广告编入装置和广告编入方法与流程
本发明的实施例涉及一种在视频内容内编入广告的技术。
背景技术
目前不断地提出关于在通过iptv、互联网、智能电话等互联网和移动环境再现的视频内容中有效地展示广告的方法。
在与此相关的现有技术中,广告编程者在根据主观的判断基准而视觉感知的编入时间点一味地编入与实际再现的视频内容在内容上没有相关性的广告,从而提供对观众没有针对性的广告。
这种现有技术对广告编入时间点的判断较为主观,并且影像的长度越长,广告编程者的疲劳度也会增加,并且由于与视频内容所涵盖的内容无关的广告的单方面地展示,可能会带来观众的反感。因此,观众中断视频内容的观看或者跳过广告内容的概率变高,结果会带来广告效果的降低。
[现有技术文献]
[专利文献]
韩国公开专利第10-2010-0095924号(2010.09.01.公开)
技术实现要素:
本发明的实施例用于提供广告编入装置及方法。
根据本发明的一实施例的广告编入装置包括:场景理解信息分析部,生成包含针对视频内容的各个帧图像的关键词的场景理解信息;场景理解信息匹配部,以场景为单位分割所述视频内容,并将所述场景理解信息与所述分割的各个场景进行匹配;以及,广告编入部,基于与所述分割的各个场景匹配的场景理解信息来确定将要插入到所述视频内容中的广告内容。
所述广告编入装置还可以包括:场景转换分析部,在所述视频内容中确定至少一个场景转换时间点,所述场景理解信息匹配部基于所述场景转换时间点,以场景为单位分割所述视频内容。
所述广告编入装置还可以包括:关键词扩展部,生成包括与所述视频内容相关的话题关键词和新词关键词中的至少一个的扩展关键词信息,并将其与所述分割的各个场景进行匹配;以及,分析信息存储部,存储所述场景转换时间点、与所述分割的所述场景匹配的场景理解信息以及扩展关键词信息。
所述场景理解信息分析部可以包括:场景理解信息关键词生成部,按所述各个帧图像来生成与各个帧图像所包含的字幕、事物、人物和空间中的至少一个相关的场景理解关键词;以及,相关关键词生成部,基于词汇词典来生成相关关键词,所述相关关键词包括与所述场景理解关键词所属的类别相关的关键词、所述场景理解关键词的关联词以及所述场景理解关键词的近义词中的至少一个,所述场景理解信息包括所述场景理解关键词和所述相关关键词。
所述场景理解信息分析部还可以包括:文章生成部,利用所述场景理解关键词和所述相关关键词中的至少一个来生成与所述各个帧图像相关的文章,并且所述场景理解信息还可以包括所述生成的文章。
所述关键词扩展部可以包括:扩展关键词本体数据库,存储基于与所述视频内容相关的话题关键词和从新词词典收集的新词关键词来生成的扩展关键词本体;以及,扩展关键词匹配部,从所述扩展关键词本体提取与分割的各个所述场景匹配的场景理解信息所相关的扩展关键词信息,并使提取到的扩展关键词信息与分割的各个所述场景匹配。
关键词扩展部还可以包括:话题关键词收集部,爬取(crawling)与所述视频内容相关的网页而收集与所述视频内容相关的话题关键词;以及,新词关键词收集部,从新词词典收集新词关键词,其中,所述扩展关键词本体利用收集到的所述话题关键词和新词关键词来生成。
所述广告编入部可以包括:广告信息存储部,存储与一个以上的广告内容分别相关的广告关键词信息;以及,广告内容确定部,将与所述场景转换时间点之前或之后的场景匹配的场景理解信息和扩展关键词信息与所述广告关键词信息进行比较,从而确定将要插入到所述场景转换时间点的广告内容。
所述场景转换分析部基于包含在所述视频内容的各个帧图像中的噪声、边缘(edge)、颜色、字幕和脸部中的至少一个来确定所述场景转换时间点。
所述场景转换分析部可以包括:音频分析部,基于所述视频内容的音频信号大小变化来提取一个以上的分析对象区间;图像分析部,基于包含在各个所述分析对象区间内的帧图像中的噪声、边缘、颜色、字幕和脸部中的至少一个来确定所述场景转换时间点。
根据本发明的一实施例的广告编入方法包括如下的步骤:生成包含针对视频内容的帧图像各自的关键词的场景理解信息;以场景为单位分割所述视频内容,并将所述场景理解信息与所述分割的各个场景进行匹配;以及,基于与分割的各个场景匹配的所述场景理解信息来确定将要插入到所述视频内容中的广告内容。
所述的广告编入方法还可以包括如下的步骤:在所述视频内容中确定至少一个场景转换时间点,并且进行匹配的步骤包括如下的步骤:基于所述场景转换时间点,以场景为单位分割所述视频内容。
所述广告编入方法还可以包括如下的步骤:生成包括与所述视频内容相关的话题关键词和新词关键词中的至少一个的扩展关键词信息,并将其与所述分割的各个场景进行匹配。
生成所述场景理解信息的步骤可以包括如下的步骤:按各个所述帧图像来生成与各个帧图像所包含的字幕、事物、人物和空间中的至少一个相关的场景理解关键词;以及,基于词汇词典来生成相关关键词,所述相关关键词包括与所述场景理解关键词所属的类别相关的关键词、所述场景理解关键词的关联词以及所述场景理解关键词的近义词中的至少一个,所述场景理解信息包括所述情况关键词和所述相关关键词。
生成所述场景理解信息的步骤可以包括如下的步骤:利用所述场景理解关键词和所述相关关键词中的至少一个来生成与所述各个帧图像相关的文章,所述场景理解信息还可以包括生成的所述文章。
生成所述扩展关键词信息,并将其与所述分割的各个场景进行匹配的步骤可以包括如下的步骤:从扩展关键词本体提取扩展关键词信息,所述扩展关键词本体基于与所述视频内容相关的话题关键词和从新词词典收集的新词关键词来生成,所述扩展关键词信息与所述分割的各个场景匹配的场景理解信息相关;以及,将提取到的所述扩展关键词信息与所述分割的各个场景进行匹配。
生成所述扩展关键词信息,并将其与所述分割的各个场景进行匹配的步骤还可以包括如下的步骤:爬取(crawling)与所述视频内容相关的网页而收集与所述视频内容相关的话题关键词;以及,从新词词典收集新词关键词,所述扩展关键词本体利用收集到的所述话题关键词和新词关键词来生成。
在确定所述广告内容的步骤中,可以将与所述场景转换时间点之前或之后的场景匹配的场景理解信息和扩展关键词信息与分别匹配于至少一个广告内容的广告关键词信息进行比较,从而确定将要插入到所述场景转换时间点的广告内容。
在确定所述场景转换时间点的步骤中,可以基于包含在所述视频内容的各个帧图像中的噪声、边缘(edge)、颜色、字幕和脸部中的至少一个来确定所述场景转换时间点。
确定所述场景转换时间点的步骤可以包括如下的步骤:基于所述视频内容的音频信号大小来提取一个以上的分析对象区间;基于包含在各个所述分析对象区间内的帧图像中的噪声、边缘、颜色、字幕和脸部中的至少一个来确定所述场景转换时间点。
根据本发明的实施例,使与视频内容所涵盖的场景相关性高的广告插入到视频内容内的合适的时间点,从而能够消除视频内容观众对广告的反感,并能够提高广告效果。
附图说明
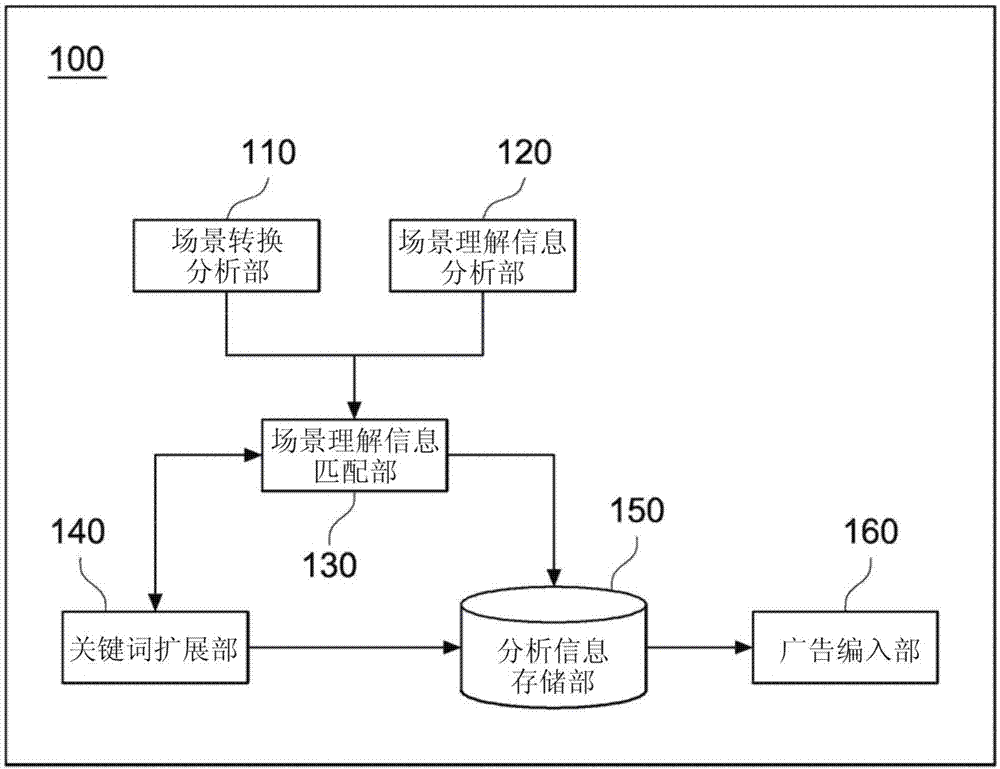
图1是根据本发明的实施例的广告编入装置的构成图。
图2是根据本发明的追加实施例的场景转换分析部110的构成图。
图3是根据本发明的一实施例的场景理解信息分析部120的构成图。
图4是根据本发明的一实施例的关键词扩展部140的构成图。
图5是根据本发明的一实施例的广告编入部160的构成图。
图6是根据本发明的另一实施例的广告编入方法的流程图。
图7是用于示例性地示出适合在示例性实施例中使用的包含计算装置的计算环境的框图。
符号说明
10:计算环境12:计算装置
14:处理器16:计算机可读存储介质
18:通信中线20:程序
22:输入输出接口24:输入输出装置
26:网络通信接口100:广告编入装置
110:场景转换分析部111:音频分析部
112:图像分析部120:场景理解信息分析部
121:场景理解关键词生成部122:关联关键词生成部
123:文章生成部130:场景理解信息匹配部
140:关键词扩展部141:话题关键词收集部
142:新词关键词收集部143:扩展关键词本体数据库
144:扩展关键词匹配部150:分析信息存储部
160:广告编入部161:广告信息存储部
162:广告内容确定部
具体实施方式
以下,参阅附图对本发明的具体实施形态进行说明。为了有助于对本说明书中记载的方法、装置和/或系统的全面理解,提供以下的详细说明。然而,这只是示例,本发明并非局限于此。
在说明本发明的实施例的过程中,如果判断为对与本发明有关的公知技术的具体说明有可能对本发明的要义造成不必要的混乱,则将省略其具体说明。并且,后述的术语作为虑及本发明中的功能而定义的术语,其可能因使用者、运用者的意图或惯例等而不同。因此,要将贯穿整个说明书的内容作为基础而对其进行定义。具体说明中使用的术语仅用于记载本发明的实施例,其绝非限定性术语。除非明确不同地使用,否则单数形态的表述包括复数形态的含义。在说明中,“包括”或“具有”之类的表述用于指代某些特性、数字、步骤、操作、要素及其一部分或者组合,不应解释为将所记载项以外的一个或者其以上的其他特性、数字、步骤、操作、要素及其一部分或组合的存在性或者可存在性予以排除。
图1是根据本发明的实施例的广告编入装置的构成图。
参照图1,根据本发明的一实施例的广告编入装置100包括:场景转换分析部110、场景理解信息分析部120、场景理解信息匹配部130、关键词扩展部140、分析信息存储部150和广告编入部160。
广告编入装置100用于从视频内容内检测场景转换时间点而以场景为单位分割视频内容,并将与分割的各个场景关联性高的广告内容插入到各个场景转换时间点,从而在视频内容内编入中间广告,例如,可以利用一个以上的服务器实现。
另外,视频内容可以是通过iptv、互联网网页、移动应用等以视频点播(vod:videoondemand)形式提供的内容。
场景转换分析部110在视频内容中确定至少一个场景转换时间点。
具体而言,根据本发明的一实施例,场景转换分析部110可以基于包含在视频内容的各个帧图像中的噪声、边缘(edge)、颜色、字幕和脸部中的至少一个来确定场景转换时间点。
例如,场景转换分析部110可以计算针对视频内容的各个帧图像的峰值信噪比(psnr:peaksignaltonoiseratio),并将特定图像帧的psnr为预设定的基准值以下的时间点确定为场景转换时间点。
作为另一例,场景转换分析部110在视频内容的各个帧图像中检测边缘(edge),并将帧图像之间的边缘数量的变化为预设定的基准值以上的时间点确定为场景转换时间点。此时,为了检测边缘,可以利用公知的多样的方式的边缘检测算法。具体而言,场景转换分析部110例如可以在各个帧图像的关心区域中检测边缘之后,将检测出的边缘数量的变化在基准值以上的时间点确定为场景转换时间点。此时,关心区域可以是由用户预先设定的区域。例如,在视频内容为在左侧上端插入有与当前的场景或者情节相关的字幕且在场景或情节改变时对应的位置的字幕也一起改变的综艺节目的情况下,用户可以将左侧上端区域设定为关心区域。在此情况下,如果插入到关心区域的字幕变更,则在字幕变更之前的帧图像和变更之后的帧图像的关心区域中检测出的边缘的数量也会大幅度地改变,因此能够容易地检测场景转换时间点。
作为另一例,场景转换分析部110在视频内容的各个帧图像的关心区域中提取字幕,并将提取到的字幕变化的时间点确定为场景转换时间点。此时,为了提取字幕,例如可以使用光学文字识别(ocr:opticalcharacterrecognition)技术。具体而言,如上所示地,在视频内容为在左侧上端插入有与当前的场景或者情节相关的字幕的综艺节目的情况下,关心区域可以设定为左侧上端区域,并且在从各个帧图像的关心区域提取的字幕之间的类似度为预设定的基准值以上的情况下,场景转换分析部110可以将该时间点确定为场景转换时间点。此时,字幕之间的类似度可以根据莱文斯坦距离(levenshteindistance)来计算。
作为又一例,场景转换分析部110可以生成针对视频内容的各个帧图像的颜色直方图,并将帧图像之间的颜色直方图的变化为预设定的基准值以上的时间点确定为场景转换时间点。具体而言,场景转换分析部110例如可以生成针对各个帧图像的色调-亮度-饱和度(hsl:hue-lightness-saturation)颜色直方图,并将各个帧图像的颜色直方图之间的距离为基准值以上的时间点确定为场景转换时间点。此时,颜色直方图之间的距离例如可以通过巴氏距离(bhattacharyyadistance)而计算。作为具体的例,对与诸如足球比赛等体育影像而言,由于比赛场面占绝大部分,因此帧图像之间的颜色直方图的变化并不大。然而,对得分场景、犯规场景等的回放场景而言,通常在场景转换为回放场景之前显示图形效果。在此情况下,因图形效果,在场景转换时,颜色直方图会大幅度地改变,因此能够容易地检测场景转换时间点。
作为又一例,场景转换分析部110可以识别视频内容的各个帧图像所包含的脸不,并将登场人物变化的时间点确定为场景转换时间点。此时,为了识别脸部,可以利用公知的多样的面部识别算法。
另外,场景转换时间点确定方式并不一定局限于如上所述的方式。即,场景转换分析部110可以根据视频内容的类型而组合如上所述的方式中的一个以上的方式来检测场景转换时间点,并且根据实施例,为了确定场景转换时间点,还可以追加地利用从各个帧图像中检测出的脸部数量的变化、肤色分布变化等。
另外,根据本发明的追加实施例,场景转换分析部110可以基于视频内容的音频信号来确定一个以上的分析对象区间,并分析所确定的各个分析对象区间内的帧图像而确定场景转换时间点。
具体而言,图2是根据本发明的追加实施例的场景转换分析部110的构成图。
参照图2,根据本发明的追加实施例的场景转换分析部110可以包括音频分析部111和图像分析部112。
音频分析部111基于音频信号的大小变化来从视频内容内提取一个以上的分析对象区间。此时,分析对象区间例如可以包括消音区间、峰值区间和效果音区间中的至少一个。
具体而言,根据本发明的实施例,音频分析部111可以将音频信号的大小以预设定的基准值以下持续预设定的时间以上的时间的区间提取为消音区间。例如,音频分析部111可以将音频信号的大小以-20db以下持续1秒以上的区间提取为消音区间。此时,根据实施例,在提取到的消音区间的数量不足预设定的数量(例如,50个)的情况下,可以将基准值逐渐增加至提取到预设定的数量的消音区间为止,此时每次的增加量为1db。
并且,根据本发明的一实施例,音频分析部111可以将音频信号的大小以预设定的基准值以上持续预设定的时间以上的区间提取为峰值区间。例如,音频分析部111可以将音频信号的大小以10db以上持续1秒以上的区间提取为峰值区间。此时,根据实施例,当提取到的峰值区间的数量小于预设定的数量(例如,50个)的情况下,可以将基准值逐渐降低至提取到预设定的数量的消音区间,此时每次的减少量为1db。
并且,根据本发明的实施例,在特定大小的音频信号反复的情况下,音频分析部111可以将具有对应的大小的音频信号的区间提取为效果音区间。例如,音频分析部111可以将从-20db到20db之间的音频大小以1db为单位划分而提取具有各个音频信号的大小的区间,并且在提取到的区间中的具有特定大小的音频信号的区间的数量为预设定的值以上的情况下,可以将具有对应的大小的音频信号的区间提取为效果音区间。
另外,图像分析部112可以对借助音频分析部111提取的各个分析对象区间所包含的帧图像进行分析,从而提取场景转换时间点。此时,场景转换时间点可以如上所述地通过多样的方式而被提取。
即,根据如图2所示的实施例,图像分析部112在各个分析对象区间内提取场景转换时间点,而并非在整个视频内容,因此能够减少用于提取场景转换时间点的运算量和时间。
重新参照图1,场景理解信息分析部120生成针对视频内容的各个帧图像的场景理解信息。此时,场景理解信息可以包括场景理解关键词和针对各个场景理解关键词的相关关键词。
具体而言,图3是根据本发明的一实施例的场景理解信息分析部120的构成图。
参照图3,场景理解信息分析部120可以包括场景理解关键词生成部121、相关关键词生成部122和文章生成部123。
场景理解关键词生成部121可以生成针对视频内容的每一个帧图像的场景理解关键词。此时,场景理解关键词可以包括与包含在各个帧图像中的字幕、事物、人物和空间中的至少一个相关的关键词。
具体而言,根据本发明的一实施例,场景理解关键词生成部121可以利用光学文字识别(ocr:opticalcharacterrecognition)技术而识别包含在各个帧图像中的字幕,并从识别到的字幕中提取关键词。此时,为了提取关键词,例如可以执行针对识别到的字幕的形态分析、命名实体识别(namedentityrecognition)、停用词(stopword)处理等过程。
此外,根据本发明的一实施例,场景理解关键词生成部121可以利用预先生成的一个以上的关键词生成模型而生成与各个帧图像相关的场景理解关键词。此时,各个关键词生成模型例如可以通过将预先收集的图像和与各个图像相关的关键词作为学习数据而利用的机械学习来生成。例如,关键词生成模型可以将预先收集的演员的图像和与各个演员相关的关键词(例如,姓名、角色、性别等)作为学习数据利用而生成,或者可以将预先收集的多样的空间(例如,机场、飞机、火车、医院等)或事物的图像和与各个空间相关的关键词作为学习数据而生成。
相关关键词生成部122基于预建的词汇词典来生成针对场景理解关键词生成部121所生成的各个场景理解关键词的一个以上的相关关键词。此时,相关关键词可以包括表示场景理解关键词所属的类别的关键词、针对场景理解关键词的关联词和近义词。
文章生成部123利用针对各个帧图像生成的场景理解关键词和相关关键词来生成与各个帧图像相关的文章。具体而言,文章生成部123可以以词汇词典为基础,基于各个场景理解关键词和相关关键词所具有的含义来生成与各个帧图像相关的文章。此时,为了生成文章,可以利用公知的多样的形态的文章生成算法。
再次参照图1,场景理解信息匹配部130基于由场景转换分析部110确定的场景转换时间点来将视频内容以场景为单位进行分割,并将由场景理解信息分析部120生成的场景理解信息与分割的各个场景进行匹配。
具体而言,场景理解信息匹配部130可以将关于属于以场景转换时间点为基准而分割的各个场景的区间内的帧图像的场景理解信息匹配为针对各个场景的场景理解信息。
关键词扩展部140生成扩展关键词信息,所述扩展关键词信息包括与基于场景转换时间点来分割的各个场景相关的话题关键词和新词关键词中的至少一个。
根据本发明的实施例,关键词扩展部140可以基于从与视频内容相关的网页收集的话题关键词和从新词词典收集的新词关键词来生成与视频内容的各个场景相关的扩展关键词。
具体地,图4是根据本发明的一实施例的关键词扩展部140的构成图。
参照图4,关键词扩展部140包括话题关键词收集部141、新词关键词收集部142、扩展关键词本体数据库(ontologydatabase)143以及扩展关键词匹配部144。
话题关键词收集部141爬取(crawling)与视频内容相关的网页而提取话题关键词。此时,网页例如可以包括社交媒体(socialmedia)帖子、新闻文章等。具体而言,话题关键词收集部141例如可以基于视频内容的标题、播放期数信息来爬取与视频内容相关的网页,之后从爬取的网页提取话题关键词。此时,话题关键词收集部141例如可以根据在爬取的网页内的出现频率较高的文本、包含在网页标题中的文本等由用户预先设定的多样的规则提取问题关键词。
新词关键词收集部142从新词词典中收集新词关键词。此时,新词词典例如可以利用从韩国国立国语研究院等外部提供的数据库。
扩展关键词本体数据库143存储利用从话题关键词收集部141收集的话题关键词、从新词关键词收集部142收集的新词关键词来生成的扩展关键词本体。具体而言,扩展关键词本体例如可以基于从话题关键词收集部141收集的话题关键词、从新词关键词收集部142收集的新词关键词、由词汇词典提供的关键词之间的含义的关系来生成。
扩展关键词匹配部144可以从扩展关键词本体数据库143提取与匹配于各个场景的场景理解信息相关的话题关键词和新词关键词作为扩展关键词,并将提取到的扩展关键词匹配到分割的各个场景。
另外,再次参照图1,分析信息存储部150存储场景转换时间点和与因各个场景转换时间点而分割的各个场景匹配的场景理解信息以及扩展关键词信息。
广告编入部160基于存储于分析信息存储部150的场景转换时间点、关于分割的各个场景的场景理解信息以及扩展关键词信息来确定将在各个场景转换时间点插入的广告内容。
具体而言,图5是根据本发明的一实施例的广告编入部160的构成图。
参照图5,根据本发明的一实施例的广告编入部160包括广告信息存储部161和广告内容确定部162。
广告信息存储部161存储与一个以上的广告内容分别相关的广告关键词信息。此时,广告关键词信息可以包括与各个广告内容相关的关键词。例如,广告关键词可以包括产品名称、产品种类、销售公司、广告模型等与广告内容相关的多样的关键词,并且广告关键词信息例如可以预先由广告主提供。
广告内容确定部162将存储于分析信息存储部150中的与以各个场景转换时间点为基准而在场景转换时间点之前或者在场景转换时间点之后的场景匹配的场景理解信息和扩展关键词信息与相关于各个广告内容的广告关键词信息进行比较,从而将相关性高的广告内容确定为将插入到各个场景转换时间点的广告内容。例如,广告内容确定部162可以将与场景转换时间点之前或者之后的场景相关的场景理解信息与扩展关键词信息和与各个广告内容相关的广告关键词信息进行比较,从而将关键词一致性高的广告内容确定为将要插入到各个场景转换时间点的广告内容。
另外,在一实施例中,图1图示的场景转换分析部110、场景理解信息分析部120、场景理解信息匹配部130、关键词扩展部140、分析信息存储部150以及广告编入部160可以在包括一个以上的处理器以及与该处理器连接的计算机可读记录介质的一个以上的计算装置上实现。计算机可读记录介质可以位于处理器的内部或者外部,并且可以通过公知的多种手段连接到处理器。计算装置内的处理器可以使各个计算装置按本说明书中记载的示例性的实施例运行。例如,处理器可以执行计算机可读记录介质中储存的指令,计算机可读记录介质中储存的指令在由处理器执行时,可以使计算装置执行根据本说明书中记载的示例性的实施例的操作。
图6是根据本发明的另一实施例的广告编入方法的流程图。
图示于图6的方法例如可以利用图示于图1的广告编入装置100执行。
参照图6,首先,广告编入装置100在视频内容中确定至少一个场景转换时间点(610)。
此时,根据本发明的实施例,广告编入装置100可以基于视频内容的各个帧图像所包含的噪声、边缘(edge)、颜色、字幕以及脸部中的至少一个来确定所述场景转换时间点。
并且,根据本发明的实施例,广告编入装置100可以基于视频内容的音频信号大小的变化来提取一个以上的分析对象区间,并基于包含在所提取的各个分析对象区间内的帧图像中的噪声、边缘、颜色、字幕和脸部中的至少一个来确定场景转换时间点。
之后,广告编入装置100生成针对视频内容的各个帧图像的包括场景理解关键词以及针对场景理解关键词的相关关键词的场景理解信息(620)。
此时,根据本发明的一实施例,场景理解关键词可以包括与包含在各个帧图像的字幕、事物、人物和空间中的至少一个相关的关键词。
并且,根据本发明的一实施例,相关关键词可以包括与场景理解关键词所属的类别相关的关键词、所述场景理解关键词的关联词以及所述场景理解关键词的近义词中的至少一个,且相关关键词可以基于词汇词典来生成。
并且,根据本发明的一实施例,广告编入装置100可以利用与各个帧图像对应的场景理解关键词以及相关关键词中的至少一个来生成与各个帧图像分别相关的文章,在此情况下,针对各个帧图像的场景理解信息还可以包括所生成的文章。
之后,广告编入装置100基于场景转换时间点来以场景为单位分割视频内容,并将针对各个帧图像生成的场景理解信息与分割的各个场景进行匹配(630)。
之后,广告编入装置100生成包括与分割的各个场景相关的话题关键词以及新词关键词中的至少一个的扩展关键词信息,从而将所生成的扩展关键词信息与分割的各个场景进行匹配(640)。
此时,根据本发明的一实施例,广告编入装置100可以基于与视频内容相关的话题关键词、从新词词典收集的新词关键词来从所生成的扩展关键词本体中提取与匹配于分割的各个场景的场景理解信息相关的扩展关键词信息。
之后,广告编入装置100基于场景转换时间点、与分割的各个场景匹配的场景理解信息以及扩展关键词信息来确定将要插入到各个场景转换时间点的广告内容(650)。
具体而言,根据本发明的一实施例,广告编入装置100可以将与场景转换时间点之前或者之后的场景相关的场景理解信息与扩展关键词信息和与各个广告内容相关的广告关键词信息进行比较,从而确定将要插入到各个场景转换时间点的广告内容。
另外,在如图6所图示的流程图中将所述方法分成了多个步骤而进行了记载,然而还可以由如下的方式来执行:交换至少一部分步骤而执行;与其他步骤结合而一起执行;省略或分为细分化的步骤而执行;或者附加未图示的一个以上的步骤而执行。
图7是用于示例性地示出包含适合在示例性实施例中使用的计算装置的计算环境的框图。在图示的实施例中,各个组件除了以下记载的功能以及能力以外还可具有其他不同的的功能以及能力,并且除了以下记载的组件以外还可以包括额外的组件。
图示的计算环境包括计算装置12。在一实施例中,计算装置12例如可以包括图示于图1的场景转换分析部110、场景理解信息分析部120、场景理解信息匹配部130、关键词扩展部140、分析信息存储部150以及广告编入部160等包含在广告编入装置100中的一个以上的组件。
计算装置12包括至少一个处理器14、计算机可读存储介质16以及通信总线18。处理器14可以使计算装置12根据前面提及的示例性的实施例来操作。例如,处理器14可以运行存储于计算机可读存储介质16中的一个以上的程序。所述一个以上的程序可以包括一个以上的计算机可执行指令,并且所述计算机可执行指令可以构成为,在通过处理器14执行的情况下使计算装置12执行根据示例性的实施例的操作。
计算机可读存储介质16以能够存储计算机可执行的指令至程序代码、程序数据以及/或者其他适合的形式的信息的方式构成。存储于计算机可读存储介质16中的程序20包含可由处理器14执行的指令集。在一实施例中,计算机可读存储介质16可以是存储器(随机存取存储器等易失性存储器、非易失性存储器或者这些存储器的适合的组合形式)、一个以上的磁盘存储设备、光盘存储设备、闪速存储设备、除此之外的可由计算装置12访问并能够存储所期望的信息的其他形式的存储介质或者这些的适合的组合形式。
通信总线18用于将处理器14、计算机可读存储介质16以及计算装置12的其他多样的组件相互连接。
此外,计算装置12还可以包含提供用于一个以上的输入输出装置24的接口的一个以上的输入输出接口22以及一个以上的网络通信接口26。输入输出接口22以及网络通信接口26连接到通信总线18。输入输出装置24可以通过输入输出接口22而连接到计算装置12的其他组件。示例性的输入输出装置24可以包括:诸如指示装置(鼠标或者触控板(trackpad)等)、键盘、触摸输入装置(触摸板或者触摸屏等)、语音或者声音输入装置、多样的种类的传感器装置以及/或者拍摄装置等的输入装置;以及/或者诸如显示装置、印刷机、扬声器以及/或者网卡(networkcard)等的输出装置。示例性的输入输出装置24可以作为用于构成计算装置12的一组件而包含在计算装置12的内部,也可以作为区别于计算装置12的独立的装置而连接到计算装置102。
以上,对本发明的具有代表性的实施例进行了详细的说明,然而在本发明所属的技术领域中具有基本知识的人员可以理解上述的实施例可在不脱离本发明的范围的限度内实现多种变形。因此,本发明的权利范围不应局限于上述的实施例,本发明的权利范围需要根据权利要求书的范围以及与该权利要求书均等的范围来确定。
- 还没有人留言评论。精彩留言会获得点赞!