一种基于宏信息知识迁移的微表情识别方法与流程
本发明属于模式识别以及机器学习技术领域,涉及到核耦合判别局部块对齐方法和迁移支持向量机模型,尤其涉及到一种基于宏信息知识迁移的微表情识别方法。
背景技术:
微表情,也叫面孔微反应,是指人们在受到有效刺激的0.5秒内,不由自主表现出的不受思维控制的瞬间真实反应。微表情是面部肌肉不充分收缩而产生的,它作为微反应的一种,是人类经过长期进化遗传、继承下来的,是人类的本能反应。微表情反映了在人类产生情绪时面部肌肉的运动模式,具有持续时间短、强度低、难以诱导等特征,这使它成为精神心理学和情感分析领域最可靠的生理特征之一。
微表情作为人内在情绪的真实表现,能够揭示一个人的真实情绪,哪怕一个人试图隐藏真正的情绪,面部肌肉的运动、收缩也能够对真实的情绪进行揭示。而微表情的存在时间非常短,最短可只持续1/25秒,通常清醒的做表情的人和观察者都察觉不到微表情的存在,但它却是真实存在的。虽然微表情的持续时间很短,但它可以揭示心里的真实感受,从而为判断人的精神状态提供可靠依据。微表情的研究已经渗透到国家安全、司法审讯、医学临床等领域,尤其是在测谎方面,微表情的识别可以在谈话过程中对说话者是否说谎进行判断。
在微表情识别领域,由于现有的微表情数据库包含的已标记样本过少,在建立微表情识别模型时训练样本过少,所建立的模型不够精确,导致识别率受到相当大的影响。而宏信息(宏表情/语音)数据库样本充足,已标记样本充分,可以建立相对精确的模型,利用宏信息数据库充足的训练样本来辅助微表情的识别,从而提高微表情的自动识别性能,这是一个重要的研究方向。
2017年提出的基于奇异值分解的微表情识别方法,通过奇异值分解的方法将宏信息与微表情相结合,实现宏信息到微表情的迁移,但仅从特征的结合层面入手,模型性能有限;同年提出的基于耦合度量学习的微表情识别模型,提出了新的宏表情、微表情特征描述子,增强特征描述的准确性,通过耦合度量学习算法将宏信息和微表情投影到共同的子空间得到投影矩阵,由于提出了新的特征描述子,识别率得到了提高,但由于没有采用核映射,使得特征的非线性表达能力较差,同时,在分类层面没有进行改进。
技术实现要素:
针对现有技术不足,本发明提供了一种基于宏信息知识迁移的微表情识别方法;
本发明包括核耦合判别局部块对齐方法和迁移支持向量机模型,核耦合判别局部块对齐方法包括核函数映射、局部优化、整体对齐三个部分。
相比于传统的耦合判别局部块对齐方法,本发明采用核函数映射的方案,为了解决光照变化、姿态变化等因素给图像带来非线性分布的问题,本发明采用核函数映射的方案对特征进行抽取,增强特征的非线性表达能力,再在传统的向量空间下进行度量。
迁移支持向量机,相比于传统的支持向量机模型,本发明通过利用统计学理论的结构风险最小化准则,使得共同子空间中的第i维归一化度量值对支持向量进行压制,采用加权方式对支持向量进行调整,大大提高了微表情识别性能和算法的鲁棒性。
本发明通过充分利用充足的已标记宏信息样本以解决微表情训练样本较少的问题。通过核耦合判别局部块对齐对宏信息和微表情进行核映射以增强其非线性表达能力,将宏信息和微表情投影到一个共同子空间。通过迁移支持向量机对微表情进行分类识别,是一种有效的微表情识别方法。
术语解释:
核映射(nuclearmap),一类重要的映射,设x是局部凸空间,y是巴拿赫空间,t是从x到y的线性映射。
本发明的技术方案为:
一种基于宏信息知识迁移的微表情识别方法,包括:
(1)对宏信息样本和微表情样本进行核函数映射;
(2)将核函数映射后的宏信息样本和微表情样本进行局部优化,使得某个样本的k1个类内最近邻样本之间距离最小,使该样本的k2个类间最近邻样本之间的距离最大;
(3)通过整体对齐将步骤(2)得到的局部优化结果累加,使得样本整体的类内距离最小,类间距离最大,得到一组投影矩阵,将宏信息样本和微表情样本投影到一个共同子空间;
(4)通过迁移支持向量机模型进行分类。
根据本发明优选的,所述步骤(1),对宏信息样本和微表情样本进行核函数映射,包括:
设定宏信息样本集合为数据集合
设定源域特征集为x1,x2,……,xm,设定目标域特征集为y1,y2,……,ym,通过核映射φ将原始向量特征映射到高维的特征空间,即将源域特征集x1,x2,……,xm映射为φ(x1),φ(x2),……,φ(xm);将目标域特征集y1,y2,……,ym映射为φ(y1),φ(y2),……,φ(ym)。
本方法选择高斯核函数
根据本发明优选的,所述步骤(2)、步骤(3),包括步骤如下:
a、将核函数映射后的宏信息样本和微表情样本进行局部优化,使得某个样本的k1个类内最近邻样本之间距离最小,使该样本的k2个类间最近邻样本之间的距离最大;
假设这些样本特征均已中心化,为了使得跨域的两组特征在同一子空间中能够计算距离,并且使得计算的距离函数有意义,那么就需要局部优化来指导。
b、整体对齐,即将步骤a得到的局部优化结果进行累加,使得样本整体的类内距离最小,类间距离最大,得到投影矩阵p1和p2,投影矩阵p1、p2分别满足式(ⅰ)、式(ⅱ):
a=p1tφ(x)(ⅰ)
b=p2tφ(y)(ⅱ)
式(ⅰ)、式(ⅱ)中,φ(x)=[φ(x1),φ(x2),…,φ(xm)],φ(y)=[φ(y1),φ(y2),…,φ(ym)];
a是指φ(x)经过投影后在共同子空间中的表示,b是指φ(y)经过投影后在共同子空间中的表示;
c、对于给定的样本φ(xi),1≤i≤m,根据样本集合的类标签信息,将样本φ(xi)的异构样本分为两种,一种为与样本φ(xi)同类的异构样本,另一种为与样本φ(xi)异类的异构样本;
在与样本φ(xi)同类的异构样本中,选择k1个近邻样本按照近邻的顺序排列,表示为
在与样本φ(xi)异类的异构样本中,选择k2个近邻异构样本,按照近邻顺序进行排列,表示为
合并样本φ(xi)的k1个近邻样本与样本φ(xi)的k2个近邻样本,构成样本φ(xi)的局部块
d、对于给定的样本φ(yi),1≤i≤m,根据样本集合的类标签信息,将样本φ(yi)的异构样本分为两种,一种为与样本φ(yi)同类的异构样本,另一种为与样本φ(yi)异类的异构样本;
在与样本φ(yi)同类的异构样本中,选择k1个近邻样本按照近邻的顺序排列,表示为
在与样本φ(yi)异类的异构样本中,选择k2个近邻异构样本,按照近邻顺序进行排列,表示为
合并样本φ(yi)的k1个近邻样本与样本φ(yi)的k2个近邻样本,构成样本φ(yi)的局部块
e、对于每个局部块来说,在共同的子空间中,φ(xi)对应的映射后的共同子空间局部块为
f、在映射后的共同子空间中,使得同类的近邻样本之间的距离最小,异类的近邻样本之间的距离最大,即满足式(iii)、式(ⅳ):
由于在共同子空间中,局部近邻块可以看作为近似线性的,通过线性处理将式(iii)、式(ⅳ)形成局部判别式,如式(ⅴ)所示:
式(ⅴ)中,λ∈[0,1],为量化因子;满足类内距离和类间距离之间的一致性。
定义系数向量wi,如式(ⅵ)所示:
式(ⅴ)简化为式(ⅶ):
式(ⅶ)中,wi=diag(wi),
则对于p1,存在m个样本用来张成核特征空间{φ(xi),i=1,2,…m};对于p2,也存在m个样本用来张成核特征空间{φ(yi),i=1,2,…m},设张成系数分别为α1,α2,…,αm和β1,β2,…,βm,则如式(ⅷ)、式(ⅸ)所示:
令目标函数为
式(ⅹ)中,
由于样本特征中心化不总是满足的,因此将
式(ⅺ)、式(ⅻ)中,1m定义为m×m的系数均为
令
式(xiii)中,z=[z1,z2,…,zm],
给定约束条件ptp=i,i是单位矩阵,将式(xiii)转化成广义特征值求解问题,如式(xiv)所示:
zwztp=θp(xiv)
式(xiv)中,θ为广义特征值;
假设p1,p2,…,pd为前d个最小特征值的特征向量,式(xiv)的最优解如式(xv)所示:
式(xv)中,α*、β*分别为α、β的最优解,p*指的是式(xv)的最优解,为α*、β*的集合。
根据本发明优选的,所述步骤(4),通过迁移支持向量机模型进行分类,包括:
a、给定源域数据集(x1,l1),(x2,l2),(x3,l3),…,(xm,lm),xi为源域的输入向量,i=1,…,m,li为对应的输出值,i=1,…,m,m为样本个数;设φ(x)=[φ(x1),φ(x2),…,φ(xm)],φ(y)=[φ(y1),φ(y2),…,φ(ym)];建立源域的支持向量回归模型,如式(xvi)所示:
f(x)=wtp1tφ(x)+b(xvi)
式(xvi)中,w为权值,b为阈值,p1为源域映射到共同子空间的投影矩阵,φ(x)是经过核映射后的源域样本特征;
建立目标域的支持向量回归模型,如式(xvii)所示:
式(xvii)中,p2为源域映射到共同子空间的另一投影矩阵,φ(y)是经过核映射后的目标域样本特征;
b、通过步骤a建立的支持向量回归模型进行分类。
根据本发明优选的,所述步骤(4),根据统计学理论的结构风险最小化准则,并使得共同子空间中的第i维归一化度量值
式(xviii)中,⊙表示对应度量元素的乘积,
对式(xviii)进一步展开,如式(xix)所示:
(xix)中,
本发明的有益效果是:
本发明提供的是一种基于宏信息知识迁移的微表情识别方法,相比于已有的微表情识别方法,本发明充分利用了充足的已标记的宏信息样本解决微表情训练样本较少的问题。通过核耦合判别局部块对齐方法对宏信息和微表情进行核映射以增强其非线性表达能力,将宏信息和微表情投影到一个共同子空间。通过迁移支持向量机模型对微表情进行分类识别。本发明提出的方法提高了微表情识别性能,具有较强的鲁棒性。
附图说明
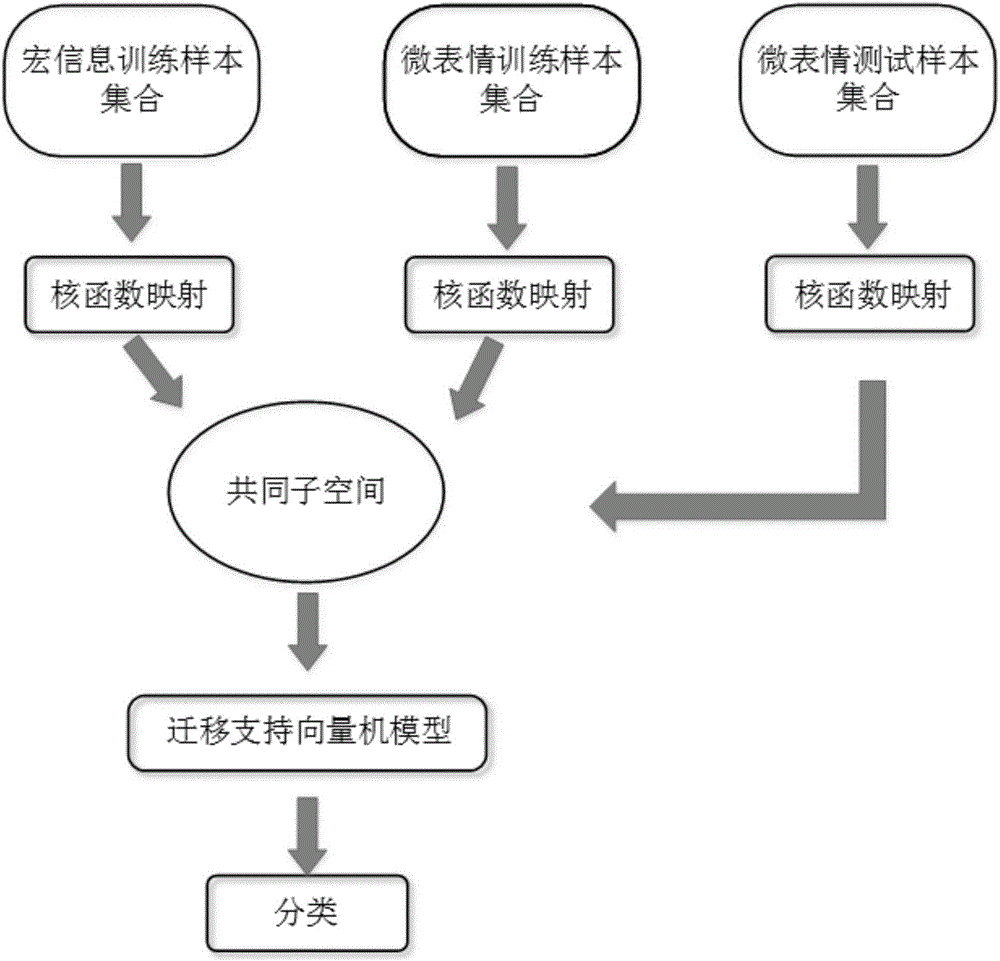
图1为本发明基于宏信息知识迁移的微表情识别方法的流程示意图;
图2为casmeii数据库中的微表情示意图;
图3为27个特征点在人脸的分布示意图。
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
实施例
一种基于宏信息知识迁移的微表情识别方法,如图1所示,包括:
(1)对宏信息样本和微表情样本进行核函数映射;包括:
设定宏信息样本集合为数据集合
设定源域特征集为x1,x2,……,xm,设定目标域特征集为y1,y2,……,ym,通过核映射φ将原始向量特征映射到高维的特征空间,即将源域特征集x1,x2,……,xm映射为φ(x1),φ(x2),……,φ(xm);将目标域特征集y1,y2,……,ym映射为φ(y1),φ(y2),……,φ(ym)。
本方法选择高斯核函数
(2)将核函数映射后的宏信息样本和微表情样本进行局部优化,使得某个样本的k1个类内最近邻样本之间距离最小,使该样本的k2个类间最近邻样本之间的距离最大;
(3)通过整体对齐将步骤(2)得到的局部优化结果累加,使得样本整体的类内距离最小,类间距离最大,得到一组投影矩阵,将宏信息样本和微表情样本投影到一个共同子空间;
步骤(2)、步骤(3),包括步骤如下:
a、将核函数映射后的宏信息样本和微表情样本进行局部优化,使得某个样本的k1个类内最近邻样本之间距离最小,使该样本的k2个类间最近邻样本之间的距离最大;
假设这些样本特征均已中心化,为了使得跨域的两组特征在同一子空间中能够计算距离,并且使得计算的距离函数有意义,那么就需要局部优化来指导。
b、整体对齐,即将步骤a得到的局部优化结果进行累加,使得样本整体的类内距离最小,类间距离最大,得到投影矩阵p1和p2,投影矩阵p1、p2分别满足式(ⅰ)、式(ⅱ):
a=p1tφ(x)(ⅰ)
b=p2tφ(y)(ⅱ)
式(ⅰ)、式(ⅱ)中,φ(x)=[φ(x1),φ(x2),…,φ(xm)],φ(y)=[φ(y1),φ(y2),…,φ(ym)];
a是指φ(x)经过投影后在共同子空间中的表示,b是指φ(y)经过投影后在共同子空间中的表示;
c、对于给定的样本φ(xi),1≤i≤m,根据样本集合的类标签信息,将样本φ(xi)的异构样本分为两种,一种为与样本φ(xi)同类的异构样本,另一种为与样本φ(xi)异类的异构样本;
在与样本φ(xi)同类的异构样本中,选择k1个近邻样本按照近邻的顺序排列,表示为
在与样本φ(xi)异类的异构样本中,选择k2个近邻异构样本,按照近邻顺序进行排列,表示为
合并样本φ(xi)的k1个近邻样本与样本φ(xi)的k2个近邻样本,构成样本φ(xi)的局部块
d、对于给定的样本φ(yi),1≤i≤m,根据样本集合的类标签信息,将样本φ(yi)的异构样本分为两种,一种为与样本φ(yi)同类的异构样本,另一种为与样本φ(yi)异类的异构样本;
在与样本φ(yi)同类的异构样本中,选择k1个近邻样本按照近邻的顺序排列,表示为
在与样本φ(yi)异类的异构样本中,选择k2个近邻异构样本,按照近邻顺序进行排列,表示为
合并样本φ(yi)的k1个近邻样本与样本φ(yi)的k2个近邻样本,构成样本φ(yi)的局部块
e、对于每个局部块来说,在共同的子空间中,φ(xi)对应的映射后的共同子空间局部块为
f、在映射后的共同子空间中,使得同类的近邻样本之间的距离最小,异类的近邻样本之间的距离最大,即满足式(iii)、式(ⅳ):
由于在共同子空间中,局部近邻块可以看作为近似线性的,通过线性处理将式(iii)、式(ⅳ)形成局部判别式,如式(ⅴ)所示:
式(ⅴ)中,λ∈[0,1],为量化因子;满足类内距离和类间距离之间的一致性。
定义系数向量wi,如式(ⅵ)所示:
式(ⅴ)简化为式(ⅶ):
式(ⅶ)中,wi=diag(wi),
则对于p1,存在m个样本用来张成核特征空间{φ(xi),i=1,2,…m};
对于p2,也存在m个样本用来张成核特征空间{φ(yi),i=1,2,…m},
设张成系数分别为α1,α2,…,αm和β1,β2,…,βm,则如式(ⅷ)、式(ⅸ)所示:
令目标函数为
式(ⅹ)中,
由于样本特征中心化不总是满足的,因此将
式(ⅺ)、式(ⅻ)中,1m定义为m×m的系数均为
令
式(xiii)中,z=[z1,z2,…,zm],
给定约束条件ptp=i,i是单位矩阵,将式(xiii)转化成广义特征值求解问题,如式(xiv)所示:
zwztp=θp(xiv)
式(xiv)中,θ为广义特征值;
假设p1,p2,…,pd为前d个最小特征值的特征向量,式(xiv)的最优解如式(xv)所示:
式(xv)中,α*、β*分别为α、β的最优解,p*指的是式(xv)的最优解,为α*、β*的集合。
(4)通过迁移支持向量机模型进行分类。包括:
a、给定源域数据集(x1,l1),(x2,l2),(x3,l3),…,(xm,lm),xi为源域的输入向量,i=1,…,m,li为对应的输出值,i=1,…,m,m为样本个数;设φ(x)=[φ(x1),φ(x2),…,φ(xm)],φ(y)=[φ(y1),φ(y2),…,φ(ym)];建立源域的支持向量回归模型,如式(xvi)所示:
f(x)=wtp1tφ(x)+b(xvi)
式(xvi)中,w为权值,b为阈值,p1为源域映射到共同子空间的投影矩阵,φ(x)是经过核映射后的源域样本特征;
建立目标域的支持向量回归模型,如式(xvii)所示:
式(xvii)中,p2为源域映射到共同子空间的另一投影矩阵,φ(y)是经过核映射后的目标域样本特征;
b、通过步骤a建立的支持向量回归模型进行分类。
步骤(4),根据统计学理论的结构风险最小化准则,并使得共同子空间中的第i维归一化度量值
式(xviii)中,⊙表示对应度量元素的乘积,
对式(xviii)进一步展开,如式(xix)所示:
(xix)中,
通过在ck+宏表情数据库、casia中华情感语料库、casmeii微表情数据库上验证本发明所提算法来评估本专利所提出的算法的有效性。对于宏表情,采用左风火轮模式特征描述子(lhwp)作为其特征描述,对于微表情,采用左风火轮模式-三正交平面特征描述子(lhwp-top)作为其特征描述,之后采用核函数对其进行核映射。对于语音特征,本节的实验采用语音的基本频率、短时能量、共振峰和mfcc等统计量作为语音情感特征。
casmeii微表情数据库的微表情样本如图2所示。由于casmeii微表情数据库中与ck+表情数据库对应的标签为恐惧和悲伤的样本与其他含有标签的样本相比过少,因此,选取厌恶、高兴和惊讶三类宏表情、微表情样本作为实验数据。随机地从ck+表情数据库中选取885个样本,从casmeii微表情数据库中选取61个样本作为训练样本。此外,为了保证两个域当中样本数量的统一性,从casmeii微表情数据库选取的训练样本按照类别扩充至与ck+表情数据库相同,总体数量扩展到885个。casmeii微表情数据库中剩余的58个样本作为测试样本。
在实验之前的预处理阶段,我们对样本进行尺寸的统一工作,将ck+表情数据库和casmeii微表情数据库中的宏表情、微表情数据统一至相同尺寸以使得局部点的选取更加统一。在本发明中对两种数据库中的样本统一以眉心为中心进行标准化至231×231,以便于后续的处理。对原始图像标准化之后进一步对各幅图像进行局部块提取工作,在标准化之后的图像上选择了27个局部特征点,在人脸中的分布如图3所示,从上到下分别为左眉毛右边缘、右眉毛左边缘、左眉毛左边缘、右眉毛右边缘、左眼睫毛上、右眼睫毛上、左眼左边缘、右眼左边缘、左眼右边缘、右眼右边缘、左眼中心、右眼中心、左眼睫毛下、右眼睫毛下、鼻梁高左、鼻梁高右、鼻梁中左、鼻梁中右、鼻子中心、鼻梁低左、鼻梁低右、人中、嘴唇上、左嘴角、右嘴角、嘴唇中、嘴唇下。之后以局部点为中心分别取21×21,23×23的正方形作为局部块,进行串联,作为图片的局部特征。
casia中国情感语料库中的样本表示了不同的情感,例如高兴、悲伤、愤怒、惊讶、中立等,是通过两位男性和两位女性对50段文本的朗读来取得的。本发明的实验从casia中国情感语料库中随机抽取了300个样本用于模型的训练,包括厌恶、高兴和惊讶三类,随机选取61个样本作为训练样本。此外,为了保证两个域当中样本数量的统一性,从casmeii微表情数据库选取的训练样本扩充至与casia中国情感语料库相同。剩余的58个样本作为测试样本。
选择半径r1=4,r2=5,局部块大小为21×21时的lhwp宏表情特征描述子和lhwp-top微表情特征描述子作为样本特征描述,选择高斯核函数
表1
从表中可以看出,当使某个样本的5个类内最近邻样本之间的距离最小,使某个样本的1个类间最近邻样本之间的距离最大时,识别率能够达到最高值,为91.5%。这是因为通过局部优化和整体对齐,使得每个样本的类内最近邻样本之间的距离达到最小,类间最近邻样本之间的距离达到最大,通过距离度量对样本进行耦合,使得样本投影到一个共同的子空间之后能够满足距离度量条件。同时,在分类上由于采用了权值调整的方式对传统的支持向量机进行了改进,构造了迁移支持向量机模型,从分类层面上做了改进,因而识别率较高。
选择半径r1=4,r2=8,局部块大小为23×23时的lhwp-top微表情特征描述子来作为微表情样本的特征描述,采用统计特征作为语音样本的情感特征描述,选择高斯核函数
表2
从表2中可以看出,当使某个样本的1个类内最近邻样本之间的距离最小,使某个样本的3个类间最近邻样本之间的距离最大时,识别率能够达到最高值,为86.6%。可以看出,宏信息为语音的实验结果相比于宏信息为宏表情的实验结果整体来说要差一些,这是因为对于核耦合判别局部块对齐来说,宏表情样本与微表情样本整体的相似性要高于语音样本与微表情样本的相似性。
- 还没有人留言评论。精彩留言会获得点赞!