自动报表存储方法及系统与流程
本发明涉及数据库技术领域,具体涉及一种自动报表存储方法及系统。
背景技术
在现在的办公中,许多的公司以及职员为了提高办公效率都需要进行电脑办公,例如采用excel等辅助办公软件、报表,其中以excel报表为例,excel报表提供了许多张非常大的空白工作表,每张工作表由256列和65536行组成,行和列交叉处组成单元格,别小看单元格在屏幕上显示不很大,每一单元格可容纳32000个字符。这样大的工作表可以满足大多数数据处理的业务需要;将数据从纸上存入excel工作表中,这对数据的处理和管理已发生了质的变化,使数据从静态变成动态,能充分利用计算机自动、快速的进行处理。
在每一个时间段,公司或者个人都会有一定的数据,并且在该时间段将上述时间段的数据录入至excel报表内进行存储,并在上述的时间段后将excel报表格存储至原数据库内,方便日后对上述时间段的数据进行调取,回看。现有技术中,都是通过将每个原数据库中存有的维度、指标模板进行匹配将excel内存储的数据录入至数据库内,进而提高了excel内存储的数据录入至数据库内的效率。但是此种方式需要将excel报表的格式设置成与上述原数据库中存有的维度、指标模板相对应的模板,该模板必须是固定模板,使得工作人员在将excel报表内的数据存入至原数据库之前需要进行整理使其与原数据库内的模板相对应,才能完成自动录入,增加了工作人员的工作人员,间接的降低了excel报表内的数据存入至原数据库的效率。
技术实现要素:
因此,本发明要解决的技术问题在于克服现有技术中的报表内的数据导入数据库中效率低下所带来的缺陷。
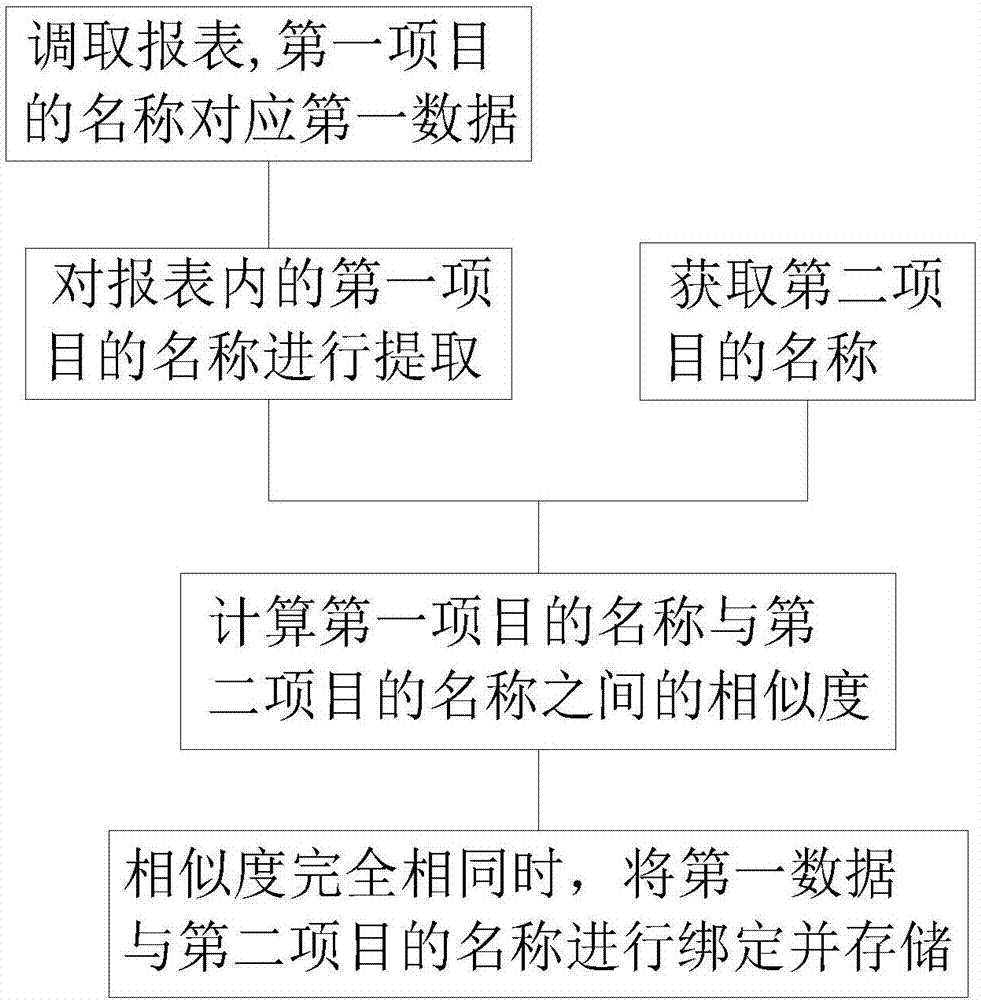
为此,提供一种自动报表存储方法,包括:
调取报表,所述报表内包括第一项目的名称和第一项目名称对应的第一数据;
对所述报表内的第一项目的名称进行提取,获得所述报表内包含的第一项目的名称;
获取预存于原数据库的第二项目的名称;
计算所述第一项目的名称与第二项目的名称之间的相似度;
当所述相似度为完全相同时,将所述第一项目的名称所对应的第一数据与所述第二项目的名称绑定并存储于所述原数据库。
进一步的,
在所述的第一项目的名称与其中一个第二项目的名称中的相似度为不完全相同时,还包括以下步骤:
第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阀值,输出所述的一个或多个第二项目的名称;
第一项目的名称与其中一个或多个第二项目的名称中的相似度小于预设阈值,输出所述的第一项目的名称。
进一步的,
在所述的第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阈值,输出所述的一个或多个第二项目的名称,包括以下方法,
s1,统计第一项目的名称的文本个数;
s2,分别统计若干第二项目的名称的文本个数;
s3,将第二项目的名称的文本个数与第一项目的名称的文本个数进行第一次相似度比较,并将第二项目的名称的按照与第一项目的名称的个数相似度进行冒泡排序;
s4,选出与第一项目的名称文本个数相同的第二项目的名称;
s5,将第二项目的名称的字符与第一项目的名称的字符进行第二次相似度比较,并将具有与第一项目的名称具有相同字符的第二项目的名称进行输出。
进一步的,
接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,n为第一项目的名称的数量;
所述原数据库预先录入的若干第二项目的名称的集合为θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,m为第二项目的名称的数量;
按照以下公式,分别计算每个第一项目的名称ai与第二项目的名称bj的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称;|ai∩bj|表示第一项目的名称ai与第二项目的名称bj之间相同字符数,|ai∪bj|表示第一项目的名称ai与第二项目的名称bj的所有字符数;
确定满足以下条件的第二项目的名称bj,将满足所述条件的第二项目的名称bj作为有效第二项目的名称bm,
所述条件为:
p≤|jδ(ai,bj)|≤k;
确定所述有效第二项目的名称bm的评价系数jm,且:
其中,p为相似度的预设最小临界值,k为相似度的预设最大临界值,qm为有效第二项目的名称bm的历史匹配次数;c为相似度jδ(ai,bm)的权重系数;d为qm的权重系数;q0为qm的预设临界值;
将与评价系数jm的最大值所对应的有效第二项目的名称bm作为当前计算的第一项目的名称ai的相似度最高的第二项目的名称。
进一步的,
获取当前报表的当前特征信息;
获取之前将数据存入过原数据库中的报表的原始特征信息;
计算所述当前特征信息与原始特征信息之间的相似度;
当所述相似度为大于等于一阈值时,优先获取与所述原始特征信息相对应报表的第二项目的名称。
一种自动报表存储系统,包括:
调取装置,用于调取报表,所述报表内包括第一项目的名称和第一项目名称对应的第一数据;
提取装置,用于对所述报表内的第一项目的名称进行提取,获得所述报表内包含的第一项目的名称;
获取装置,用于获取预存于原数据库的第二项目的名称;
相似度计算装置,用于计算所述第一项目的名称与第二项目的名称之间的相似度;
绑定装置,当所述相似度为完全相同时,将所述第一项目的名称所对应的第一数据与所述第二项目的名称绑定并存储于所述原数据库。
进一步的,
在所述的第一项目的名称与其中一个第二项目的名称中的相似度为不完全相同时,所述相似度计算装置还包括:
第一相似度比对子单元,用于在第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阈值时,输出所述的一个或多个第二项目的名称;
第二相似度比对子单元,用于在第一项目的名称与其中一个或多个第二项目的名称中的相似度小于预设阈值时,输出所述的第一项目的名称。
进一步的,
所述的相似度比对装置还包括:
第一标题文本接收单元,用于接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,n为第一项目的名称的数量;
所述原数据库预先录入的若干第二项目的名称的集合为θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,m为第二项目的名称的数量;
确定单元,用于按照以下公式,分别计算每个第一项目的名称与第二项目的名称的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称。
进一步的,
第一标题文本接收单元,用于接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,n为第一项目的名称的数量;
所述原数据库预先录入的若干第二项目的名称的集合为
θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,m为第二项目的名称的数量;
确定单元,用于按照以下公式,分别计算每个第一项目的名称ai与第二项目的名称bj的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称;|ai∩bj|表示第一项目的名称ai与第二项目的名称bj之间相同字符数,|ai∪bj|表示第一项目的名称ai与第二项目的名称bj的所有字符数;
确定满足以下条件的第二项目的名称bj,将满足所述条件的第二项目的名称bj作为有效第二项目的名称bm,
所述条件为:
p≤|jδ(ai,bj)|≤k;
确定所述有效第二项目的名称bm的评价系数jm,且:
其中,p为相似度的预设最小临界值,k为相似度的预设最大临界值,qm为有效第二项目的名称bm的历史匹配次数;c为相似度jδ(ai,bm)的权重系数;d为qm的权重系数;q0为qm的预设临界值;
将与评价系数jm的最大值所对应的有效第二项目的名称bm作为当前计算的第一项目的名称ai的相似度最高的第二项目的名称。
进一步的,
所述的第一项目的名称和第二项目的名称分别包括维度、指标、时间单位、计量单位、类别单位、天气单位、电能单位、向量单位中的任意一种或多种。
本发明技术方案,具有如下优点:
1.本发明提供的自动报表存储方法能够对报表中的词语进行识别,并将报表中的第一项目的名称和原数据库中的第二项目的名称进行相似度计算,当第一项目的名称和第二项目的名称的相似度为完全相同时,将第一项目的名称中对应的第一数据录入原数据库中并与第二项目的名称相对应,进而快速的完成将第一项目的名称对应的第一数据录入至原数据库中。
2.本发明通过将报表中的词语与原数据库中的词语进行分析识别,进而将报表中的数据录入至原数据库中,完成报表内数据的转移、存储,本发明相较于现有技术中报表的自动存储具有最大的区别及优点在于本发明的报表处的标题名称与原数据库中的标题名称并不是通过行、列进行匹配,而是通过名称(即文本)的相似度分析得来,使得报表在导入原数据库的过程中不再局限于格式,并且增加了报表内数据导入至原数据库中的效率。
3.并且本发明适用范围较广,可适用于例如统计年鉴,价格采集,数据填报等业务领域。
4.本发明具有独有数据匹配方式,采用文本相似度计算的方法,用文本挖掘方法使excel中找出与原数据库中相同或者最相似的数据集,改变原有人工数据库查找匹配方式。
5.将当前报表和原数据库中录入过得报表进行相似度计算,形成相似表记忆功能,从已完成的工作结果集中计算最相似的报表快速直接匹配,全部或部分继承和复用已有匹配结果,进而使报表匹配效率和速度有效提升。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为自动报表存储方法的流程图;
图2为自动报表存储系统的结构示意图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
一种自动报表存储方法,如图1所示其流程图,包括调取至少一个报表,对报表内的各个项目的名称进行处理,生成若干第一项目的名称,每个第一项目的名称分别对应有第一数据,其中第一项目的名称可分别包括维度、指标、时间单位、计量单位、类别单位、天气单位、电能单位、向量单位中的任意一种或多种,例如粮食产量、员工人数等等,其中粮食产量对应的第一数据可以是100万斤、200万斤等等,员工人数对应的第一数据可以是80人、800人等等。
在原数据库中预录入若干第二项目的名称,其中第二项目的名称可分别包括维度、指标、时间单位、计量单位、类别单位、天气单位、电能单位、向量单位中的任意一种或多种,例如粮食产量、员工人数等等。
将其中一个第一项目的名称与若干第二项目的名称分别进行相似度处理,例如其中一个第一项目的名称为粮食产量且其对应的第一数据为100万斤,若干第二项目的名称包括粮食产量、员工人数以及钢铁产量等等。
第一项目的名称与其中一个第二项目的名称的相似度完全相同(例如相似度为100%,此时表示第一项目的的名称与第二项目的名称完全相同),将报表内第一项目的名称所对应的第一数据与该第一项目的名称相似度完全相同的第二项目的名称绑定。由于第二项目的名称包括粮食产量,第一项目的名称也为粮食产量,所以第一项目的名称与其中一个第二项目的名称的相似度完全相同,此过程完成第一项目的名称与第二项目的名称的匹配。其中第一项目的名称为粮食产量且其对应的第一数据为100万斤,则将第一数据对应的100万斤与第二项目的名称进行绑定,完成将报表内第一项目的名称对应的第一数据录入至原数据库中并与第二项目的名称相对应,使100万斤与原数据库中的第二项目的名称相对应。
在一个实施例中,第一项目的名称与其中一个第二项目的名称中的相似度完全相同,将报表内第一项目的名称所对应的第一数据与该第一项目的名称相似度完全相同的第二项目的名称绑定后,在所述的第一项目的名称与其中一个第三项目的名称中的相似度为不完全相同时(即相似度小于100%),还包括以下步骤,第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阈值,输出一个或多个第二项目的名称,当第一项目的名称与其中一个或多个第二项目的名称不完全相同时,会对第一项目的名称与第二项目的名称中的相似度进行计算,进而输出一个或多个第二项目的名称。例如第一项目的名称为粮食产量,若干第二项目的名称包括钢铁产量、员工人数、食品产量,此时没有与第一项目的名称相似度完全相同的第二项目的名称,则根据相似度计算输出大于预设阈值的第二项目的名称,比如输出食品产量。
在一个实施例中,上述的当第一项目的名称与其中一个或多个第二项目的名称不完全相同时,会对第一项目的名称与第二项目的名称中的相似度进行计算,进而在所述的第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阈值输出一个或多个第二项目的名称,包括以下步骤s1-s5:
s1,统计第一项目的名称的文本个数,例如第一项目的名称为粮食产量,文本个数为4个。
s2,分别统计若干第二项目的名称的文本个数,例如第二项目的名称包括钢铁产量、员工人数、食品产量、果汁、威化饼等等,其中钢铁产量、员工人数、食品产量的第二项目的名称文本个数为4个、果汁的第二项目的名称文本个数为2个、威化饼的第二项目的名称文本个数为3个。
s3,将第二项目的名称的文本个数与第一项目的名称的文本个数进行第一次相似度比较,比较后可知钢铁产量、员工人数、食品产量的第二项目的名称文本个数与第一项目的名称的文本个数相同,并将第二项目的名称的按照与第一项目的名称的个数相似度进行冒泡排序。
s4,选出与第一项目的名称文本个数相同的第二项目的名称,即将文本个数为4个字的第二项目的名称选出。
s5,将第二项目的名称的字符与第一项目的名称的字符进行第二次相似度比较,将钢铁产量、员工人数、食品产量等进行第一次相似度比较后的第二项目的名称进行字符之间的比较,其中第一项目的名称中的粮食产量包括字符“粮”、“食”、“产”、“量”,并将具有与第一项目的名称相同字符的第二项目的名称进行输出。第二项目的名称的钢铁产量包括“钢”、“铁”、“产”、“量”,与第一项目的名称中有2个字符相同、第二项目的名称的员工人数包括“员”、“工”、“人”、“数”,与第一项目的名称中有0个字符相同,第二项目的名称的食品产量包括“食”、“品”、“产”、“量”,与第一项目的名称中有3个字符相同,此时将员工人数及食品产量的第二项目的名称输出。
第一项目的名称与其中一个或多个第二项目的名称中的相似度小于预设阈值,输出所述的第一项目的名称,其中小于第一预设阈值可以是没有第一项目的名称文本个数相同的第二项目的名称或者是没有与第一项目的名称具有相同字符的第二项目的名称。
其中还包括接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,其中第一项目的名称为粮食产量、水果产量等等,n为第一项目的名称的数量。原数据库预先录入的若干第二项目的名称的集合为θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,第二项目的名称可以包括包括钢铁产量、员工人数、食品产量、果汁、威化饼等等,m为第二项目的名称的数量。
按照以下公式,分别计算每个第一项目的名称ai与第二项目的名称bj的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称;|ai∩bj|表示第一项目的名称ai与第二项目的名称bj之间相同字符数,|ai∪bj|表示第一项目的名称ai与第二项目的名称bj的所有字符数。通过以上方式,可分别计算每个第二项目的名称与当前计算的第一项目名称的相似度。
确定满足以下条件的第二项目的名称bj,将满足条件的第二项目的名称bj作为有效第二项目的名称bm,
条件为:
p≤|jδ(ai,bj)|≤k;
确定有效第二项目的名称bm的评价系数jm,且:
其中,p为相似度的预设最小临界值,k为相似度的预设最大临界值,qm为有效第二项目的名称bm的历史匹配次数;c为相似度jδ(ai,bm)的权重系数;d为qm的权重系数;q0为qm的预设临界值,将与评价系数jm的最大值所对应的有效第二项目的名称bm作为当前计算的第一项目的名称ai的相似度最高的第二项目的名称。在通过以上的条件,根据评价系数jm能够客观的反应出与第一项目的名称ai最相匹配的第二项目的名称bm,因为有bm的历史匹配次数qm作为参考值,并不是只简单的进行字符的匹配,使得本发明的以上方法更加的全面。
获取当前报表的当前特征信息,其中当前报表的特征信息包括名字、文本及字符中的任意一种。获取之前将数据存入过原数据库中的报表的原始特征信息,其中原始特征信息包括名字、文本及字符中的任意一种。计算所述当前特征信息与原始特征信息之间的相似度,报表的相似度计算方法与上述第一项目的名称和第二项目的名称相似度的计算方法相同。当当前特征信息与原始特征信息相似度为大于等于一阈值时,优先获取获取与原始特征信息相对应报表的第二项目的名称,进而提高第一项目名称与第二项目名称的匹配效率。通过以上方式,将当前报表和原数据库中录入过得报表进行相似度计算,形成相似表记忆功能,从已完成的工作结果集中计算最相似的报表快速直接匹配,全部或部分继承和复用已有匹配结果,进而使报表匹配效率和速度有效提升。
一种自动报表存储系统,如图2所示其结构示意图,包括:调取装置,用于调取至少一个报表,对报表内的各个标题文本进行处理,生成若干第一项目的名称,所述的每个第一项目的名称分别对应有第一数据;预录入装置,用于在原数据库中预录入若干第二项目的名称;相似度计算装置,用于将其中一个第一项目的名称与若干第二项目的名称分别进行相似度处理;绑定装置,用于在第一项目的名称与其中一个第二项目的名称中的相似度完全相同,将报表内第一项目的名称所对应的第一数据与该第一项目的名称相似度完全相同的第二项目的名称绑定。
第一相似度比对子单元,用于在第一项目的名称与其中一个或多个第二项目的名称中的相似度大于预设阈值时,输出所述的一个或多个第二项目的名称;第二相似度比对子单元,用于在第一项目的名称与其中一个或多个第二项目的名称中的相似度小于预设阈值时,输出所述的第一项目的名称。
在一个实施例中,相似度比对装置还包括:
第一标题文本接收单元,用于接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,n为第一项目的名称的数量;
所述原数据库预先录入的若干第二项目的名称的集合为θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,m为第二项目的名称的数量;
确定单元,用于按照以下公式,分别计算每个第一项目的名称与第二项目的名称的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称;|ai∩bj|表示第一项目的名称ai与第二项目的名称bj之间相同字符数,|ai∪bj|表示第一项目的名称ai与第二项目的名称bj的所有字符数。通过以上方式,可分别计算每个第二项目的名称与当前计算的第一项目名称的相似度。
在一个实施例中,还包括第一标题文本接收单元,用于接收报表内存有的若干第一项目的名称ai,第一项目的名称ai的集合为θ1=(a1,a2,l,ai,l,an),ai表示其中第i个第一项目的名称,n为第一项目的名称的数量;
所述原数据库预先录入的若干第二项目的名称的集合为θ2=(b1,b2,l,bj,l,bm),bj表示其中第j个第二项目的名称,m为第二项目的名称的数量;
确定单元,用于按照以下公式,分别计算每个第一项目的名称ai与第二项目的名称bj的相似度:
其中,ai表示当前计算的第i个第一项目的名称,bj表示其中第j个第二项目的名称;|ai∩bj|表示第一项目的名称ai与第二项目的名称bj之间相同字符数,|ai∪bj|表示第一项目的名称ai与第二项目的名称bj的所有字符数;
确定满足以下条件的第二项目的名称bj,将满足所述条件的第二项目的名称bj作为有效第二项目的名称bm,
所述条件为:
p≤|jδ(ai,bj)|≤k;
确定所述有效第二项目的名称bm的评价系数jm,且:
其中,p为相似度的预设最小临界值,k为相似度的预设最大临界值,qm为有效第二项目的名称bm的历史匹配次数;c为相似度jδ(ai,bm)的权重系数;d为qm的权重系数;q0为qm的预设临界值,将与评价系数jm的最大值所对应的有效第二项目的名称bm作为当前计算的第一项目的名称ai的相似度最高的第二项目的名称。在通过以上的条件,根据评价系数jm能够客观的反应出与第一项目的名称ai最相匹配的第二项目的名称bm,因为有bm的历史匹配次数qm作为参考值,并不是只简单的进行字符的匹配,使得本发明的以上方法更加的全面。
显然,上述实施例仅仅是为清楚地说明所作的举例,而并非对实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。而由此所引伸出的显而易见的变化或变动仍处于本发明创造的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!