一种基于FPGA的可扩展稀疏矩阵向量乘处理器的制作方法
本发明属于fpga技术及高性能计算领域,尤其涉及一种基于fpga的稀疏矩阵向量乘硬件加速器。
背景技术:
对于稀疏矩阵的运算出现在种类繁多的计算学科中,包括图像重建、电路与金融建模、工业工程、压缩感知和近几年非常热门的神经网络中。而在诸多涉及稀疏矩阵的运算中稀疏矩阵与向量之间的乘法运算在上述领域中使用最为频繁,其效率直接决定了整个处理器的运算效率。
目前,稀疏矩阵向量乘运算大都由cpu、gpu或者是cpu-gpu协同运算来完成,然而,能将稀疏矩阵高效存储所需的压缩格式和传统的计算结构并不匹配,导致了在cpu和gpu上对稀疏矩阵运算时的数据吞吐量要远远小于对稠密矩阵进行运算时的数据吞吐量。
近年来,随着集成电路产业发展的蒸蒸日上,使用fpga对稀疏矩阵向量乘法运算进行加速的方案也受到广泛关注。fpga有强大的浮点数运算能力、超大的片上存储以及可以为片外存储提供超大数据带宽的大量高速i/o引脚。同时,fpga良好的灵活性也使得架构可以满足不同实际问题的需求。
技术实现要素:
本发明的目的在于克服上述理论结果的不足,提供一种基于fpga的可扩展稀疏矩阵向量乘处理器,具体由以下技术方案实现:
所述基于fpga的可扩展稀疏矩阵向量乘处理器,包括:
预处理控制器模块,用于调度和冒险检测,使存储单元向运算单元阵列保持连续的数据流;
运算模块,为多个计算单元组成计算单元阵列,通过单精度浮点乘法、加法器,实现单精度浮点稀疏矩阵向量乘运算;
存储控制器模块,控制对片外dram中数据的读写。
所述稀疏矩阵向量乘处理器的进一步设计在于,存储控制器模块控制对dram中稀疏矩阵、输入向量、输出向量的读或写,并根据valid信号进行数据保持。
所述稀疏矩阵向量乘处理器的进一步设计在于,稀疏矩阵以csc压缩存储格式存储于dram中。
所述稀疏矩阵向量乘处理器的进一步设计在于,由预处理控制器模块对运算模块的双口ram中同一地址的写入进行冒险检测,并控制valid信号以规避冒险现象。
所述稀疏矩阵向量乘处理器的进一步设计在于,每个计算单元按照行向量对稀疏矩阵进行分割对输出向量的某一子集进行运算,最后将所有计算单元的得到的最终结果连接起来拼成最终的输出向量。
所述稀疏矩阵向量乘处理器的进一步设计在于,每个计算单元由调度控制器、一个单精度浮点乘法器、一个单精度浮点加法器以及一个双口ram组成,乘法器和加法器用于对多组输入数据进行乘累加运算,运算的中间结果暂存于双口ram中;调度控制器接收预处理控制器的调度信号并对双口ram的读写地址和使能状态进行配置。
本发明的优点如下:
本发明提供的可扩展稀疏矩阵向量乘处理器,可以根据存储器的带宽和运算资源对计算单元的数量进行对应的扩展,并且可以同时对稀疏矩阵向量乘和稀疏矩阵矩阵乘进行高效运算。相比现有的稀疏矩阵向量乘运算方案,本运算器装置拥有更高的数据吞吐量、运算效率和更好的通用性。
附图说明
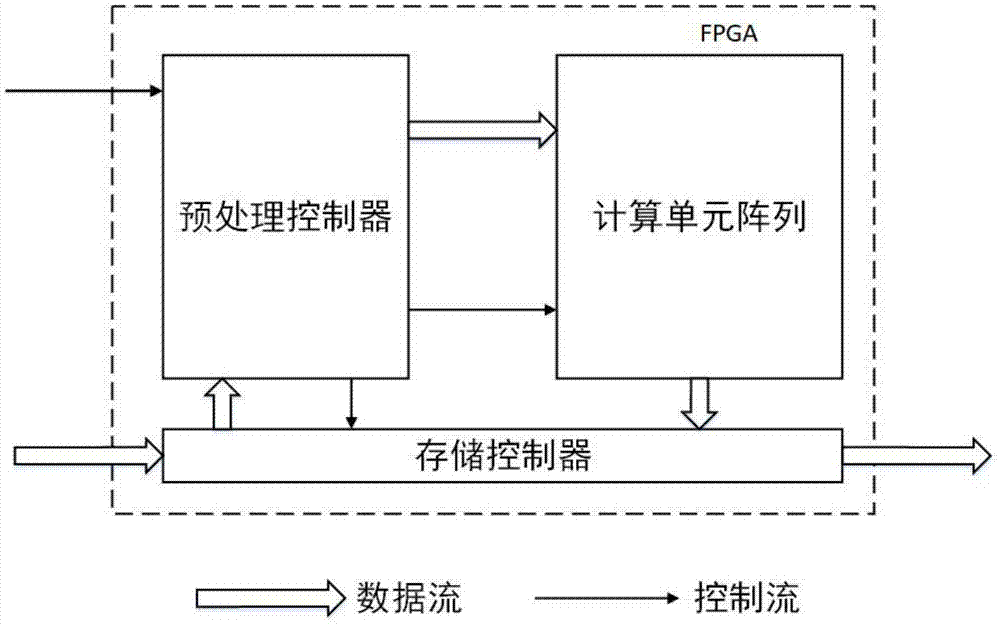
图1是可扩展稀疏矩阵向量乘处理器整体架构图。
图2是可扩展稀疏矩阵向量乘处理器计算单元内部结构示意图。
图3是可扩展稀疏矩阵向量乘处理器计算单元的运行流程图。
图4是可扩展稀疏矩阵向量乘处理器运行的时序图。
具体实施方法
下面结合附图对本发明进行详细说明。
本实施例中可扩展稀疏矩阵向量乘处理器中的稀疏矩阵采用csc压缩存储格式,即使用三个不同的数组来描述稀疏矩阵中非零元素的位置。这三个数组分别是:按照从左上到右下的顺序存放所有非零元素值的data数组、记录每个非零元素对应行号的row数组以及记录每一列第一个非零元素在data数组中序号的ptr数组。图1表示了一个使用压缩存储格式存储的规模为4*5的稀疏矩阵。本实施例中可扩展稀疏矩阵向量乘处理器中的稀疏矩阵采用csc压缩存储格式如下:
如图1,本实施例的可扩展稀疏矩阵向量乘处理器主要由预处理控制器、计算单元阵列、存储控制器组成。配置信息自预处理控制器模块输入,预处理控制器根据配置信息对计算单元阵列和存储控制器模块进行设置。接收到配置信息后,存储控制器读入外部数据并将数据依批次送入预处理控制器进行冒险检测,预处理控制器根据冒险检测的结果对存储控制器和计算单元阵列进行调度。最后输入数据经由计算单元阵列运算完成后将结果由存储控制器输出到片外dram中,整个过程为全流水的。
如图2,计算单元由调度控制器、一个单精度浮点乘法器、一个单精度浮点加法器和一个双口ram组成。乘法器和加法器用于对多组输入数据进行乘累加运算,运算的中间结果暂存于双口ram中。调度控制器接收预处理控制器的调度信号并对双口ram的读写地址和使能状态进行配置。
计算单元的工作过程如图3所示,复位后计算单元处于空闲状态,当接收到预处理控制器给出的“start”信号后,计算单元对内部变量进行初始化,将存放中间结果的双口ram清零。初始化完成后,乘法器计算稀疏矩阵a中的某一非零元素aij和输入向量x中对应元素xj的乘积,同时blockram读取aij在稀疏矩阵中所处的行数i,并将该地址存储的数据送入加法器与之前乘法器中所得的运算结果相加,所得结果再存入blockram的原地址。计算单元还接收预处理控制器给出的“valid”信号,当“valid”信号拉低时,将暂停对blockram的读取操作,直到“valid”信号重新被拉高。当所有计算完成后,计算单元将接收到来自预处理控制器的“end”信号,此时将blockram中储存的运算结果输出到ddr中的相应地址,同时计算单元恢复到空闲状态。
使用上述的稀疏矩阵进行向量乘运算的时序图如图4,假设输入向量x=[1,2,3,4,5]t,浮点乘法器和加法器的延时都为2个时钟周期,blockram的读写延时为1个时钟周期。当运算进行到第2个clk时,由于在相邻时钟周期内的部分乘3*1和1*2需要累加到同一个ram地址中,因此会出现所谓的冒险现象。此时需要将valid信号拉低两个时钟周期,同时保持aij和xj的值不变,以保证在继续运算前3*1的结果已经存入blockram中。如果没有进行冒险检测,那么1*2的将会直接和ram中最先保存的数据0相加,从而得到错误的结果。
本发明实现的可扩展稀疏矩阵向量乘法器装置可以进行浮点稀疏矩阵向量乘运算,也可以进行浮点稀疏矩阵矩阵乘运算。在对预处理控制器进行微小调整即可支持稀疏矩阵和稠密矩阵之间的乘法运算。相比于现有的稀疏矩阵向量乘法器中对存储的不规则随机读取,本装置对存储进行规律的连续数据流读取,拥有更好的通用性和更高的吞吐率。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!