一种基于多尺度特征融合深度学习的裂缝自动化勾画方法与流程
本发明涉及结构检测与评估领域,特别是涉及一种利用图像、视屏等对结构表面裂缝自动化检测的方法。
背景技术:
结构裂缝是土木工程领域最常见的病害之一,对结构的耐久性和安全性产生极大的危害,因此裂缝是各类型结构健康状况的主要评价指标之一。而现阶段裂缝检测仍然以人工检测为主,需要人工的进行标记将裂缝勾画出来,而后再进行长度、宽度、裂缝类型等方面的分析。这种检测方法需要借助手脚架等设备,劳动强度大、安全性低、检测效率低。
基于数字图像处理的裂缝检测技术虽然逐渐的被应用到结构裂缝检测中,但是传统的基于图像处理的裂缝自动勾画方法比如边缘检测、阈值分割、简单神经网络等适用性差,检测效果很大程度上依赖于人工干预,对于工程中复杂图像中的大量污渍、人工标记干扰等的抗干扰能力很差。
近几年来,随着深度学习在图像识别领域取得的惊人的成功,深度学习技术也开始逐渐被应用到了裂缝检测中。在国外,chen,zhiqiang等人将深度学习应用到基于图像处理的裂缝识别中,利用fasterrcnn自动的检测出图像中不同尺度的裂缝。在国内,李惠等人利用深度受限玻尔兹曼机实现钢结构疲劳裂纹的自动化检测。在国内,公开号为cn106910186a的专利文献,公开了一种基于cnn深度学习的桥梁裂缝检测定位方法,其缺点是采用的cnn模板只有16像素大小,难以满足图像中不同宽度裂缝的检测,并且没有能够输出精确到像素的裂缝二值化图像。公开号为cn107133960a的专利文献,公开了一种基于全卷积神经网络(fullyconvolutionalnetworks,fcn)的图像裂缝分割方法,其缺点是对于裂缝的细节不敏感,并且没有充分考虑像素与像素之间的关系,忽略了在通常基于像素分类的分割方法中使用的空间规整步骤。
总的来说,裂缝状况是各类型结构健康状态评估的主要指标之一,人工勾画裂缝费时费力,传统的基于数字图像处理的裂缝检测技术适用性差、难以在复杂的工程环境中应用,基于深度学习的裂缝检测已经取得了一定的成果,但距离实际工程应用仍然有很大的提升空间。
技术实现要素:
针对现有技术存在的不足,本发明拟公开一种基于多尺度特征融合深度学习的裂缝自动化勾画方法,能够实现完全依靠深度学习本身的裂缝检测定位、并完成高精度的自动勾画。
本发明思路为:
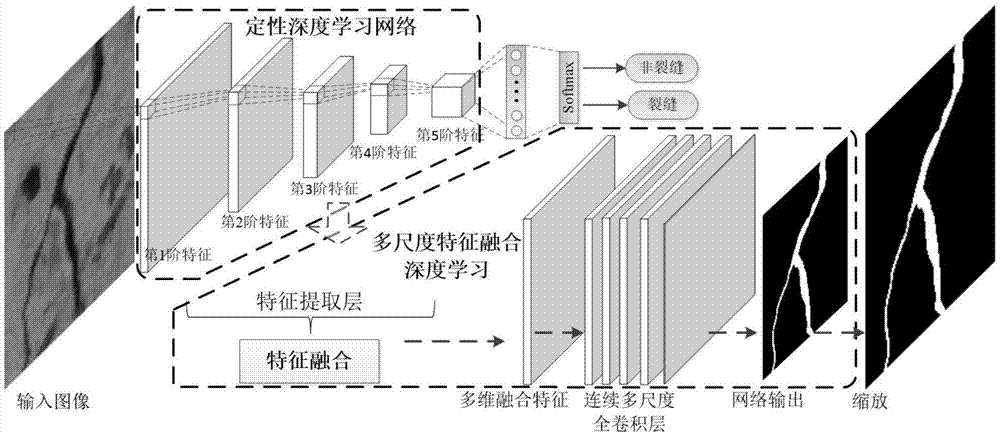
本发明基于特征金字塔网络(featurepyramidnetworks,fpn)和迁徙学习策略,提供一种实现图像中裂缝定位、分割的深度学习网络,能够自动的识别出图像中的裂缝,并融合深度学习网络各层学习到的不同尺度、维度的特征,利用后续多层的全卷积层实现精确到每个像素的裂缝预测。
为解决上述技术问题,本发明采用如下的技术方案:
基于多尺度特征融合深度学习的裂缝自动化勾画方法,包括:
(1)基于迁徙学习的裂缝定性检测及特征提取方法
利用相机采集不同结构表面裂缝图像,构建裂缝图像的数据库。在图像识别领域,已有大量经过1000类分类图像数据库(imagenet数据库)的各类型预训练深度学习模型,比如googlenet、vgg-16、resnet101等,这些深度学习模型对于图像分类的能力已经超过人类。替换已保存图像分类信息的预训练模型的最后一层,即将分类输出数量替换为2(裂缝、非裂缝)。利用构建的裂缝图像数据库,结合预训练模型输入图像的大小,通过图像裁剪、旋转、缩放等操作搭建裂缝图像训练集和测试集,数据库中包含裂缝图像和非裂缝图像两种类型,裂缝图像标记为1,非裂缝图像标记为0。预训练的模型参数中已经包含了图像定性分类的先验知识,利用搭建的裂缝图像数据库进行迁移学习,训练模型直到网络收敛,最终得到高质量的裂缝图像定性分类检测模型。
在训练好的深度学习模型定性检测裂缝图像时,利用深度学习网络各层的输出来提取输入裂缝图像在各个尺度下的不同维度的特征,完成输入图像的特征提取。由于深度学习网络的层数很多,所以不需要提取所有层的输出作为图像不同尺度的特征,深度学习网络各层输出特征图尺寸往往从大到小,对于输出特征图尺寸相同的层,只取输出这一尺寸大小特征图网络的最后一层作为特征提取层,这样就可以得到特征图尺度等比减少的各个尺度的裂缝特征图。以googlenet为例,输入图像大小为224×224像素,那么依次提取的特征图大小为:64个112×112大小的第一阶特征图、192个56×56大小的第二阶特征图、480个28×28大小的第三阶特征图、832个14×14大小的第四阶特征图、1024个7×7大小的第五阶特征图。
(2)多尺度深度学习特征融合方法
在已有训练好深度学习模型提取多个尺度裂缝特征图像基础上,将各个尺度的特征进行逐层融合,最终得到多维的裂缝特征图。其中,高阶特征图像尺寸小但是维数大,低阶特征尺寸大但是维度小,融合不同尺度的特征必要在尺度和维度上都能够统一,具体方法为:
①融合多个尺度特征时候,采用相邻两阶特征逐层融合的方式,先融合较高阶两个尺度的特征为一个尺度的特征,在用融合后的高阶特征图像融合较低阶的特征图像;
②在融合相邻两阶特征图像的时候,先要在维度上将两阶特征统一,利用卷积核大小为1×1的卷积层实现高阶特征的降维,使高阶特征的维度降低到与低阶特征的维度一样。以googlenet的第4、5阶特征融合为例,第4阶特征为832个14×14大小的第四阶特征图,第五阶为1024个7×7大小的第五阶特征图,在第5阶特征图后接卷积核1×1大小的卷积层,控制输出维度为832个,这样第五阶特征图就降维到832个7×7大小的特征图;
③在高阶特征降维实现维度的统一后,还要实现特征图像尺度上的统一。将降维后的高阶特征图像,利用双线性插值,放大到与低阶特征图像一样的大小。同样以googlenet的第4、5阶特征融合为例,第5阶特征降维到832个后,用双线性插值的方式,将7×7大小的特征图缩放到14×14大小,第5阶特征就变为832个14×14大小的特征图;
④在相邻两阶特征图像的维度和尺寸都统一时,采用对应维度对应像素逐个像素像素值累加的方式,实现两个尺度特征的融合。以googlenet的第4、5阶特征融合为例,在第5阶特征的维度、尺寸与第4阶特征统一时,在832个维度上分别于第4阶特征进行逐个像素像素值的累加,融合得到832个14×14大小的特征图。
⑤将选择的多阶特征融合后,可以通过卷积核1×1大小的卷积层来达到最终融合特征维度上的升维或者降维,以适应计算机的运行能力。
依次类推,采用两两逐层融合的方式完多阶特征的融合。本发明专利也包含低阶特征通过1×1大小的卷积层达到升维的效果,从而与高阶特征融合的方式。
(3)连续多尺度全卷积层裂缝预测方法
在得到多阶不同尺度特征融合特征后,利用后续的多尺度连续全卷积层实现像素级别的裂缝预测,具体方法为:
①用卷积层、非线性激活层、批标准化层搭建4层连续的多尺度全卷积层,其中不包含池化层。
②其中,第一层全卷积层的卷积核大小为小的尺度,用于每个像素点在不同维度上信息线性组合,比如1×1大小的卷积核或者3×3大小的卷积核,紧跟批标准化层和非线性激活层,第一层全卷积层保持输出的维度不变;第二层全卷积层的卷积核大小为大的尺度,用于每个像素点及其周围大范围区域像素信息的整合,比如21×21大小等,紧跟批标准化层和非线性激活层,第二层全卷积层保持输出的维度不变。第三层全卷积层与第一层全卷积层构造相同;第四层全卷积层采用卷积核大小为1×1,输出维度降维到1维,其后通过sigmoid函数得到每个像素对应的最终预测值。
③上一步骤得到的并不是裂缝的二值化图像,网络直接预测得到的图像需要经过一次双线性插值缩放,缩放到与输入图像一样的大小。利用阈值0.5对缩放后的图像进行判别,像素值大于0.5的即为裂缝像素,像素值小于0.5的即为背景像素。
(4)所述的多尺度特征融合深度学习采用如下方法进行样本训练,具体为:
①首先利用迁徙学习策略,结合构建的裂缝数据库,训练好裂缝定性识别的网络,能够利用深度学习各层来提取不同尺度的裂缝特征;
②在裂缝定性识别的训练集和测试集中,抽取部分裂缝图像并进行人工勾画(裂缝像素值为1,背景像素值为0),搭建多尺度特征融合深度学习网络的训练集和测试集。其中,训练集和测试集的标签尺度跟随搭建网络最终输出尺寸改变,采用双线性插值的方式改变训练集和测试集标签的大小,并用0.3为阈值将标签二值化;
③设置训练网络的损失函数为交叉熵代价函数(cross-entropycostfuntion),其表达式为:
其中,y为对应像素的标签(0或1),a为网络的实际输出。
④利用迁徙学习,将裂缝定性识别深度学习网络的特征提取层权重赋给裂缝自动勾画的多尺度特征融合深度学习网络,采用随机梯度下降算法不断更新网络的权重,减少损失函数的值,使得网络逐渐收敛。
(5)裂缝检测定位及裂缝自动勾画
网络训练完成后,实现裂缝的自动勾画分为两个步骤:
①裂缝定性深度学习网络实现裂缝定位检测,对于图像尺寸大于深度学习检测模型输入的情况,利用滑动窗口扫描的检测方式扫描检测图像,每个扫描检测的窗口在图像中x、y依次方向错开1/2个输入图像大小,根据每个窗口检测图像的分类实现裂缝的大致定位。
②在上一步裂缝定位的基础上,将每个检测到裂缝窗口的图像裁剪出来,作为裂缝自动勾画的多尺度特征融合深度学习网络的输入,从而输出每个窗口内的裂缝自动勾画。最终完成整个图像内裂缝的自动化勾画。
相对于现有技术,本发明的有益效果如下:本发明开发设备能够广泛应用于结构表面裂缝检测,仅用数秒时间即可完成高精度的裂缝自动勾画:
(1)该技术方案能够实现结构表面裂缝的快速自动化精准勾画,与传统方法相比:本发明提出算法不需要人工干涉的调整阈值分割等系数,完全依赖网络本身去识别裂缝,使用范围广,自动化程度高;
(2)利用深度学习提取各个尺度的裂缝特征,充分考虑了不同尺度特征对应像素之间的关系以及区域范围内各像素之间的关系,可快速实现高精度的裂缝区域分割。
(3)该技术能够适用于各种类型的结构表面裂缝检测,在不同的复杂环境下能够有效的剔除噪声干扰,仅需要数秒时间就能完成一幅图像中裂缝的高精度自动化检测,能够搭载到无人机或者手持式的检测平台上,满足实时采集图像实时分析的需求。
附图说明
图1是本发明中所述的基于多尺度特征融合深度学习的裂缝自动勾画方法示意图;
图2是本发明所述具体实施方式中的googlenet网络示意图;
图3是本发明所述具体实施方式中的融合googlenet网络提取的第3、4、5阶特征示意图;
图4是本发明所述具体实施方式中的连续多尺度全卷积层示意图;
图5是本发明所述实例中的不同复杂环境背景下裂缝检测对比分析图。
具体实施方式
为了使本发明的目的、内容和优点更加浅显易懂,下面具体介绍本发明的实施方式,但不应以此限制本发明的保护范围。
实施例:一种基于多尺度特征融合深度学习的裂缝自动化勾画方法,所述方法包括以下步骤:
(1)基于迁徙学习的裂缝定性检测及特征提取方法,
(2)多尺度深度学习特征融合方法,
(3)连续多尺度全卷积层裂缝预测方法,
(4)所述的多尺度特征融合深度学习采用如下方法进行样本训练,
(5)裂缝检测定位及裂缝自动勾画。
具体如下:步骤一、采用的输入为224*224*3像素的深度学习模型为公开的googlenet模型,原网络的输出层为1000类,修改网络的输出层为2类即分为裂缝和非裂缝两种,如图2所示。构建的224*224*3图像裂缝训练集,包含裂缝图像6.4万张和非裂缝图像6.4张,构建图像测试集,包含1.6万张裂缝图像和1.6万张非裂缝图像。利用迁徙学习的策略,将开源的1000类分类预训练模型的权重赋值给修改分类数为2类的模型,采用随机梯度下降算法更新网络的权重,直到网络收敛。网络训练好之后,网络各层输出的特征图像尺寸有以下5种:112×112、56×56、28×28、14×14、7×7。取输出每种尺寸特征图像的最高阶一层作为该尺寸特征的输出层,最终得到:64维度的112×112大小第一阶特征、192维度的56×56大小第二阶特征、480维度28×28大小第三阶特征、832维度14×14大小第四阶特征、1024维度7×7大小第五阶特征。
步骤二、以融合第3、4、5阶特征图像为例,如图3所示。第五阶特征图为7×7×1024大小,先通过卷积核为1×1大小的卷积层将特征图转化为7×7×832大小,在利用双线性插值将特征图转化为14×14×832大小;将转化后的第5阶特征和第4阶特征进行融合,在对应的维度上进行逐个像素的累加,得到融合后的第4阶特征图14×14×832大小;同样,利用卷积核为1×1大小的卷积层和双线性插值层将融合后的第4阶特征图转化为28×28×480大小,再与第3阶特征进行对应维度上逐个像素的累加,得到融合后的第3阶特征图28×28×480大小;而后为了减少计算机训练的负担,进一步对数据进行降维,利用卷积核为1×1大小的卷积层将融合的第三阶特征图降维到28×28×192大小,并通过两次双线性插值将特征图放大到112×112×192大小,完成第3、4、5阶特征的融合。
步骤三、搭建多尺度的全卷积层,达到预测每个像素的目的,如图4所示。步骤二中最终得到的融合特征大小为112×112×192大小,后接第一层小尺度全卷积层的卷积核大小为1×1大小,其后跟随批标准化层和非线性激活层,这一层输出的维度为192维,输出尺寸不变;后接第二层大尺度全卷积层的卷积核大小为21×21大小,其后跟随批标准化层和非线性激活层,这一层输出的维度为112×112×192大小;后接第三层小尺度全卷积层的卷积核大小为1×1大小,其后跟随批标准化层和非线性激活层,这一层输出的维度为192维,输出尺寸不变;后接第四层全卷积层,也就是最后一层全卷积层,卷积核大小为1×1,输出的维度为1,也就是这一层输出尺寸为112×112×1大小;最后一层紧接着sigmoid函数层,实现逐个像素的裂缝预测。
步骤四、搭建多尺度特征融合深度学习网络的训练集和测试集,训练网络。抽取步骤一中搭建的深度学习定性识别网络裂缝训练集和测试集中的裂缝图像,人工勾画裂缝制作裂缝的标签文件(裂缝像素为1,非裂缝像素为0)。因为设置网络的输出尺寸为112×112大小,所以讲人工勾画的裂缝标签双线性插值到112×112大小,并以0.3作为阈值得到二值化的标签。设置训练网络的损失函数为交叉熵代价函数,利用迁徙学习策略,将裂缝定性识别深度学习网络的特征提取层权重赋给裂缝自动勾画的多尺度特征融合深度学习网络,采用随机梯度下降算法不断更新网络的权重,减少损失函数的值,使得网络逐渐收敛。
步骤五、在训练好两个网络后,对于一张输入为4000×6000像素的裂缝图像,首先用裂缝定性深度学习网络实现裂缝定位检测,利用滑动窗口扫描的检测方式扫描检测图像,每个扫描检测的窗口在图像中x、y依次方向错开112个像素,根据每个窗口检测图像的分类实现裂缝的大致定位;将每个检测到裂缝窗口的224×224(3通道)大小图像裁剪出来,作为裂缝自动勾画的多尺度特征融合深度学习网络的输入,每个窗口直接预测的图像大小为112×112像素,双线性插值到224×224大小,并以0.5为阈值进行分割,从而输出每个窗口内的裂缝自动勾画(二值化图像),最终完成整个图像内裂缝的自动化勾画。
应用实施例:
下面通过具体实施例对本发明作进一步说明,但不应以此限制本发明的保护范围。
在不同的结构表面及不同环境背景下采集不同复杂程度的裂缝图像,用本发明实现裂缝的自动化检测并进行精度分析。
(1)深度学习扫描检测
用训练好的224*224*3输入的googlenet深度学习模型扫描检测图像,部分输出结果如图5第一列所示。
(2)用多尺度特征融合深度学习网络实现裂缝的自动勾画
将每个检测到裂缝窗口的224×224(3通道)大小图像裁剪出来,作为裂缝自动勾画的多尺度特征融合深度学习网络的输入,从而输出每个窗口内的裂缝自动勾画,经过双线性插值和阈值分割,实现每个窗口内裂缝图像的二值化,最终完成整个图像内裂缝的自动化勾画,部分输出结果如图5第二列所示。
(3)与传统方法对比
在第一步中每个检测到裂缝的窗口内,采用自适应阈值分割和canny算子检测的结果进行视觉上直观的对比,部分输出结果如图5第三列和第四列所示。
(4)精度分析
采用人工勾画裂缝二值化图像与发明所提出方法输出裂缝二值化图像结果对比。将图像划分为等间距的7*7像素的方格,一共有857*571(取整)个方格。对比每个方格内手动勾画与自动勾画裂缝的情况来统计检测的精度。
tp(truepositive):手动勾画和自动勾画裂缝都有裂缝的方格数量;
tn(truenegative):统计手动勾画、自动勾画裂缝都没有裂缝的方格数量;
fp(falsepositive):统计手动勾画没有裂缝、自动勾画裂缝有裂缝的方格数量;
fn(falsenegative):统计手动勾画有裂缝、自动勾画裂缝没有裂缝的方格数量;
设置三个指标:
精确率(precision)=tp/(tp+fp)、召回率(recall)=tp/(tp+fn),f-measure=2×精确率×召回率/(精确率+召回率).
本发明提出方法在不同复杂环境中均能保持高准确率、高精确率、高召回率。
- 还没有人留言评论。精彩留言会获得点赞!