一种基于网格和密度聚类的稀疏源信号盲分离方法与流程
本发明涉及盲信号处理领域,稀疏分量分析领域,具体涉及用于欠定情况下对稀疏源信号混合成的传感器信号进行盲分离的方法。
背景技术:
在欠定盲分离算法中,如果假设在一个时频点有多于一个的源信号不为零,仅采取简单地将时频域分类的方法不能有效地恢复源信号,而需要考虑源信号向量在每个时频点上的结构。这时可以采取稀疏分量分析的方法来进行盲分离。
基于稀疏分量分析的盲源分离算法一般采用二阶段式的工作模式:首先用聚类算法估计混合矩阵,然后对源信号进行恢复。由于估计出的混合矩阵不是方阵,不能用简单的求逆的方式获得源信号的唯一解。稀疏分量分析就是要得到源信号的一组最稀疏解。
将一般的稀疏分量分析直接用于无回响环境下混合信号的分离,存在两个问题:1.信号在时域中的稀疏性不好;2.信号在时频域的稀疏度较好,但是用一般的超平面聚类进行混合矩阵估计时,算法复杂度高且受孤立点的影响较大。因此本发明提出了一个新的欠定情况下的盲分离算法。分离过程分为三个个步骤:将时域的传感器信号进行短时傅里叶变换,估计混合矩阵,恢复源信号。在第二个步骤中,利用源信号的幅度衰减和时间延迟两个特征的聚类中心对混合矩阵参数进行估计,利用网格和密度聚类的方法能快速找到聚类中心。在第三个步骤中,提出了一个更宽松的稀疏条件,即,在同一个时频点,允许多个源信号不为零;通过求最小l1范数解来确定每个时频点不为零的源信号,定义数组矩阵来记录每个网格中不为零的源信号的信息,避免重复计算。
技术实现要素:
本发明所要解决的技术问题是为了克服在传统稀疏分量分析方法中,要求一个时频点只能有一个信号不为零,其他信号必须沉默的限制,提出了更为宽松的稀疏条件;在确定聚类中心时采用了网格和密度聚类;在恢复源信号时,为每个网格定义数组,提高了计算效率。
本发明解决其技术问题所采用的技术方案是:
一种基于网格和密度聚类的稀疏源信号盲分离方法,包括以下几个步骤:
步骤1.将两个传感器信号的混合模型扩展为m个传感器信号的混合模型并进行短时傅里叶变换。时域的模型为:
其中aij和δij分别为第j个源信号到第i个传感器的幅度衰减和时间延迟系数。对上式进行短时傅里叶变换,得到时频域的瞬时混合模型:
相应的聚类特征也变为:a=[1,a2j,…,amj]t,δ=[0,δ2j,…,δmj]t。在每一个时频点(t,f),
步骤2.找出聚类中心,做为混合系数的估计。实际上,在时频域中进行精确的聚类是比较困难的。k均值聚类和超平面聚类的计算复杂度较高,对于每一个代表点的组合,都需要处理数据集内的非代表点,且易受孤立点的影响。另外,算法的收敛性与数据的处理顺序有很大关系。由于各个时频点在a-δ平面的散点分布具有规律性,即,自然地形成以真实混合系数为中心的椭圆形状。
本发明采用网格和密度聚类的方法,来实现所述的找出聚类中心,做为混合系数的估计。
采用均匀划分的方式,为每个(a(t,f),δ(t,f))定义一个平面,称之为a-δ平面,并将其划分为若干个网格。
步骤2.1将a-δ平面离散化为以δa和δδ为步长的小矩形,离散化后的a和δ分别记为(a0,...,ak)和(δ0,…,δl),k,l是分段的个数,并且有
步骤2.2对a-δ平面上的每一个网格(ak,δl)(其中k∈1,…,k,l∈1,…,l),定义m(ak,δl),并用零进行初始化。对于每一个时频点的(a(t,f),δ(t,f)),用下面的规则对m(ak,δl)进行更新:
m(ak,δl)=m(ak,δl)+1
if|a(t,f)-ak|<δaand|δ(t,f)-δl|<δδ
其中l=0,1,…,l。m(ak,δl)的值就是网格(ak,δl)中包含数据点(a(t,f),δ(t,f))的个数,即数据点的密度。在每个时频点(t,f)产生的幅度衰减和时间延迟参数都分布在真实的混合系数周围。那么在a-δ平面上会产生以真实参数为中心的n个峰,也就是聚类中心。可将密度最大的n个网格作为混合系数。
步骤3.源信号的恢复
在欠定情况下,混合矩阵是列满秩的。这种情况下,矩阵的逆是不唯一的,即使能很好地估计混合矩阵,也无法用矩阵的逆求得解混合矩阵。稀疏分量分析中常用方法是求最小l1范数解。
在duet方法中,在每个时频点仅允许一个源信号不为零。在大多数信号中,这种假设过于严格。本发明提出了一个较为宽松的稀疏性条件,即:对于时频域中的每一个时频点,最多可以有m个源信号的值不为零。
将由步骤2得到的混合系数的估计记为:
混合信号的时频域表示可以记为:
将混合矩阵写成列向量的形式:
其中
根据假设条件,如果在每个时频点上,最多只有m个源信号不等于零,那么式(1)中的矩阵
采用下面的方式来求得源信号的最小l1范数解:在矩阵
如果用φ(f)得到的源信号
可以满足
在a-δ平面中,落入同一个网格的时频点具有相同的m个源信号不为零,为了避免重复计算,在估计混合矩阵时划分网格的基础上,为每一个网格定义一个数组:
当首次读入一个样本点(a(t,f),δ(t,f))时,对(a(t,f),δ(t,f))所在的网格h(ak,δl)进行更新:h(ak,δl)=(1,j1,…,jm)。这时,h(ak,δl)中存放的是:第一个值表示当前样本点是否首次读入,如果是,则为0,否则为1;后面的m个值依次表示的是当前样本点(a(t,f),δ(t,f))所选定的混合矩阵列向量的编号。每读入一个样本点,都需要首先判断它所处的网格是否是首次读入。这样,我们不需要对每个样本点计算它所选取的列向量,而是用每个网格所选取的列向量代表其中的样本点。
附图说明
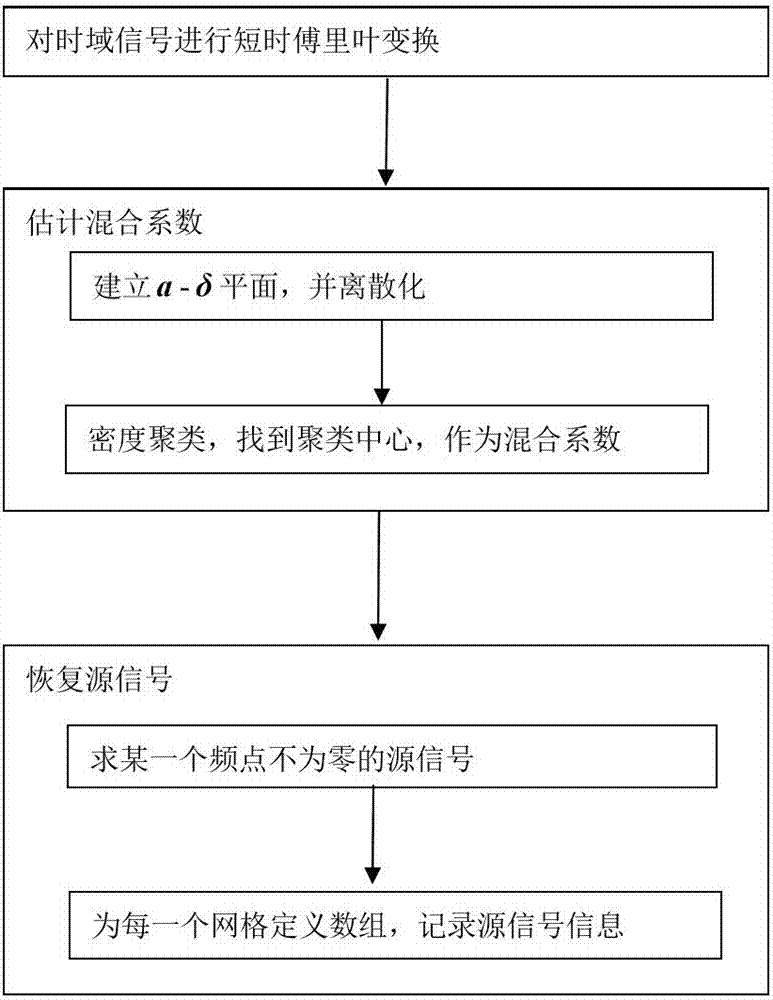
图1为本发明流程图。
具体实施方式
一种基于网格和密度聚类的稀疏源信号盲分离方法,如图1所示,包括以下几个步骤,
具体实施方式如下:
步骤1.将两个传感器信号的混合模型扩展为m个传感器信号的混合模型并进行短时傅里叶变换。得到时频域的瞬时混合模型。
步骤2.采用网格和密度聚类的方法,找出聚类中心,做为混合系数的估计。采用均匀划分的方式,为每个(a(t,f),δ(t,f))定义一个a-δ平面。
步骤2.1将a-δ平面离散化为以δa和δδ为步长的小矩形,离散化后的a和δ分别记为(a0,…,ak)和(δ0,…,δl),k,l是分段的个数,并且有
步骤2.2对a-δ平面上的每一个网格(ak,δl)(其中k∈1,...,k,l∈1,...,l),定义m(ak,δl),并用零进行初始化。对于每一个时频点的(a(t,f),δ(t,f)),用下面的规则对m(ak,δl)进行更新:
m(ak,δl)=m(ak,δl)+1
if|a(t,f)-ak|<δaand|δ(t,f)-δl|<δδ
其中l=0,1,…,l。m(ak,δl)的值就是网格(ak,δl)中包含数据点(a(t,f),δ(t,f))的个数,即数据点的密度。
步骤3.源信号的恢复。将由步骤2得到的混合系数的估计记为:
混合信号的时频域表示可以记为:
将混合矩阵写成列向量的形式:
其中
步骤3.1根据假设条件,如果在每个时频点上,最多只有m个源信号不等于零,矩阵
如果用φ(f)得到的源信号
可以满足
步骤3.2为每一个网格定义一个数组:
本发明解决了源信号不充分稀疏情况下的欠定盲分离问题,密度和网格聚类的应用有效提高了计算效率,在盲信号处理,稀疏分量分析领域有着十分重要的意义。
- 还没有人留言评论。精彩留言会获得点赞!