一种基于轨迹字典的时空轨迹压缩方法与流程
本发明设计数据库、时空数据管理、数据分析、数据挖掘、轨迹数据分析、轨迹数据挖掘领域,特别是涉及一种基于轨迹字典集的时空轨迹压缩方法。
背景技术
由于gps移动定位设备和无线通讯技术(如、wi-fi、3g等)的广泛普及,导致移动对象的轨迹数据量以指数型增长,这些轨迹数据蕴涵着丰富的信息,反映了人群移动特征和交通路况特点,对合理规划城市设施的布局、改善交通状况、规划人们行程等方面具有重大意义。但是同时,海量轨迹数据给数据存储、传输、查询及数据分析带来巨大的挑战:1)数据规模膨胀,单机轨迹数据库在处理海量轨迹时效率低下,无法支持频繁的更新和插入操作;2)轨迹查询和分析面临瓶颈,轨迹数据是高维数据,当数据量很大时,即使建立索引,查询性能也难以满足高要求;3)轨迹的误差及冗余轨迹增多,占用带宽,影响传输效率。如何在支持定位服务技术的应用前提下缩小轨迹规模,减少冗余数据,并高效存储数据以支持查询和分析,是目前面临的巨大难题。
在此背景下,轨迹压缩技术应运而生,成为解决数据快速增长的一种有效方案。轨迹压缩技术能够消除冗余和不必要的轨迹采样点以降低存储耗费,同时保留轨迹的实用性。
目前基于轨迹数据的压缩方法已有诸多工作,主要有两种类型:空间轨迹压缩算法和时空轨迹压缩算法。最早的线段简化方法,是将轨迹视为线段,在欧式空间内进行压缩,其主要思想是一条由离散点组成的曲线,通过另外一条包含更少的点的曲线来近似原始曲线,并保证与原始曲线之间的差距较小。基于此思想,轨迹压缩即是找寻一条含有更少的点的近似轨迹来代替原始轨迹,从而达到压缩轨迹的目的。典型的空间轨迹压缩算法有douglas-peucker(dp)算法和bellman算法。然而,轨迹与单纯的曲线并不完全相同,轨迹数据除了坐标外,还有时间信息。近几年,诸多学者聚焦于时空轨迹压缩算法(如td-tr、slidingwindowalgorithm、squish等),以改进线段简化方法,使之更适合轨迹数据。上述算法的共性在于,假定移动对象在移动的过程中速度或方向保持不变,挖掘待压缩轨迹数据的时空特性,然而这种假设在现实复杂的交通状况下过于乐观,因此这些算法很难在实际应用中实现高压缩率。最近,一种基于数据驱动的压缩算法——press算法提出,利用最短路径和频繁轨迹模式来压缩路网中的轨迹。press正常运行的两个先决条件是:1)对象的移动活动必须限制在路网中;2)路网必须相对稳定。在条件1)的限制下,press无法对自由空间的移动对象(如动物、飞行物体等)或特定空间的轨迹(如手绘轨迹数据)进行有效压缩;对于条件2),在某些地区,尤其是发展中国家(如中国的某些大城市),其路网结构会发生频繁的变化,而press算法随着路网的变化,不得不重新计算所有的最短路径,耗费大量的时间,同时,press算法需要记录每个路网结构的所有最短路径,需要大量的存储空间。
技术实现要素:
本发明主要解决的技术问题是提供一种基于轨迹字典的时空轨迹压缩方法,分别针对空间轨迹数据和时候轨迹数据,提出了3种轨迹建立方法和2种轨迹压缩算法,既保证了压缩率又能保证较高的轨迹压缩质量,具有可靠性高、准确性强等优点,同时咋数据库、数据分析、数据挖掘、轨迹数据查询与分析、轨迹数据挖掘的应用及普及上有着广泛的市场前景。
为解决上述技术问题,本发明采用的一个技术方案是:提供了一种基于轨迹字典的时空轨迹压缩方法,包括轨迹字典集的建立和基于轨迹字典集的轨迹压缩两部分,具体包括以下具体步骤:
1)轨迹字典集的建立
1.1)基于频繁轨迹模式的轨迹字典集建立,利用序列模式挖掘方法提取轨迹的频繁模式,由于轨迹数据是时空连续数据,利用计算点和计算轨迹将轨迹数据进行离散化;
1.1.1)找到所有的计算点和计算轨迹;
1.1.2)扫描所有的计算点,得到频繁计算点,即计算点发生的次数大于给定的支持阈值;
1.1.3)使用频繁计算点对每条计算轨迹进行分割,即去掉轨迹中的非频繁计算点,获得频繁计算轨迹;
1.1.4)若得到的频繁轨迹是另一段频繁轨迹的子集,则删掉该频繁轨迹;
1.1.5)得到频繁轨迹字典集;
1.2)降低冗余的轨迹字典集建立,分为降低轨迹段冗余的挖掘算法和降低轨迹冗余的挖掘算法;
1.2.1)降低轨迹段冗余的挖掘算法,首先对冗余轨迹段进行定义,给定最短轨迹长度阈值γ和距离阈值∈,对于两条相同长度的轨迹段ta(i,i+m)和tb(j,j+m),若其相互对应的点之间的最大距离不超过空间偏差阈值∈,即dmax=max0≤k≤md(ta.pi+k,tb.pj+k)≤∈且m≥γ,则称ta(i,i+m)和tb(j,j+m)相互重叠,若一条子轨迹段s与现有的轨迹字典集中的任意子轨迹段重叠,则称s为冗余轨迹段,消除所有的冗余轨迹段,将其他非冗余轨迹段作为轨迹字典;
1.2.2)降低轨迹冗余的挖掘算法,若最短轨迹长度阈值γ太小的话,srr算法生成的轨迹字典集可能会产生许多短轨迹段;反之若太长,则会产生许多整条的轨迹,与srr算法不同的是,trr是将整条轨迹作为处理对象,消除所有的冗余轨迹,将剩余的非冗余轨迹作为轨迹字典;
1.3)基于压缩算法的轨迹字典集建立
采用空间轨迹压缩算法对训练轨迹集进行压缩,并将压缩率低于某一给定阈值的轨迹添加到轨迹字典集中。
2)基于轨迹字典集的轨迹压缩
2.1)基于轨迹字典集的空间压缩算法
2.1.1)可匹配参考轨迹定义,给定一个空间距离阈值,每段轨迹被它邻域范围内的轨迹字典集表示,这些轨迹字典集称为该段轨迹的可匹配参考轨迹;
2.1.2)基于贪婪算法的轨迹空间压缩,按照采样点的时间顺序压缩待压缩轨迹t,每次贪婪地选取当前点所对应的最长mrt来代替原始待压缩轨迹段,直至t的最后一个采样点被压缩;
2.1.3)基于动态规划的最佳轨迹空间压缩
给定待压缩轨迹t和它的mrt集m(t),定义ft[i]为轨迹段t(1,i)对应的压缩轨迹t′(1,i)的最小存储容量,其计算公式为:
其中,单个采样点的mrt集手动设为非空,如
当
2.2)基于轨迹字典集的时空压缩算法
2.2.1)时间纠正成本的定义
给定空间阈值∈和时间阈值ε,若两条轨迹ta和tb,若两者的maxdtw距离不超过空间偏差阈值∈,仍需要修改ta或tb的某些时间戳,使得两条轨迹对应采样点的最大时间差距不超过时间偏差阈值ε,每个时间戳修正都会产生额外的空间存储c,用以记录时间戳修正的位置和新的时间戳,基于ta的时间戳来修正tb的时间戳,所产生的额外的时间纠正成本,记为
2.2.2)基于贪婪算法的时空压缩算法
跟gsc算法相似,gstc算法同样利用最长mrt轨迹代替当前轨迹段,然而gsc是用m(t(i,j))的任意一条mrt来表示t(i,j),而gstc是用m(t(i,j))中时间纠正成本最小的mrt即mopt(t(i,j)),计算如下来表示t(i,j),
由于计算mopt(t(i,j))仅需线性扫描每条选定的最长mrt,其于|t|存在线性关系,因此最坏情况下,gstc的时间复杂度与gsc相同;
2.2.3)基于动态规划的时空压缩算法
gstc在选择mrt来代替待压缩轨迹段的时候,先考虑最长mrt,再考虑最长mrt中的纠正时间成本,最终选择最小纠正时间成本的最长mrt,但是,有时使用更少时间纠正成本的较短mrt可能会节省更多的存储空间,为实现最小存储成本,必须同时考虑mrts的数量和时间纠正成本,因此,将osc扩展为ostc,计算公式为:
上述公式,ft[i]记录压缩t(1,i)所需的最小空间存储,ft[0]=0代表公式的终止条件,当i≥1,gstc算法同样有两种选择:a.保留带压缩轨迹的原始采样点pi∈t,占用12字节;b.用mopt(t(j,i))压缩t(j,i)。
在本发明一个较佳实施例中,所述的步骤1.1)中的计算点的定义为:给定一个采样点集p={p1,p2,…,pn},若|pi.x-pi.x|≤δx且|pi.y-pi.y|≤y,则pj可以用pi来表示,pi称为计算点a;计算轨迹是一系列按照时间排序的计算点序列。
在本发明一个较佳实施例中,所述的步骤1.1)中的频繁轨迹模式包括通勤模式、高/低峰模式和周末模式。
在本发明一个较佳实施例中,所述的步骤1.2)中的冗余轨迹的定义为:给定一个覆盖阈值θ和一个空间距离偏差阈值∈,若轨迹t和轨迹字典集r的重叠率l(t,r)超过θ,则t称为冗余轨迹,其中l(t,r)的计算如下:
trr算法检查每一条训练轨迹t,并计算其与r的覆盖率,若覆盖率低于θ,则将t加到r中作为参考轨迹。
在本发明一个较佳实施例中,所述的步骤2.1)中的可匹配参考轨迹的定义为:给定一段子轨迹t(i,j)和一个空间距离阈值∈,m(t(i,j))是t(i,j)的可匹配参考轨迹集,当且仅当m(t(i,j))满足m(t(i,j))={r(k,g)|r∈r,1≤k≤g≤|r|,maxdtw(t(i,j),r(k,g))≤∈}每一个mrt——r(k,g)用一个三元组(r.id,k,g)来表示,仅记录参考轨迹r的id及其起点位置(k)、终点位置(g),存储空间为8字节。
本发明的有益效果是:本发明的基于轨迹字典的时空轨迹压缩方法,分别针对空间轨迹数据和时候轨迹数据,提出了3种轨迹建立方法和2种轨迹压缩算法,既保证了压缩率又能保证较高的轨迹压缩质量,具有可靠性高、准确性强等优点,同时咋数据库、数据分析、数据挖掘、轨迹数据查询与分析、轨迹数据挖掘的应用及普及上有着广泛的市场前景。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图,其中:
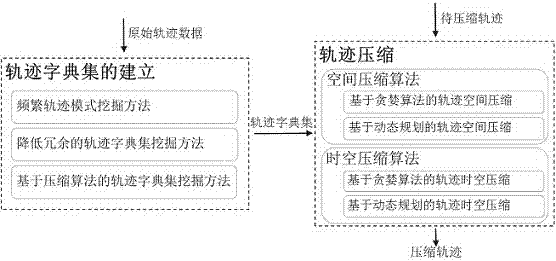
图1是本发明基于轨迹字典的时空轨迹压缩方法的一较佳实施例的流程框图;
图2maxdtw计算示意图;
图3示例图;
图4可匹配参考轨迹集;
图5本发明中建立轨迹字典集所需轨迹数量对各种轨迹生成方法轨迹字典集大小(采样点数量)的影响示意图;
图6本发明中建立轨迹字典集所需轨迹数量对各种轨迹生成方法后期轨迹压缩率的影响示意图;
图7本发明中空间偏差阈值对对各种轨迹生成方法轨迹字典集大小(采样点数量)的影响示意图;
图8本发明中空间偏差阈值对各种轨迹生成方法后期轨迹压缩率的影响示意图;
图9本发明中空间偏差阈值对各种压缩方法压缩率的影响示意图;
图10本发明中空间偏差阈值对各种压缩方法运行时间的影响示意图;
图11本发明中时间偏差阈值对各种压缩方法压缩率的影响示意图;
图12本发明中时间偏差阈值对各种压缩方法运行时间的影响示意图;
图13本发明中轨迹长度对各种压缩方法平均压缩率的影响示意图;
图14本发明中轨迹长度对各种压缩方法平均运行时间的影响示意图。
具体实施方式
下面将对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示,本发明实施例包括:
一种基于轨迹字典的时空轨迹压缩方法,包括轨迹字典集的建立和基于轨迹字典集的轨迹压缩两部分,具体包括以下具体步骤:
1)轨迹字典集的建立
1.1)基于频繁轨迹模式的轨迹字典集建立,利用序列模式挖掘方法提取轨迹的频繁模式,由于轨迹数据是时空连续数据,利用计算点和计算轨迹将轨迹数据进行离散化;
1.1.1)找到所有的计算点和计算轨迹;
1.1.2)扫描所有的计算点,得到频繁计算点,即计算点发生的次数大于给定的支持阈值;
1.1.3)使用频繁计算点对每条计算轨迹进行分割,即去掉轨迹中的非频繁计算点,获得频繁计算轨迹;
1.1.4)若得到的频繁轨迹是另一段频繁轨迹的子集,则删掉该频繁轨迹;
1.1.5)得到频繁轨迹字典集;
1.2)降低冗余的轨迹字典集建立,分为降低轨迹段冗余的挖掘算法和降低轨迹冗余的挖掘算法;
1.2.1)降低轨迹段冗余的挖掘算法,首先对冗余轨迹段进行定义,给定最短轨迹长度阈值γ和距离阈值∈,对于两条相同长度的轨迹段ta(i,i+m)和tb(j,j+m),若其相互对应的点之间的最大距离不超过空间偏差阈值∈,即dmax=max0≤k≤md(ta.pi+k,tb.pj+k)≤∈且m≥γ,则称ta(i,i+m)和tb(j,j+m)相互重叠,若一条子轨迹段s与现有的轨迹字典集中的任意子轨迹段重叠,则称s为冗余轨迹段,消除所有的冗余轨迹段,将其他非冗余轨迹段作为轨迹字典;
1.2.2)降低轨迹冗余的挖掘算法,若最短轨迹长度阈值γ太小的话,srr算法生成的轨迹字典集可能会产生许多短轨迹段;反之若太长,则会产生许多整条的轨迹,与srr算法不同的是,trr是将整条轨迹作为处理对象,消除所有的冗余轨迹,将剩余的非冗余轨迹作为轨迹字典;
1.3)基于压缩算法的轨迹字典集建立
采用空间轨迹压缩算法对训练轨迹集进行压缩,并将压缩率低于某一给定阈值的轨迹添加到轨迹字典集中。
2)基于轨迹字典集的轨迹压缩
2.1)基于轨迹字典集的空间压缩算法
2.1.1)可匹配参考轨迹定义,给定一个空间距离阈值,每段轨迹被它邻域范围内的轨迹字典集表示,这些轨迹字典集称为该段轨迹的可匹配参考轨迹;
2.1.2)基于贪婪算法的轨迹空间压缩,按照采样点的时间顺序压缩待压缩轨迹t,每次贪婪地选取当前点所对应的最长mrt来代替原始待压缩轨迹段,直至t的最后一个采样点被压缩;
2.1.3)基于动态规划的最佳轨迹空间压缩
给定待压缩轨迹t和它的mrt集m(t),定义ft[i]为轨迹段t(1,i)对应的压缩轨迹t′(1,i)的最小存储容量,其计算公式为:
其中,单个采样点的mrt集手动设为非空,如
当
2.2)基于轨迹字典集的时空压缩算法
2.2.1)时间纠正成本的定义
给定空间阈值∈和时间阈值ε,若两条轨迹ta和tb,若两者的maxdtw距离不超过空间偏差阈值∈,仍需要修改ta或tb的某些时间戳,使得两条轨迹对应采样点的最大时间差距不超过时间偏差阈值ε,每个时间戳修正都会产生额外的空间存储c,用以记录时间戳修正的位置和新的时间戳,基于ta的时间戳来修正tb的时间戳,所产生的额外的时间纠正成本,记为
2.2.2)基于贪婪算法的时空压缩算法
跟gsc算法相似,gstc算法同样利用最长mrt轨迹代替当前轨迹段,然而gsc是用m(t(i,j))的任意一条mrt来表示t(i,j),而gstc是用m(t(i,j))中时间纠正成本最小的mrt即mopt(t(i,j)),计算如下来表示t(i,j),
由于计算mopt(t(i,j))仅需线性扫描每条选定的最长mrt,其于|t|存在线性关系,因此最坏情况下,gstc的时间复杂度与gsc相同;
2.2.3)基于动态规划的时空压缩算法
gstc在选择mrt来代替待压缩轨迹段的时候,先考虑最长mrt,再考虑最长mrt中的纠正时间成本,最终选择最小纠正时间成本的最长mrt,但是,有时使用更少时间纠正成本的较短mrt可能会节省更多的存储空间,为实现最小存储成本,必须同时考虑mrts的数量和时间纠正成本,因此,将osc扩展为ostc,计算公式为:
上述公式,ft[i]记录压缩t(1,i)所需的最小空间存储,ft[0]=0代表公式的终止条件,当i≥1,gstc算法同样有两种选择:a.保留带压缩轨迹的原始采样点pi∈t,占用12字节;b.用mopt(t(j,i))压缩t(j,i)。
上述中,所述的步骤1.1)中的计算点的定义为:给定一个采样点集p={p1,p2,…,pn},若|pi.x-pi.x|≤δx且|pi.y-pi.y|≤y,则pj可以用pi来表示,pi称为计算点a;计算轨迹是一系列按照时间排序的计算点序列。其中,所述的步骤1.1)中的频繁轨迹模式包括通勤模式、高/低峰模式和周末模式。
进一步的,所述的步骤1.2)中的冗余轨迹的定义为:给定一个覆盖阈值θ和一个空间距离偏差阈值∈,若轨迹t和轨迹字典集r的重叠率l(t,r)超过θ,则t称为冗余轨迹,其中l(t,r)的计算如下:
trr算法检查每一条训练轨迹t,并计算其与r的覆盖率,若覆盖率低于θ,则将t加到r中作为参考轨迹。
所述的步骤2.1)中的可匹配参考轨迹的定义为:给定一段子轨迹t(i,j)和一个空间距离阈值∈,m(t(i,j))是t(i,j)的可匹配参考轨迹集,当且仅当m(t(i,j))满足m(t(i,j))={r(k,g)|r∈r,1≤k≤g≤|r|,maxdtw(t(i,j),r(k,g))≤∈},每一个mrt——r(k,g)用一个三元组(r.id,k,g)来表示,仅记录参考轨迹r的id及其起点位置(k)、终点位置(g),存储空间为8字节。
本实施例中,相关符号的定义为:t表示原始轨迹;t′表示压缩轨迹;t*表示压缩轨迹t′重建后的轨迹;t(i,j)表示轨迹t从采样点i到采样点j的轨迹段;d表示轨迹数据集;r表示参考轨迹数据集/轨迹字典集;r表示参考轨迹;
∈表示空间偏差阈值;ε表示时间偏差阈值。
(1)轨迹:随着无线通信及定位技术的快速发展,人们已经可以轻松地获取移动物体(比如人、车辆或发动物)在不同时刻的位置信息,这一类的运动过程通常被记录为一系列三元组(x,y,t),其中x和y是坐标信息,它们联合起来标明了二维平面上的一个点,而t是该位置点的采样时间。
(2)子轨迹段:子轨迹段是用t(i,j)表示,是从第i个采样点到第j个采样点的一系列连续的采样点组成,如t(i,j):((xi,yi,ti),…(xj,yj,tj))。
轨迹压缩本质上是将原始轨迹t转换成压缩轨迹t′,具体策略如下:1)减少采样点的数量;2)减少存储每个采样点的空间存储。一个轨迹压缩算法可能会采用上面的一种或两种策略。一般情况下,存在两种轨迹压缩的衡量方案:1)压缩率,来衡量轨迹压缩过程中能节省多少空间,通常用原始轨迹的存储空间与压缩轨迹的存储空间的比值来表示,如,
(3)有界限的有损压缩(boundedlossycompression,blc):给定一个偏差阈值∈,∈-blc算法试讲原始轨迹t转换为压缩轨迹t′,使得重建后的轨迹t*与原始轨迹t的距离不超过∈,如d(t,t*)≤∈,d是某个预定义距离函数。
衡量压缩轨迹的偏差需要一个合适的轨迹距离函数,由于现存的典型轨迹距离函数,如动态时间规整(dynamictimewarping,dtw)、合适补偿编辑距离(editdistancewithrealpenalty,erp)、最长公共子序列(longestcommonsubsequence,lcss)等是全局(聚合)性距离衡量方法,直接运用这些距离函数会导致局部误差(而总误差仍满足阈值),而且由于这些距离函数依赖于轨迹的长度,用户无法直观的定义一个简单的阈值来控制压缩损失。因此,提出一种简单有效的dtw距离的变体,称为maxdtw,其计算流程与dtw相同,都是在两条非同步化的轨迹中找到一个最佳对齐方式,唯一的不同点在于maxdtw只记录所有相匹配的采样点对的最大距离而不是距离和(dtw记录距离和)。
(4)maxdtw:给定两条轨迹ta=(p1,p2,…pn)和tb=(q1,q2,…qn),两者的maxdtw距离定义如下:
其中,d(a,b)是采样点a和b的某个预定义的距离(通常情况下,指欧氏距离)。跟dtw距离相比,由于maxdtw反映的是点对的最大距离误差,因此能够更加直观地控制压缩损失。以附图1的轨迹段t4(6,11)和t8为例,首先对两条轨迹中的每一对点对的距离进行计算,形成一个距离矩阵;继而利用动态规划算法和上述公式找到最优路线;最终,maxdtw距离取路线中的最大值,如max{0.71,0.5,0.5,0.71,0.71,0.71}=0.71。
(5)基于轨迹字典集的压缩问题定义:不同于以前利用数字地图的压缩方法,本发明采用完全的数据驱动方法来设计压缩算法。通过现存的研究发现,大多数司机在计划他们的形成路线时会有一定的偏爱,即一条新的轨迹往往可以全部或者部分用一系列历史轨迹的组合来表示。因此,用历史轨迹的组合来压缩待压缩轨迹切实可行,并能够节省空间。
本发明定义轨迹字典集(也称为参考轨迹集,referencetrajectoryset,简称r)来表示待压缩轨迹。一个轨迹字典集是从给定区域(也称为兴趣区域,待压缩轨迹也在此区域内)的历史轨迹集中提取。然而轨迹字典集的建立面临的一个困难是如何定义其最优性,这里对于好的轨迹字典集,有两个定性测量——高覆盖率和低冗余度。高覆盖率指的是轨迹字典集有足够的能力来表示兴趣区域内的待压缩轨迹,能够影响压缩率;低冗余度指的是r中大多数轨迹的地理位置和形状具有一定的独特性,而相互覆盖的参考轨迹无法提高压缩的有效性。
给定一个轨迹字典集r、一条待压缩轨迹t和误差阈值∈,基于轨迹字典集的压缩算法是从r中选定一系列轨迹子集来表示t,得到压缩后的轨迹t′,并保证t′和t之间的距离不超过∈。
一个理想的压缩实例是轨迹t能够全部用所选定的参考轨迹集来表示,此时压缩轨迹t′是一个参考轨迹序列,如t′=((r1,s1,e1),(r2,s2,e2)…),其中ri∈r用一个4字节的标识符表示,si(ei)是ri起点(终点)的索引号,分别用一个2字节的整型表示(参考轨迹不会太长)。因此,t′的每个三元组占用8个字节,与原始轨迹的采样点记录具有相同的存储空间(原始轨迹的每个采样点记录经纬度,每个经纬度均占用4个字节,共8个字节)。若原始轨迹是由100个采样点组成,并能够用10条参考轨迹表示,则其压缩率为800/80=10。
一个不可避免的问题是,在误差阈值∈的限制下,原始轨迹可能会存在一部分无法用参考轨迹表示的轨迹段,此时便简单地保留它的原始采样点。因此实际的压缩轨迹t′是一系列t的原始采样点和参考轨迹序列的混合形式,其中每个三元组的第一个比特位可以用来识别此8字节元组是原始轨迹采样点还是参考轨迹,而不产生额外的空间存储。
请参阅图1-14,本发明实施例包括:
一种基于参考轨迹集的轨迹压缩方法,提出了3种轨迹建立方法和2种轨迹压缩算法(分别针对空间轨迹数据和时候轨迹数据)。
一、建立轨迹字典集
有如下三种方法:
(1)基于频繁模式的轨迹字典集的建立(frequentpattern-basedapproach)
基于序列模式挖掘思想,定义计算点(calculatingpoint)和计算轨迹(calculatingtrajectory)将轨迹数据进行离散化,得到频繁的轨迹字典集,具体实施如下:
①找到所有的计算点和计算轨迹;
②扫描所有的计算点,得到频繁计算点,即计算点发生的次数大于给定的支持阈值;
③使用频繁计算点对每条计算轨迹进行分割,即去掉轨迹中的非频繁计算点,获得频繁计算轨迹;
④若得到的频繁轨迹是另一段频繁轨迹的子集,则删掉该频繁轨迹;
⑤得到频繁轨迹字典集。
(2)降低冗余度的轨迹字典集的建立
提出两种将低冗余度的方法:降低轨迹段的冗余度和降低轨迹的冗余度。
①降低轨迹段的冗余度方法
其中降低轨迹段的冗余度方法通过定义冗余轨迹段,并移除冗余轨迹点,以得到轨迹字典集,具体实施如下:
②降低轨迹冗余度的方法
通过降低轨迹的冗余度,得到轨迹字典集的算法如下:
(3)基于压缩算法的轨迹字典集的建立
算法步骤如下:
二、空间轨迹压缩算法
轨迹字典集建立之后,基于此字典集对轨迹进行空间压缩,包括基于贪婪算法的空间轨迹压缩和基于动态规划算法的最佳空间轨迹压缩。
首先需要计算可匹配参考轨迹(matchablereferencetrajectory,mrt),根据其定义和引理1,可计算mrt,步骤如下:
(1)基于贪婪算法的空间轨迹压缩算法步骤如下:
(2)基于动态规划算法的最佳空间轨迹压缩算法步骤如下:
三、时空轨迹压缩算法
基于轨迹字典集对轨迹进行时空压缩,包括基于贪婪算法的时空轨迹压缩和基于动态规划算法的最佳时空轨迹压缩。
(1)基于贪婪算法的时空轨迹压缩
跟gsc算法相似,gstc算法同样利用最长mrt轨迹代替当前轨迹段,然而gsc是用m(t(i,j))的任意一条mrt来表示t(i,j),而gstc是用m(t(i,j))中时间纠正成本最小的mrt(即mopt(t(i,j)))来表示t(i,j),算法与gsc类似,此处不再赘述。
(2)基于动态规划算法的最佳空间轨迹压缩
为实现最小存储成本,必须同时考虑mrts的数量和时间纠正成本,因此,将osc扩展为ostc,算法与ostc相似,不同之处在于比osc多了mopt(t(i,j))的计算步骤,此处不再赘述。
四、实验结果
本发明具有高效性,基于真实的出租车轨迹数据进行了广泛的实验研究,所有的实验在配置为intel(r)xeon(r)cpue5-2630v2@2.60ghz256gbram.的服务器上实施。
实验数据是北京市一周大约200万条轨迹数据,本发明采用一天的轨迹数据(大约28万条)作为训练数据来提取轨迹字典集,剩下的数据用来验证不同压缩算法在不同参数设置下的性能(注:在实验中仅记录一天的平均性能)。
对比参数值及其默认设置如下表所示:
本发明的基于轨迹字典的时空轨迹压缩方法相比于现有技术具有如下优点:
1)无空间限制,即可以压缩任意空间的轨迹数据;
2)同时考虑时间和空间特征;
3)不依赖于数字地图/路网;
4)所需内存空间小。
综上所述,本发明的基于轨迹字典的时空轨迹压缩方法,主要解决的技术问题是通过对历史轨迹数据进行分析,提取覆盖率高且精简的轨迹字典集,并在此基础上提出了两种轨迹压缩算法:基于贪婪算法的近似轨迹压缩算法和基于动态规划的最优轨迹压缩算法,在时间和空间阈值已知的情况下,将待压缩轨迹用一系列历史轨迹(又称为参考轨迹)组合序列来表示,分别针对空间轨迹数据和时候轨迹数据,提出了3种轨迹建立方法和2种轨迹压缩算法,既保证了压缩率又能保证较高的轨迹压缩质量,具有可靠性高、准确性强等优点,同时咋数据库、数据分析、数据挖掘、轨迹数据查询与分析、轨迹数据挖掘的应用及普及上有着广泛的市场前景。
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书内容所作的等效结构或等效流程变换,或直接或间接运用在其它相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!