一种基于上下文语义的恶意域名语料库生成方法与流程
本发明设计一种基于上下文语义的恶意域名语料库生成方法,该方法分别从恶意域名所在语句的上下文单词、短语进行语义分析,并利用自然语言处理技术自动生成描述恶意域名的语料库。
背景技术:
近年来随着企业各种核心业务逐渐融合互联网,越来越多的组织或者公司都遭受到了各种黑客攻击,各种apt(advancedpersistentthreat)攻击事件层出不穷。为了适应快速变化的网络犯罪技术,安全公司或相关机构也不断发现并溯源重大安全攻击事件,通过不同的渠道(博客、论坛、微博、专业报告等)来披露各种攻击技术细节及恶意域名等信息。这些已公开的攻击分析报告一般采用英文进行书写,其内容主要从攻击事件的目标、攻击者使用的恶意域名、ip地址、恶意工具等进行描述分析。内容中的恶意域名或者ip地址也有可能被黑客用于其它攻击中,为了检测并阻断这些潜在的黑客攻击行为,安全公司往往会将这些恶意域名进行整理并加入防火墙或者杀毒软件的黑名单列表。
目前从文本中提取恶意域名的技术主要还是基于正则表达式和白名单技术,这种技术存在很大的误报率,即没有在白名单列表中的域名不一定就是恶意域名。因此,如何从海量技术文本中自动提取恶意域名在网络攻击检测与防御方面具有重要的作用。
要建立起对恶意域名的自动化低误报率提取模型,前提是由大量的文本数据生成恶意域名语料库。恶意域名语料是指从文本上描述域名安全性的单词或者短语,这些单词或者短语可以从文本语义上进行上下文描述。同时,通过这些语料可以训练有监督学习模型,从而对文本数据中域名的安全性进行标注或者预测。因此,恶意域名语料提取模型为海量文本中恶意域名提取技术提供了一条新思路,并且生成的语料数据可用于各种威胁系统中的域名自动分类技术中。
针对生成恶意域名语料库主要解决的难题在于:
(1)如何解决传统bow模型带来的冗余信息太多、每个短语的信息量较低、提取的正常域名语料和恶意域名语料内容相同等问题。
(2)如何在特征词集中词的数量比较庞大的情况下,使用排序算法对特征词进行重要性分析。
(3)如何解决向量空间模型特征的稀疏性等问题,减少最终生成的恶意语料的维度。
本发明重点对于以上三个问题进行解决,实现一种基于上下文语义的恶意域名语料库生成方法。
技术实现要素:
该发明是基于上下文语义的恶意语料提取算法、基于特征词主成份分析方法、基于单词频度的选择方法、基于tf-idf算法的语料权重计算方法等多项技术设计的先进方法,解决机器学习分类模型中的特征提取问题。
该发明旨在实现如下目标:
(1)仅仅从恶意域名所在句子的上下文语义进行分析,生成可以描述恶意域名的语料(上下文单词、2-gram短语),从而提高语料的有效性。
(2)很多英文停用词和标点符号会在文本中出现多次,同时大部分单词和符号对句子所表达的意思影响很小,因此需要从文本中删除这些停用词和标点符号,提高语料包含的有效信息熵大小。
(3)基于词典的方法对恶意域名语料数据进行处理,利用词典映射查询找到对应词形的原形,还原词的词根形式,减少最终生成的恶意语料的维度。
(4)基于海量数据的统计分析接口得到每个语料的idf值,由计算得到的tf-idf值代表语料描述恶意域名的相关性,得到描述域名安全性的重要程度的量化标准。
(5)总的来说,实现利用机器学习相关理论和模型生成的语料直接用于提取富文本中的恶意域名,为海量文本中恶意域名提取技术提供一种新方向。
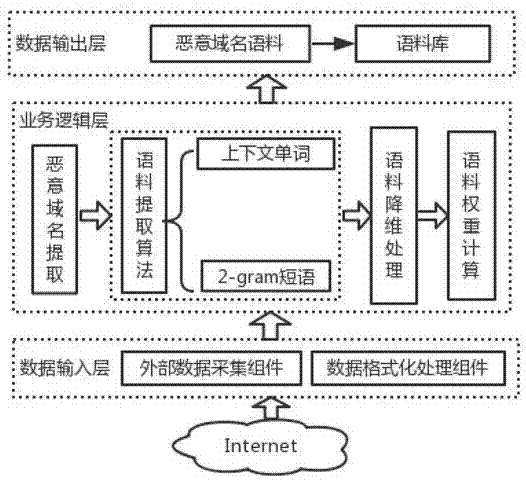
为实现上述目的,该发明采用了如下技术方案:基于上下文语义的恶意域名语料库生成模型总体上由数据输入层、业务逻辑层、数据输出层三部分构成。
数据输入层提供对外部数据的采集,并针对不同类别的数据进行格式化处理。外部数据采集的主要数据源是目前公开的恶意攻击apt攻击分析文章、文档或博客文章,由于包含不同的数据格式,因此需要采用数据格式化处理组件对其进行处理。
业务逻辑层属于恶意域名语料提取模型的核心技术层,实现了从格式化文本数据到最终生成恶意域名语料过程中的所有功能,包含恶意域名提取、语料提取算法、语料降维、权重计算等。
数据输出层提供带有权重的恶意域名语料数据,并可以通过此类数据构建语料库,供其它机器分类模型使用。
附图说明
图1是本发明的提取模型整体框架图
图2是本发明的恶意域名语料提取算法流程图
图3是本发明的恶意域名语料降维方法流程图
图4是本发明的恶意域名权重计算流程图
具体实施方式:
该基于上下文语义的恶意域名语料库生成方法包含五个主要步骤:数据采集格式化,恶意域名提取,语料提取,语料降维,语料权重计算。
如图1所示为模型的主要架构图,详细介绍了恶意域名语料提取模型的相关设计及部署架构。通过对外部数据的采集和格式化处理,经由提取恶意域名、提取语料、语料降维、计算语料权重等步骤,生成相关的恶意域名语料并汇聚入库,供其它机器分类模型使用。
如图2所示为模型包含的恶意域名语料提取算法流程,详细介绍了恶意域名语料的处理生成过程。对外部数据进行采集,由包含恶意域名分析内容的文档集,并针对不同类别的数据进行格式化处理,只提取包含域名的句子。提取句子中所有域名,利用在线域名检测平台对域名进行安全性标注,并选择所有恶意域名。从所有句子中选择含有恶意域名的句子,继续对这些句子进行分词,移除停用词和时态还原等操作,然后将处理后的单词组合成词包,从而得到了上下文单词集合。同时通过2-gram生成算法对上一步含有恶意域名的句子提取短语,从而生成恶意语料库中的2-gram短语。最后将前面处理得到的2-gram短语和上下文单词进行去重。
图3所示为模型包含的恶意域名语料降维方法流程,详细介绍了由原始的恶意域名语料提取有效信息、词形规范化,实现语料降维的流程。通过对文本分类中现有降维方法的分析,同时结合恶意域名语料的实际内容和英文书写特征,本发明提出了基于单词频度的选择方法与基于特征词主成份分析两种方法对恶意域名语料进行降维。
其中基于单词频度的选择方法主要考虑到很多英文停用词和标点符号会在文本中出现多次,同时大部分单词和符号对句子所表达的意思影响很小,其包含的信息熵很小。因此可以直接从文本中删除。停用词主要是用来连接各类词语,但在句子中没有任何含义的词语。通过分析nltk的语料库发现,英文的常用停用词只有127个单词,但是其中一些词语还带有一定的感情色彩或者主观态度,可以影响到整个句子或者目标的含义,例如:no,not,too,very。虽然这些词语属于英文的停用词,但是实验中没有将这些有意义的停用词移除,而其它停用词在分词后进行了删除操作。同理,在句子中的某些标点符号(如:!,?)可以在一定程度上影响被描述的域名,这些字符需要进行保留。另外的一些字符(如:”,$)则对目标域名的描述没有任何帮助,这些字符同样需要删除。
基于特征词主成份分析方法主要考虑词的不同形态归并化处理,即词形规范化,用于降低整个语料的维度。其主要内容包含词形还原和词干提取,词形还原是把一个任何形式的语言词汇还原为一般形式,而词干提取是抽取此的词干或者词根形式。词形还原主要是针对动词在不同的语境和句子中不同的时态进行还原,比如第三人称单数、一般现在时、过去式等。目前这类操作主要有基于规则的方法、基于词典的方法、基于机器学习的方法和混合的方法,其中基于词典的词形还原方法也是最主流的方法。为了实现词的形态还原和词干提取操作,论文采用基于词典的方法对恶意域名语料数据进行处理,其主要思想是利用词典映射查询找到对应词形的原形,从而还原词的词根形式。本发明在实现过程中主要利用nltk和wordnet项目中的词典对语料进行还原操作,借助现有词典进行词形识别、词形和原形的映射,从而减少最终生成的恶意语料的维度。
如图4所示为模型包含的恶意域名权重计算流程,详细的介绍了描述恶意域名相关性重要性权重的计算方法。为了更准确地描述恶意域名语料库中每个语料的重要性,在对语料进行降维之后,需要计算每个语料在语料库中的权重。通过权重计算可以有效地筛选出对分类器比较有用的语料。恶意域名语料在经过前面的降维处理后,语料的维度有所减少,但是针对语料库中的每一个语料的权重则需要利用tf-idf算法进行详细计算。
语料权重计算的详细算法步骤如下:第1步:计算恶意域名语料库(u)中每个语料(w)在语料去重操作前的tf频率值;第2步:通过微软在线api(applicationprogramminginterface)查询接口计算每个语料(w)的idf逆文档频率值;第3步:通过tf-idf公式计算每个语料(w)的权重值;第4步:根据权重值对所有语料进行排序,并返回结果。最后通过如上的处理得到了每个语料的权重值,其值代表了描述域名安全性的重要程度。
本发明的工作过程是:
基于上下文语义的恶意语料提取算法,对外部数据进行采集,由包含恶意域名分析内容的文档集,并针对不同类别的数据进行格式化处理,只提取包含域名的句子。提取句子中所有域名,利用在线域名检测平台对域名进行安全性标注,并选择所有恶意域名。从所有句子中选择含有恶意域名的句子,按顺序使用语料提取算法、语料降维处理算法、语料权重计算算法三个流程对其进行处理,生成恶意域名语料库。该模型解决了机器学习分类模型中的特征提取问题,利用机器学习相关理论和模型生成的语料可以直接用于提取富文本中的恶意域名。
其中,基于上下文语义的恶意语料提取算法改良如下:
1)在传统bow(bag-of-words)模型的基础上引入了上下文语义,仅仅从恶意域名所在句子的上下文语义进行分析,生成可以描述恶意域名的语料(上下文单词、2-gram短语),从而提高语料的有效性。
针对向量空间模型特征的稀疏性等问题的改良如下:
1)语料降维方法结合单词频度和特征词主成份分析方法去降低语料的维度。其中,基于单词频度的选择方法主要为删除低信息熵的停用词和标点符号,基于特征词主成份分析方法主要是利用词典映射查询找到对应词形的原形,还原词的词根形式,实现词形规范化。
每个语料的idf值计算方法改良如下:
1)每个语料的idf值是基于海量数据的统计分析接口得到的,代表了该短语在互联网中的实际分布情况,计算得到的tf-idf值更能代表语料描述恶意域名的相关性。
- 还没有人留言评论。精彩留言会获得点赞!