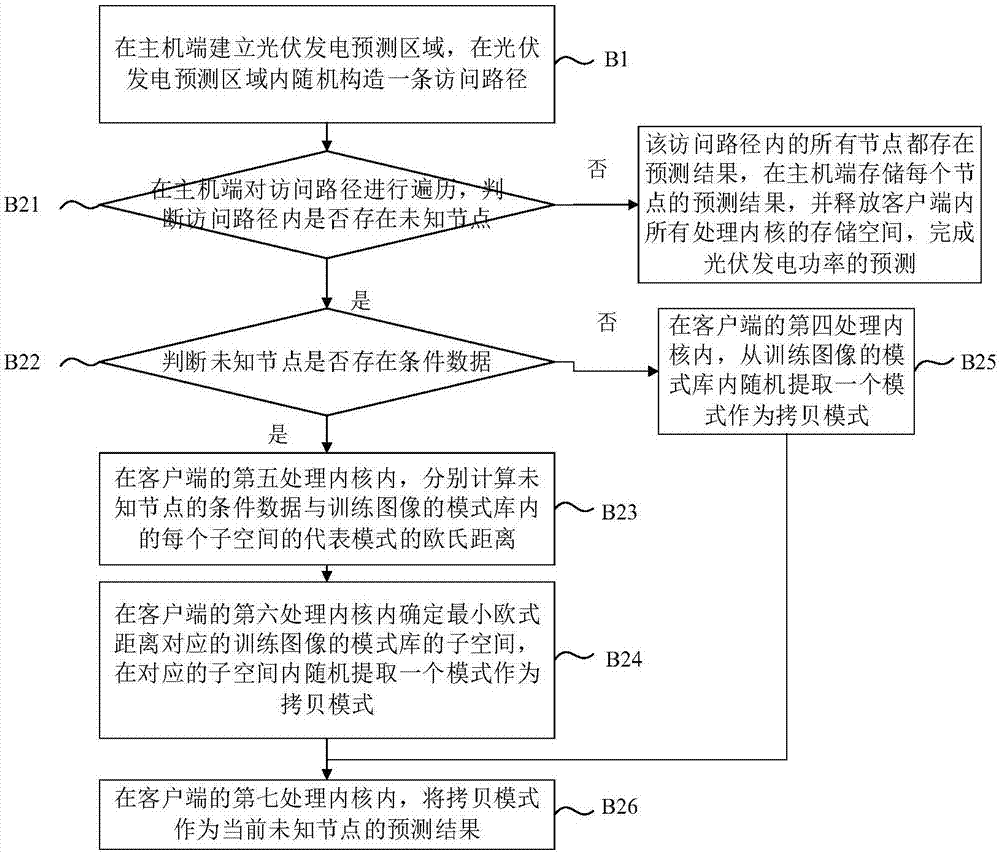
b1)在主机端建立光伏发电预测区域,在光伏发电预测区域内随机构造一条访问路径;
b2)根据三维模式库,在主机端对访问路径内的节点进行遍历,在客户端根据遍历的情况进行并行运算得到风电功率预测结果。
优选地,所述步骤b2)包括:
b21)在主机端对访问路径进行遍历,判断访问路径内是否存在未知节点,若是则进入步骤b22),若否则表明该访问路径内的所有节点都存在预测结果,在主机端存储每个节点的预测结果,并释放客户端内所有处理内核的存储空间,完成光伏发电功率的预测;
b22)判断未知节点是否存在条件数据,若是则进入步骤b23),若否则进入步骤b25);
b23)在客户端的第五处理内核内,分别计算未知节点的条件数据与训练图像的模式库内的每个子空间的代表模式的欧氏距离;
b24)根据步骤b23)计算的欧式距离,在客户端的第六处理内核内确定最小欧式距离对应的训练图像的模式库的子空间,在对应的子空间内随机提取一个模式作为拷贝模式,进入步骤b26);
b25)在客户端的第四处理内核内,从训练图像的模式库内随机提取一个模式作为拷贝模式,进入步骤b26);
b26)在客户端的第七处理内核内,将拷贝模式作为当前未知节点的预测结果,同时返回步骤b21)。
优选地,所述光伏发电预测区域的建立方式与训练图像的构建方式相同。
与现有技术相比,本发明具有以下有益效果:
(1)本发明提出的方法,基于光伏发电环境数据组建的训练图像,通过对训练图像进行分类,再比较当前数据事件与分类得到的子空间的代表模式的欧氏距离从而实现随机模拟,最后完成对光伏发电功率的预测,这样的方法一方面可以将光伏发电环境数据以图像的形式进行表示,便于训练,同时利用随机模拟的方法完成等可能和等概率的抽样,从而使得最终的预测结果具有较高的准确性,实用性强,适合各种光伏发电系统,而且本发明提出的方法中,在主机端存储训练图像和光伏发电预测区域,而在客户端通过并行的方式一方面通过并行运算建立模式库,另一方面通过并行运算进行光伏发电功率的预测,这样的方式一方面可以大大减小主机端的存储数据量,提高主机端的运行效率,同时在客户端通过并行处理的方式可以进一步提高计算效率和速度,从而大大提升光伏发电功率的预测效率。
(2)通过基于密度的聚类方法对训练图像进行分类,这样的分类方式充分考虑到训练图像内各部分之间的可连接性,从而使得分类的结果比较具有代表性,从而提升预测的准确程度。
(3)在聚类前首先将训练图像通过等距特征映射进行降维,这样可以大大降低训练图像的维数,从而方便后续的数据处理,加快模拟速度,进而提高光伏发电功率的预测效率,同时由于图像维数低,因此可以提高聚类的精度,继而提升光伏发电功率预测的预测精度。
(4)在随机模拟步骤中,通过求预测区域内的已知条件数据与上述子空间的“代表模式”的欧氏距离,将欧氏距离最小的“代表模式”作为预测结果复制到待预测区域,从而可以使得预测结果为预测区域内的已知条件可以得到的最接近的结果,符合实际情况,准确性较高,从而大大提高了光伏发电功率预测的准确程度。
(5)在对初始模式库进行分类和光伏发电功率预测的过程中,每一步计算过程都是由一个独立的处理内核进行处理,这样可以避免上一级计算速度低时后续计算无法进行的情况,通过并行处理,进一步提高运算效率,从而提升光伏发电功率的预测效率和速度。
附图说明
图1为光伏发电功率预测步骤的方法流程图;
图2为三维模式库训练步骤的方法流程图;
图3为数据模板的示意图,其中(3a)为二维数据模板,(3b)为三维数据模板。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
本实施例提出了一种基于并行运算的光伏发电功率预测方法,包括下列步骤:
三维模式库训练步骤,根据光伏发电环境数据在主机端构建训练图像并进行存储,通过捕获训练图像的数据事件,在客户端并行处理建立三维模式库;
光伏发电功率预测步骤,在主机端建立光伏发电预测区域,利用三维模式库遍历风电预测区域内的未知节点,在客户端通过并行运算得到光伏发电功率的预测结果。
其中,如图2所示,三维模式库训练步骤包括下列步骤:
a1)根据光伏发电环境数据,在主机端构建三维空间内的训练图像并进行存储,包括:
a11)将光伏发电环境数据内的每一个数据作为三维空间内的一个节点,每个节点以向量的形式进行存储,每个向量由该光伏发电环境数据的所有属性构成,本实施例中,光伏发电环境数据的所有属性包括时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度和光伏发电功率;
a12)在主机端,将所有光伏发电环境数据对应的所有节点共同构造得到三维空间内的训练图像,所述训练图像的长为节点的属性对应的种类的整数倍,所述训练图像的长、宽和高的积与节点的数量一致;
a2)将主机端存储的训练图像拷贝至客户端,在客户端的第一处理内核内通过三维数据模板对步骤a1)内得到的训练图像进行扫描,在客户端的第二处理内核内,将通过三维数据模板扫描后的训练图像通过等距特征映射的方式进行降维处理,得到低维度下的训练图像的初始模式库;
a3)在客户端的第三处理内核内将步骤a2)得到的训练图像的初始模式库进行分类,得到对应的多个子空间,并计算得到每个子空间的代表模式,实现三维模式库的建立,包括:
a31)在客户端的第三处理内核内,通过基于密度的聚类方法对训练图像的初始模式库进行聚类分类,得到的每一个分类结果作为一个子空间;
a32)求取每一个子空间内的所有模式的平均值,得到的结果作为该子空间的代表模式,实现三维模式库的建立。
如图1所示,光伏发电功率预测步骤包括:
b1)在主机端通过与训练图像的相同构建方式建立光伏发电预测区域,在光伏发电预测区域内随机构造一条访问路径;
b2)根据三维模式库,在主机端对访问路径内的节点进行遍历,在客户端根据遍历的情况进行并行运算得到风电功率预测结果,包括:
b21)在主机端对访问路径进行遍历,判断访问路径内是否存在未知节点,若是则进入步骤b22),若否则表明该访问路径内的所有节点都存在预测结果,在主机端存储每个节点的预测结果,并释放客户端内所有处理内核的存储空间,完成光伏发电功率的预测;
b22)判断未知节点是否存在条件数据,若是则进入步骤b23),若否则进入步骤b25);
b23)在客户端的第五处理内核内,分别计算未知节点的条件数据与训练图像的模式库内的每个子空间的代表模式的欧氏距离;
b24)根据步骤b23)计算的欧式距离,在客户端的第六处理内核内确定最小欧式距离对应的训练图像的模式库的子空间,在对应的子空间内随机提取一个模式作为拷贝模式,进入步骤b26);
b25)在客户端的第四处理内核内,从训练图像的模式库内随机提取一个模式作为拷贝模式,进入步骤b26);
b26)在客户端的第七处理内核内,将拷贝模式作为当前未知节点的预测结果,同时返回步骤b21)。
本实施例中,在未建立三维模式库的情况下,根据上述流程实现的完整的光伏发电功率预测过程如下:
在光伏发电功率预测中,需要考虑的环境因素很多,如时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度以及其他一些随机因素,这些因素都会影响光伏阵列的输出特性。因此在选择预测模型的输入变量时,需要考虑使用那些与光伏发电相关性较大的确定性因素。
在预测光伏发电功率之前,需要构建光伏发电环境因素的训练图像。光伏发电环境数据主要包括环境因素数据和对应的光伏发电功率。本实施例中,以每一个数据作为一个三维空间的一个节点,但是这些节点需要按照一定的规则排列。例如,假定环境因素数据包括时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度。那么可以设向量v,每个向量表示为:
v=(时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度、光伏发电功率)
v中的8个分量时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度、光伏发电功率分别视为三维空间的一个节点。那么按照上述v中的顺序从左到右依次排列所有的向量分量。假设已知历史数据一共有n个(包括时间、地点、太阳辐射强度、大气压、温度、光伏阵列的转换效率、安装角度、光伏发电功率),即三维空间有n个节点,那么需要将这些节点“变形”为一个三维图形,图形的长、宽、高分别设为a、b、c,其中a必须为8的整数倍(因为有8个分量),而且a×b×c=n。按照上面的原则由环境因素数据可以获得模拟时需要的训练图像。在预测光伏发电功率时,首先构建三维的光伏发电功率预测区域,该预测区域内的数据排列方式与训练图像数据排列方式相同。即预测区域的长、宽、高设为a、b、c。做以下规定:a必须为8的整数倍,如果c>1,那么a=a,b=b;如果c=1且b>1,那么a=a;如果c=1且b=1,那么a<a。
在训练图像构建完成后,可利用数据模板扫描训练图像来捕获数据事件,这些数据事件又被称为“模式”,而这些模式包含了训练图像的结构特征。利用三维数据模板扫描训练图像,可获得训练图像的三维模式库,这些模式库为进行光伏发电功率预测提供了预测时使用的概率信息。数据模板为τn,它是由n个向量组成的几何形态,τn={hα;α=1,2,…,n}.设模板中心位置为u,模板其他位置uα=u+hα(α=1,2,…,n)。图(3a)和(3b)分别给出了二维和三维数据模板示意图,二维数据模板中心为u,三维数据模板中心为图中几何中心的部位,二维和三维数据模板的形态由使用者自行规定。
但是在光伏发电环境数据较多时,会为预测过程带来较大的计算负担。在预测过程中,训练图像的模式特征决定了预测结果,但这些模式往往维数较高,数据处理较为困难,因此需要进行降维处理。降维方法可分为线性和非线性降维,线性降维方法主要用来对线性数据降维,然而现实世界的许多数据处于非线性结构,采用线性降维方法难以处理非线性数据。本实施例采用等距特征映射isomap(isometricmapping)实现模式的非线性降维。isomap是建立在多维尺度变换基础上的一种非线性降维方法,在流形学习中应用较广。isomap利用所有样本点对之间的测地距离矩阵来代替多维尺度变换算法中的欧氏距离矩阵,以保持嵌入在高维观测空间中的内在低维流形的全局几何特性。
在完成训练图像中模式的降维后,需要对获取的低维模式进行分类。对这些模式采用基于密度的聚类方法(density-basedclusteringalgorithm,简称dbscan)进行分类。其主要思想是:只要邻近区域的密度(对象的数目)超过某个阈值,就继续执行聚类操作。基于密度的聚类方法具有发现任意形状聚类及处理噪声数据的能力。dbscan作为典型的密度聚类算法,它基于一组“邻域”参数(∈,minpts)来刻画样本分布的紧密程度。邻域参数其实限定了聚类簇的规模大小至少为minpts个样本点,若样本点x的“∈-邻域”至少包含minpts个样本,则称其为“核心对象”。dbscan算法簇是由密度关系导出的最大的密度相连的样本集合。
在利用dbscan划分模式空间后,获得若干“子空间”,每个子空间命名为cell。对于每个cell,可以定义一个与数据模板相同形状的“平均模板”,称为prototype,它是属于该cell的所有模式在原高维空间中各节点位置的均值.
当进行光伏发电功率预测时,首先设定三维的光伏发电预测区域,该预测区域内的数据排列方式与训练图像数据排列方式相同。将当前预测区域内已知的各个条件数据与上述子空间的prototype依次利用欧氏距离求出它们之间的差异,将差异最小的prototype所对应子空间中的任意某个模式作为模拟结果复制到待预测区域,但是当前预测区域内已知的条件数据不变,这样就获得了当前预测区域的预测值。接着对待预测区域的其他未知节点继续模拟直到所有节点模拟完毕。
但是上述预测过程在训练图像数据较多时运行速度较慢,导致整个模拟过程运行效率较低。为了提高模拟速度,有必要对处理流程开发对应的并行运算。基于gpu的cuda架构具有优良的并行运算能力,可以实现光伏发电功率预测的并行计算。整个并行运算架构采用主机端(cpu端)-客户端(gpu端)设计模式,在gpu端一共采用了7个gpu内核,其中内核1~3是对训练数据进行特征提取和分类,内核2和3分别是对流形学习和dbscan算法的操作;内核4~7是对光伏发电功率的预测,同时也是对mps和流形学习的模拟过程的并行化实现。
- 还没有人留言评论。精彩留言会获得点赞!