模型的在线训练方法、服务器及存储介质与流程
本发明涉及数据处理技术领域,尤其涉及一种模型的在线训练方法、服务器及计算机可读存储介质。
背景技术
随着人工智能(artificialintelligence,ai)的迅速发展,利用模型训练进行深度学习的技术手段也广泛的运用于各领域中。目前的模型训练主要依赖于静态的数据进行离线训练,也即是说基于内部获得的静态数据进行训练。这种离线训练机制对于实时要求较高的场景的适用性较差,同时也不适用于需要大量外部数据进行深度学习的场景。
技术实现要素:
鉴于以上内容,本发明提供一种模型的在线训练方法、服务器及计算机可读存储介质,其主要目的在于定向抓取外部数据,实现全自动化模型的在线训练。
为实现上述目的,本发明提供一种模型的在线训练方法,该方法包括:
爬取步骤:接收用户发送的种子网页,利用爬虫工具爬取该种子网页内的所有网页链接;
筛选步骤:利用预设的筛选器筛选出符合要求的网页链接;
预处理步骤:从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集;
调用步骤:利用etl处理方式将得到的可用词集按照预设格式存储到数据库中,作为训练数据,并调用模型对训练数据进行在线训练;
生成步骤:调整模型参数,验证模型准确性,生成完整的模型;
存储步骤:将生成的模型存储到模型服务器的指定目录。
优选地,所述筛选步骤还包括:
根据具体的模型训练设置相应的网址库,筛选器访问网页链接所指向的页面,并将访问的网页链接分配到对应的网址库。
优选地,所述预处理包括网页清洗、分词、去停用词。
优选地,所述网页清洗的步骤包括:
利用正则表达式提取出网页中关于标题、关键字及描述的文本;
利用正则表达式清洗所述文本中与网页内容无关的信息。
优选地,所述etl处理方式是指通过抽取、转换、加载的方式对数据进行处理的过程。
优选地,所述生成步骤包括:
将训练数据分为训练集和验证集;
将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn的变量x1、x2、……、xn中训练,自动调整模型参数b1,b2,……,bn;
将验证集代入该模型中进行验证,得到完整的模型。
此外,本发明还提供一种服务器,该服务器包括:存储器、处理器及显示器,所述存储器上存储模型在线训练程序,所述模型在线训练程序被所述处理器执行,可实现如下步骤:
爬取步骤:接收用户发送的种子网页,利用爬虫工具爬取该种子网页内的所有网页链接;
筛选步骤:利用预设的筛选器筛选出符合要求的网页链接;
预处理步骤:从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集;
调用步骤:利用etl处理方式将得到的可用词集按照预设格式存储到数据库中,作为训练数据,并调用模型对训练数据进行在线训练;
生成步骤:调整模型参数,验证模型准确性,生成完整的模型;
存储步骤:将生成的模型存储到模型服务器的指定目录。
优选地,所述筛选步骤还包括:
根据具体的模型训练设置相应的网址库,筛选器访问网页链接所指向的页面,并将访问的网页链接分配到对应的网址库。
优选地,所述生成步骤包括:
将训练数据分为训练集和验证集;
将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn的变量x1、x2、……、xn中训练,自动调整模型参数b1,b2,……,bn;
将验证集代入该模型中进行验证,得到完整的模型。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中包括模型在线训练程序,所述模型在线训练程序被处理器执行时,可实现如上所述模型的在线训练方法中的任意步骤。
本发明提出的模型的在线训练方法、服务器及计算机可读存储介质,通过用户指定的种子网页利用爬虫工具爬取所有的网页链接,并筛选出符合要求的网页。接着,获取网页的网页源码,进行预处理,得到可用词集存到数据库中。最后,利用数据库中的数据进行训练,调整参数,验证准确性,将完整的模型存到指定目录,从而能够根据动态数据自动完成模型的在线训练。
附图说明
图1为本发明服务器较佳实施例的示意图;
图2为图1中模型在线训练程序较佳实施例的模块示意图;
图3为图2中程序模块的功能示意图;
图4为本发明模型的在线训练方法较佳实施例的流程图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本领域的技术人员知道,本发明的实施方式可以实现为一种方法、装置、设备、系统或计算机程序产品。因此,本发明可以具体实现为完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
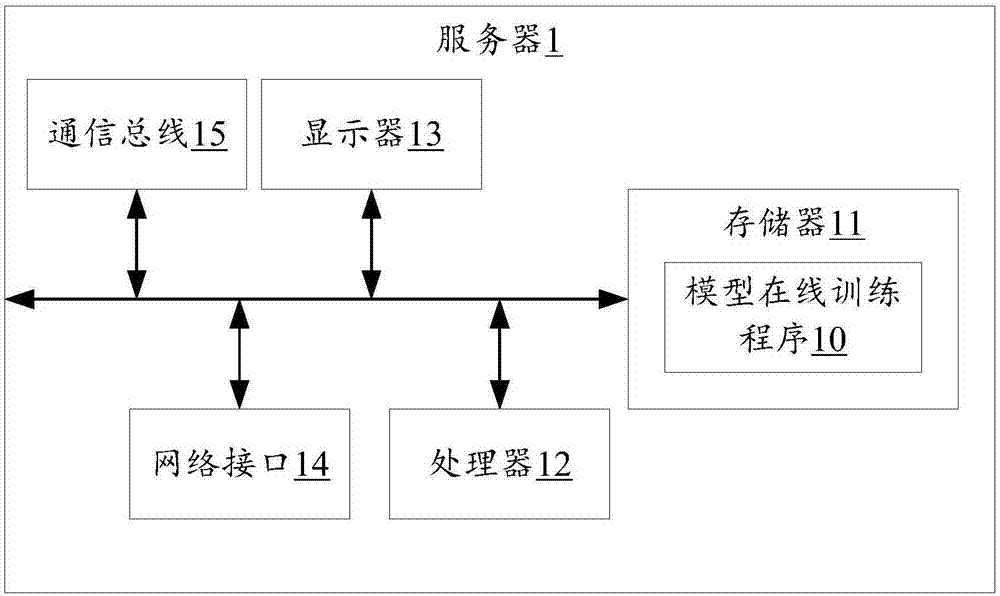
如图1所示,是本发明服务器1较佳实施例的示意图。
在本实施例中,服务器1是指产品服务平台,该服务器1可以是服务器、平板电脑、个人电脑、便携计算机以及其它具有运算功能的电子设备。
该服务器1包括:存储器11、处理器12、显示器13、网络接口14及通信总线15。其中,网络接口14可选地可以包括标准的有线接口、无线接口(如wi-fi接口)。通信总线15用于实现这些组件之间的连接通信。
存储器11至少包括一种类型的可读存储介质。所述至少一种类型的可读存储介质可为如闪存、硬盘、多媒体卡、卡型存储器等的非易失性存储介质。在一些实施例中,所述存储器11可以是所述服务器1的内部存储单元,例如该服务器1的硬盘。在另一些实施例中,所述存储器11也可以是所述服务器1的外部存储单元,例如所述服务器1上配备的插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)等。
在本实施例中,所述存储器11不仅可以用于存储安装于所述服务器1的应用软件及各类数据,例如模型在线训练程序10、网页链接及可用词集等。
处理器12在一些实施例中可以是一中央处理器(centralprocessingunit,cpu),微处理器或其它数据处理芯片,用于运行存储器11中存储的程序代码或处理数据,例如执行模型在线训练程序10的计算机程序代码等。
显示器13可以称为显示屏或显示单元。在一些实施例中显示器13可以是led显示器、液晶显示器、触控式液晶显示器以及有机发光二极管(organiclight-emittingdiode,oled)触摸器等。显示器13用于显示在服务器1中处理的信息以及用于显示可视化的工作界面,例如显示预处理后得到的可用词集。
图1仅示出了具有组件11-15以及模型在线训练程序10的服务器1,但是应理解的是,并不要求实施所有示出的组件,可以替代的实施更多或者更少的组件。
可选地,该服务器1还可以包括用户接口,用户接口可以包括输入单元比如键盘(keyboard)、语音输出装置比如音响、耳机等,可选地用户接口还可以包括标准的有线接口、无线接口。
可选地,该服务器1还包括触摸传感器。所述触摸传感器所提供的供用户进行触摸操作的区域称为触控区域。此外,这里所述的触摸传感器可以为电阻式触摸传感器、电容式触摸传感器等。而且,所述触摸传感器不仅包括接触式的触摸传感器,也可包括接近式的触摸传感器等。此外,所述触摸传感器可以为单个传感器,也可以为例如阵列布置的多个传感器。用户可以通过触摸所述触控区域启动模型在线训练程序10。
此外,该电子装置1的显示器的面积可以与所述触摸传感器的面积相同,也可以不同。可选地,将显示器与所述触摸传感器层叠设置,以形成触摸显示屏。该装置基于触摸显示屏侦测用户触发的触控操作。
该服务器1还可以包括射频(radiofrequency,rf)电路、传感器和音频电路等等,在此不再赘述。
在图1所示的服务器1实施例中,作为一种计算机存储介质的存储器11中存储模型在线训练程序10的程序代码,处理器12执行模型在线训练程序10的程序代码时,实现如下步骤:
爬取步骤:接收用户发送的种子网页,利用爬虫工具爬取该种子网页内的所有网页链接;
筛选步骤:利用预设的筛选器筛选出符合要求的网页链接;
预处理步骤:从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集;
调用步骤:利用etl处理方式将得到的可用词集按照预设格式存储到数据库中,作为训练数据,并调用模型对训练数据进行在线训练;
生成步骤:调整模型参数,验证模型准确性,生成完整的模型;
存储步骤:将生成的模型存储到模型服务器的指定目录。
具体原理请参照下述图2关于模型在线训练程序10较佳实施例的模块示意图及图4关于模型的在线训练方法较佳实施例的流程图的介绍。
如图2所示,是图1中模型在线训练程序10较佳实施例的模块示意图。
在本实施方式中,以旅游推荐模型为例阐述本发明提供的模型的在线训练方法、程序及服务器的技术构思,其他类型模型同样适用。
本发明所称的模块是指能够完成特定功能的一系列计算机程序指令段。
在本实施例中,模型在线训练程序10包括:爬取模块110、筛选模块120、预处理模块130、调用模块140、生成模块150及存储模块160。
以下结合图3的程序模块的功能示意图说明模块110-160的功能:
爬取模块110,用于接收用户2发送的种子网页,利用爬虫工具爬取该种子网页内的所有网页链接。其中,所述种子网页是用户预先设定的网页。利用爬虫工具爬取该种子网页内的网页链接是不定向的,只要是该种子网页内的网页链接都爬取出来。所述爬虫工具可以为beautifulsoup、scrapy、mechanize及cola的一种或几种。
筛选模块120,用于利用预设的筛选器筛选出符合要求的网页链接。之后,筛选模块120根据具体的模型训练设置相应的网址库31,筛选器访问网页链接所指向的页面,并将访问的网页链接分配到对应的网址库31。例如,根据旅游推荐模型设置游记网址库及问答网址库,游记网址库用于存储游记链接,问答网址库用于存储问答链接。筛选器分析网页链接所指向的页面,判断每个网页链接是属于游记链接或者是问答链接,并将每个网页链接分配到对应的网址库31。所述筛选器包括但不限于jquery筛选器,还可以是其它网页意图筛选器。但应理解的是,所述旅游推荐模型对应的网址库31包括但不限于游记网址库及问答网址库。
预处理模块130,用于从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集。所述预处理包括网页清洗、分词、去停用词。其中,所述网页清洗包括:利用正则表达式提取出网页中关于标题、关键字及描述的文本;利用正则表达式清洗所述文本中与网页内容无关的信息。由于网页除了包含主题信息和标题外,还有大量与网页主题无关的内容。因此,采用正则表达式从网页中提取出<title>、<keywords>、<description>该3个标签中的文本部分,所述3个标签分别代表网页的标题、关键字及描述。但提取出的文本还包含javascript脚本代码、css样式代码和html标签等于网页内容无关的信息,因此,采用正则表达式进一步清洗,得到无噪音的网页正文信息。对无噪音的网页正文信息进行分词,所述分词可以采用基于词典的分词方法、基于理解的分词方法和基于统计的分词方法中的一种或几种。优选地,本发明使用结巴分词对所述筛选文本进行分词处理。分词后,网页内容被切分成一个个词语,词语间用斜杠作为标示符。最后使用去停用词将信息量较少的词语去除,得到可用词集。其中,所述去停用词的具体处理步骤包括:存储相关信息量少的词语,如“的”、“是”、“都”、“而且”、“已经”等等。接着,将分词后的网页内容中的一个个词语与存储的词语进行对比,并将网页内容中与存储词语相同的词语去除,得到信息量大的词语。
调用模块140,用于利用etl处理方式将得到的可用词集按照预设格式存储到数据库32中,作为训练数据,并调用模型对训练数据进行在线训练。所述etl处理方式是指通过抽取、转换、加载的方式对数据进行处理的过程。例如,在存储到数据库32之前,利用etl处理方式抽取出所需要的数据,并转换成预设格式加载到数据库32中。当需要调用时,也可以利用etl处理方式从数据库32中抽取出所需要的训练数据,并加载到模型中训练。其中,所述etl工具可以是informatica、datastage、owb、微软dts、beeload、kettle等的一种或几种。
生成模块150,用于调整模型参数,验证模型准确性,生成完整的模型。所述具体的在线训练过程包括:将训练数据分为训练集和验证集;将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn的变量x1、x2、……、xn中训练,自动调整模型参数b1,b2,……,bn;将验证集代入该模型中进行验证,得到完整的模型。假设,预设阈值为98%,将验证集代入模型,验证准确率达到98%时,该旅游推荐模型为完整模型。但应理解的是,所述模型包括但不限于多元回归模型,还可以包括长短期记忆模型(long-shorttermmemory,lstm)卷积神经网络模型(convolutionalneuralnetwork,cnn)及循环神经网络模型(recurrentneuralnetwork,rnn)等。针对不同类型的训练,选择不同类型的模型进行模型训练。例如,热点事件的分类可以用到lstm模型等。
存储模块160,用于将生成的模型存储到模型服务器的指定目录。例如,将生成完整的旅游推荐模型存储到指定目录。进一步地,当数据库32中的数据更新时,抓取数据库32中的数据进行训练,自动调整参数,得到新生成的旅游推荐模型替换之前的旅游推荐模型保存到指定目录。
在另一个实施例中,当模型训练完成后,还可以通过预设方式向用户发送反馈信息,提示用户其所需要的模型训练已完成。例如,通过邮件的方式向用户的邮箱发送提示信息:“您需要的模型已训练完成,请在指定的目录查看,谢谢!”
如图4所示,是本发明模型的在线训练方法较佳实施例的流程图。
在本实施例中,处理器12执行存储器11中存储的模型在线训练程序10的计算机程序时实现模型的在线训练方法包括:步骤s10-步骤s60:
步骤s10,接收用户2发送的种子网页,爬取模块110利用爬虫工具爬取该种子网页内的所有网页链接。其中,所述种子网页是用户设定的。利用爬虫工具爬取该种子网页内的网页链接是不定向的,只要是该种子网页内的网页链接都爬取出来。所述爬虫工具可以为beautifulsoup、scrapy、mechanize及cola的一种或几种。例如,针对旅游推荐模型,接收用户发送的携程网网址:http://www.ctrip.com/,抓取携程网内的所有网页链接,如游记链接:http://you.ctrip.com/travels/xinjiang100008/3643336.html和问答链接:http://you.ctrip.com/asks/shanghai2/5483046.html等。
步骤s20,筛选模块120利用预设的筛选器筛选出符合要求的网页链接。具体包括筛选模块120根据具体的模型训练设置相应的网址库31,筛选器访问网页链接所指向的页面,并将访问的网页链接分配到对应的网址库31。例如,根据旅游推荐模型设置游记网址库及问答网址库,游记网址库用于存储游记链接,问答网址库用于存储问答链接。筛选器分析网页链接所指向的页面,判断每个网页链接是属于游记链接或者是问答链接,并将每个网页链接分配到对应的网址库31。所述筛选器包括但不限于jquery筛选器,还可以是其它网页意图筛选器。但应理解的是,所述旅游推荐模型对应的网址库31包括但不限于游记网址库及问答网址库。例如,所述旅游模型对应的网址库31还可以包括:美食林网址库及口碑榜网址库。
步骤s30,预处理模块130从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集。所述预处理包括网页清洗、分词、去停用词。其中,所述网页清洗包括:利用正则表达式提取出网页中关于标题、关键字及描述的文本;利用正则表达式清洗所述文本中与网页内容无关的信息。由于网页除了包含主题信息和标题外,还有大量与网页主题无关的内容。因此,采用正则表达式从网页中提取出<title>、<keywords>、<description>该3个标签中的文本部分,所述3个标签分别代表网页的标题、关键字及描述。但提取出的文本还包含javascript脚本代码、css样式代码和html标签等于网页内容无关的信息,因此,采用正则表达式进一步清洗,得到无噪音的网页正文信息。对无噪音的网页正文信息进行分词,所述分词可以采用基于词典的分词方法、基于理解的分词方法和基于统计的分词方法中的一种或几种。优选地,本发明使用结巴分词对所述筛选文本进行分词处理。分词后,网页内容被切分成一个个词语,词语间用斜杠作为标示符。例如,“月湾形的龙目岛沙滩拥有着细腻的白色沙滩与温柔的海浪。”分词后得到“月湾形/的/龙目岛/沙滩/拥有着/细腻/的/白色沙滩/与/温柔/的/海浪/。”最后使用去停用词将信息量较少的词语去除,得到可用词集。所述信息量较少的词是指词语中的“的”、“以”、“是”、“而且”、“已经”、“都”、“与”及标点符号等信息量较少的词语。所述去停用词的具体处理步骤包括:存储相关信息量少的词语。接着,将分词后的网页内容中的一个个词语与存储的词语进行对比,并将网页内容中与存储词语相同的词语去除,得到信息量大的词语。例如,所述句子去停用词后得到“龙目岛/沙滩/拥有/沙滩/和/海浪”。
步骤s40,调用模块140利用etl处理方式将得到的可用词集按照预设格式存储到数据库32中,作为训练数据,并调用模型对训练数据进行在线训练。所述etl处理方式是指通过抽取、转换、加载的方式对数据进行处理的过程。在存储到数据库32之前,利用etl处理方式抽取出所需要的数据,并转换成预设格式加载到数据库32中。例如,针对上述游记网站的天数、时间、人均费用、同伴,以及主题和正文信息,根据字段的方式存储在数据库32的表格中。当需要调用时,也可以利用etl处理方式从数据库32中抽取出所需要的训练数据,并加载到模型中训练。其中,所述etl工具可以是informatica、datastage、owb、微软dts、beeload、kettle等的一种或几种。
步骤s50,生成模块150调整模型参数,验证模型准确性,生成完整的模型。所述具体的在线训练过程包括:将训练数据分为训练集和验证集;将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn的变量x1、x2、……、xn中训练,自动调整模型参数b1,b2,……,bn;将验证集代入该模型中进行验证,得到完整的模型。例如,将数据库32的景点信息(包括游记数目、景点数目)、攻略信息(包括旅游天数、旅游时间、人均消费和同伴信息)及每个景点的推荐指数(人为标注的)分为训练集和验证集,将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn中训练,x1、x2、…….、xn代表游记数目、景点数目、旅游天数等变量,自动调整模型参数b1,b2,……,bn,将验证集代入验证,得到准确率高(如98%)的旅游推荐模型。该模型能够根据用户的旅游景点、旅游天数、人均消费、同伴等信息为用户推荐性价比(推荐指数)较高的旅游景点。但应理解的是,所述模型包括但不限于多元回归模型,还可以包括lstm模型、cnn模型及rnn模型等。针对不同类型的训练,选择不同类型的模型进行模型训练。例如,热点事件的分类可以用到lstm模型等。
步骤s60,存储模块160将生成的模型存储到模型服务器的指定目录。例如,将生成完整的旅游推荐模型存储到指定目录。进一步地,当数据库32中的数据更新时,抓取数据库32中的数据进行训练,自动调整参数,得到新生成的旅游推荐模型替换之前的旅游推荐模型保存到指定目录。
在另一个实施例中,当模型训练完成后,还可以通过预设方式向用户发送反馈信息,提示用户其所需要的模型训练已完成。例如,通过邮件的方式向用户的邮箱发送提示信息:“您需要的模型已训练完成,请在指定的目录查看,谢谢!”
上述实施例提出的模型的在线训练方法,通过根据用户的种子网页获取合适的网页链接,对网页链接所指向的网页内容进行预处理,得到可用词集。接着,利用etl处理方式将得到的可用词集存储到数据库32,并调用模型进行训练,调整参数,得到完整的模型,保存到指定目录,从而使得模型能够大量获取外部数据进行在线训练,实现模型训练完全自动化。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质中包括模型在线训练程序10,所述模型在线训练程序10被处理器执行时实现如下操作:
爬取步骤:接收用户发送的种子网页,利用爬虫工具爬取该种子网页内的所有网页链接;
筛选步骤:利用预设的筛选器筛选出符合要求的网页链接;
预处理步骤:从筛选后的网页链接所指向的网页中获取网页源码,对网页源码进行预处理,得到网页的可用词集;
调用步骤:利用etl处理方式将得到的可用词集按照预设格式存储到数据库中,作为训练数据,并调用模型对训练数据进行在线训练;
生成步骤:调整模型参数,验证模型准确性,生成完整的模型;
存储步骤:将生成的模型存储到模型服务器的指定目录。
优选地,所述筛选步骤还包括:
根据具体的模型训练设置相应的网址库,筛选器访问网页链接所指向的页面,并将访问的网页链接分配到对应的网址库。
优选地,所述预处理包括网页清洗、分词、去停用词。
优选地,所述网页清洗的步骤包括:
利用正则表达式提取出网页中关于标题、关键字及描述的文本;
利用正则表达式清洗所述文本中与网页内容无关的信息。
优选地,所述etl处理方式是指通过抽取、转换、加载的方式对数据进行处理的过程。
优选地,所述生成步骤包括:
将训练数据分为训练集和验证集;
将训练集代入构建的多元回归模型y=a+b1x1+b2x2+……+bnxn的变量x1、x2、……、xn中训练,自动调整模型参数b1,b2,……,bn;
将验证集代入该模型中进行验证,得到完整的模型。
本发明之计算机可读存储介质的具体实施方式与上述模型的在线训练方法的具体实施方式大致相同,在此不再赘述。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在如上所述的一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!