一种稀疏矩阵LU分解行更新的异构并行计算方法与流程
本发明涉及一种稀疏矩阵lu分解行更新的异构并行计算方法,属于稀疏矩阵lu分解的
技术领域:
。
背景技术:
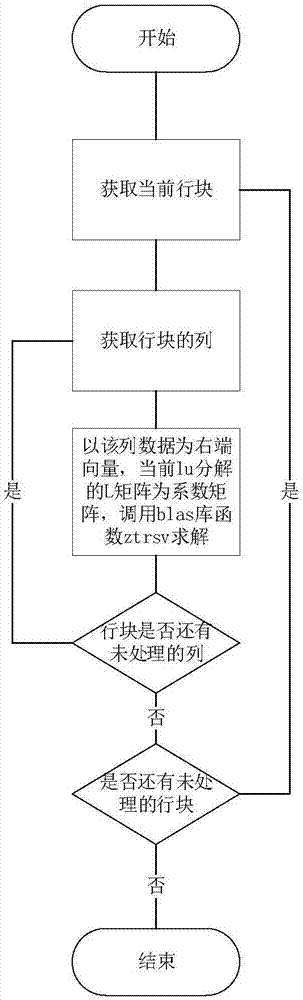
:近年来,我国在与电磁密切相关的领域取得了一系列重大进展,其中电磁场数值计算因其高效、灵活、方便等显著优势,日益发挥着越来越重要的作用,在电磁场数值分析方法中矩量法具有高理论精度的特点,矩量法把所要求解的电磁场算子方程转化为矩阵方程,由于其理论精度高,在处理诸如机载相控阵等复杂电大系统电磁问题时,会产生庞大的复数稀疏矩阵,从而出现了一个计算存储资源与计算时间代价很高的瓶颈问题,解决途径就是采用快速算法,直接从计算角度出发来扩展矩量法的计算规模,采用核外lu分解求解矩阵方程,在扩大规模的同时既不会带来精度损失,也不会存在收敛风险。核外lu分解常用的求解软件superlu是一个直接求解面向大规模稀疏非对称线性方程组的通用库。在“神威﹒太湖之光”平台上,通常被采用的是并行版本的superlu_dist,该版本采用的是基于超节点的lu分块分解并行算法,该算法在求解过程中会大量调用blas库,而blas库因其对太湖之光异构环境的支持度不好,导致其效率并不高,从而产生了计算瓶颈。“神威﹒太湖之光”是一款由中国自主研发的主从异构平台,承载着计算电磁学中超大规模并行矩量法的高性能实现,但即便采用了该平台提供的高性能扩展数学库xmath,通用的求解器软件superlu在该平台效果并不理想。“神威﹒太湖之光”采用的是国产申威众核处理器26010,它是一款由中国自主研发的主从异构平台,每个节点由4个核组和系统接口组成,每个核组主要包括1个主核和1个从核阵列,从核阵列由64个从核构成的8行8列的mesh结构。主核和从核都支持256位向量浮点指令扩展;每个从核包含32个寄存器以及64kb用户可控的ldm(localdevicememory,局部存储器),且直接访问本地ldm延迟极小;提供主从核间dma异步传输机制,dma包含多种数据传输模式,其中常用的有单从核模式与行模式,不同的数据传输模式对应不同的数据分布方式,能够实现数据从主存到从核ldm的快速传输;从核阵列内部交互使用寄存器级通信,以一个向量长度为单位,各从核可在其行或列上进行数据广播或数据接收。superlu数值分解算法描述如下:矩阵a有如下分解式:a=lu,公式中,a为稀疏数据矩阵,l为下三角矩阵;u为上三角矩阵。在superlu中,数据矩阵在完成符号分解后,确定了a的超节点结构,将a划分成由n×n个块矩阵组成的矩阵,并从1行1列开始对其进行分解。假设a中前k-1列和k-1行已分解,那么对a_kk即a的第k行k列块矩阵进行lu分解,产生如式a_kk=l_kk×u_kk;然后对a的第k列进行列分解,按公式l_ik=a_ik×u_kk^(-1)进行;再对a的第k行进行更新u_kj=l_kk^(-1)×a_kj;最后按公式a_ij=a_ij-l_ik×u_kj对k+1及以后的行列进行trailing更新;然后再对第k+1列重复进行上面的操作。在行更新阶段,superlu将进行大量的单位下三角矩阵方程组求解运算,而该类型的求解过程在调用通常的太湖之光提供的blas库时,其效率并不高,大大低于单纯主核的运行效率,从而产生了计算瓶颈。技术实现要素:针对现有技术的不足,本发明提供一种稀疏矩阵lu分解行更新的异构并行计算方法。发明概述:本发明在superlu算法的基础上,结合太湖之光的主从异构特点,使superlu求解器在矩阵分解阶段,对行更新的过程中,将大规模计算任务转移至从核,利用从核组高效的计算和数据通信能力,提高超大规模稀疏矩阵的求解计算能力,进一步求解的整体性能。本发明的技术方案为:一种稀疏矩阵lu分解行更新的异构并行计算方法,包括主核部分和从核部分;行更新主核部分的具体实现如下:a1)在行更新阶段,获取当前待处理的行矩阵块,对行矩阵块的每个列向量进行分析,统计每个向量在内存中的起始位置和向量的大小,生成索引数组;向量在内存中的起始位置对应列向量非零元数据的存储位置,向量的大小对应列向量非零元数据的个数;索引数组的索引号对应行矩阵块的列向量;对行矩阵块的每个列向量进行分析的目的就是,为从核的计算提供获取数据位置的索引,如果不做这步,从核在计算时,就需要做这个工作,这些向量的位置信息在主核内存中是不连续的,从核访问不连续的数据的性能非常低,不利于提高整个算法的效率。将这步放在主核上进行,相比从核,主核访问主核内存的效律更高。a2)从核初始化;具体包括:a2.1)初始化从核库,获取从核的环境参数;获取从核的环境参数以便于分配调度核组中各个从核的计算任务;a2.2)初始化共享内存变量,将从核计算的数据放在共享内存变量中;共享内存变量位于主核内存,保存的数据可以被从核处理器直接寻址和访问,但这种访问方式效率不高,需要用更高效的dma方式进行数据传输;a3)调用从核阵列函数,从核阵列函数在从核上启动并运行行更新任务;a4)对当前数值分解的行中的每个行矩阵块进行步骤a1)-a3)的操作;行更新从核部分的具体实现如下:b1)从核获取主核传输过来的参数,主核传输过来的参数包括,核组中参与计算的总核数ncore和当前从核的id号;b2)获取待求解行矩阵块的列向量的维数n,根据从核的ldm最大容量计算最大可传输的系数矩阵acol的列数nacol和右端项向量bcol的个数nbcol;nacol=(64×1024-k)/n×16-2,如果nacol的值大于0,则nbcol=2,否则,令nacol=1,nbcol=1;其中k变量值是除参与计算的矩阵数据之外的一些临时变量所占用的空间,在本发明中此值为512,n为矩阵的行数;该计算方法是本发明的一部分,由于太湖之光每个从核的ldm容量有限,只有64kb,如何充分发挥ldm的作用,同时确保主核与从核间尽可能少的通讯量,是设计众核算法必须考虑的问题,本发明对参与计算的从核进行任务平摊,确保每个从核完成相同的任务量,例如,对于一个n列的矩阵,那么每个从核处理的列数就是n/ncore,另外,由于ldm容量有限,不可能将n/ncore列数据一下加载到从核,因此需要分步加载,确保ldm够用。根据nacol和nbcol为ldm数组acol和bcol分配空间,数组acol和bcol的大小分别为nacol×n和nbcol×n;采用dma方式将主存的共享内存变量中的系数矩阵数据传输到列数为nacol的数组acol中,将右端项向量数据传输到列数为nbcol的数组bcol中;计算完一个列向量后,在计算下一个列向量时,如果从核处理的nacol和nbcol均大于1,则通过dma方式获取下一个列向量并填充到刚计算完的数组bcol和acol中;从核处理的数据列数不可能小于1,如果小于1,说明这个从核没有计算任务;等于1时,说明待处理的数据量很少,就不需要边计算变获取数据,只需要一次性将数据获取处理完即可;将下一列数据填充刚计算完的数组可以让通信和计算同步进行,避免等待时间,提高计算效率;b3)对当前ldm中的数组acol和数组bcol进行回代法求解,求解结果覆盖数组bcol,数组bcol的值为方程组的解;b4)通过dma方式将bcol的值传输给主核;b5)核组所有从核完成计算任务后退出从核任务,至此完成行更新任务。优选的,所述步骤a2.1)中从核的环境参数包括,可运行的从核数量。可运行的从核是指当前可用于计算的从核。优选的,所述步骤a2.2)中,从核计算的数据包括三角矩阵数据、行矩阵块数据;核计算的数据采用列优先方式,存储在共享内存变量中。矩阵块数据在逻辑上是二维的,是按行和列进行划分的,程序计算时,二维数据需要存到一维数组里,列优先方式即优先将第一列数据依次存入一维数组中,再将第二列数据依次存入一维数组中,依次类推,最终实现将二维数据存到一维数组中。列优先方式存储实现从核运算时批量按列从主核中读取,提高数据通信速度。根据本发明优选的,所述步骤b2)中,将右端项向量数据传输到bcol中的传输方式为双缓冲技术。本发明的有益效果为:1.本发明所述稀疏矩阵lu分解行更新的异构并行计算方法,按矩阵的数据进行任务划分的方式,对矩阵数据块按行进行划分,首先为每个从核开辟一个矩阵空间,每个从核负责几个矩阵行的求解,在求下三角单位矩阵类型的线性方程组的过程中,各行数据相互独立,避免求解空间发生冲突和依赖,顺利实现对方程组的求解;2.稀疏矩阵在符号分解后,各列的存储不会像稠密矩阵那样按行按列的大小分布,而是按非零元在数组的位置进行分布,矩阵每列非零元的个数不固定,在一个从核里求解方程组,需要获取这些非零元数据在数据存储数组的索引,将这部分功能放在每个从核中计算,每个从核都要重复该过程,势必增大计算开销;本发明将这一过程移至主核,由主核将结果算出并保存在数组变量中,从核部分只需根据列号即可获取矩阵的数据,从而有效提高计算的整体效率。附图说明图1主核版行更新实现示意图;图2为本发明提出的主核部分行更新实现示意图;图3为本发明提出的从核部分行更新实现及系数矩阵a的缓冲区加载流程示意图;图4主、从核矩阵求解的计算性能对比图。具体实施方式下面结合实施例和说明书附图对本发明做进一步说明,但不限于此。实施例一种稀疏矩阵lu分解行更新的异构并行计算方法,包括主核部分和从核部分;如图2所示,行更新主核部分的具体实现如下:a1)在行更新阶段,获取当前待处理的行矩阵块,对行矩阵块的每个列向量进行分析,统计每个向量在内存中的起始位置和向量的大小,生成索引数组;向量在内存中的起始位置对应列向量非零元数据的存储位置,向量的大小对应列向量非零元数据的个数;索引数组的索引号对应行矩阵块的列向量;索引号为1对应第一个列向量,索引号为2对应第二个列向量,依次类推;对行矩阵块的每个列向量进行分析的目的就是,为从核的计算提供获取数据位置的索引,如果不做这步,从核在计算时,就需要做这个工作,这些向量的位置信息在主核内存中是不连续的,从核访问不连续的数据的性能非常低,不利于提高整个算法的效率。将这步放在主核上进行,相比从核,主核访问主核内存的效律更高。a2)从核初始化;具体包括:a2.1)初始化从核库,获取从核的环境参数;从核的环境参数包括,可运行的从核数量。可运行的从核是指当前可用于计算的从核。获取从核的环境参数以便于分配调度核组中各个从核的计算任务;a2.2)初始化共享内存变量,将从核计算的数据放在共享内存变量中;从核计算的数据包括三角矩阵数据、行矩阵块数据;核计算的数据采用列优先方式,存储在共享内存变量中。矩阵块数据在逻辑上是二维的,是按行和列进行划分的,程序计算时,二维数据需要存到一维数组里,列优先方式即优先将第一列数据依次存入一维数组中,再将第二列数据依次存入一维数组中,依次类推,最终实现将二维数据存到一维数组中。列优先方式存储实现从核运算时批量按列从主核中读取,提高数据通信速度。共享内存变量位于主核内存,保存的数据可以被从核处理器直接寻址和访问,但这种访问方式效率不高,需要用更高效的dma方式进行数据传输;a3)调用从核阵列函数athread_spawn,从核阵列函数在从核上启动并运行行更新任务;a4)对当前数值分解的行中的每个行矩阵块进行步骤a1)-a3)的操作;如图3所示,行更新从核部分的具体实现如下:b1)从核获取主核传输过来的参数,主核传输过来的参数包括,核组中参与计算的总核数ncore和当前从核的id号;b2)获取待求解行矩阵块的列向量的维数n,根据从核的ldm最大容量计算最大可传输的系数矩阵acol的列数nacol和右端项向量bcol的个数nbcol;nacol=(64×1024-k)/n×16-2,如果nacol的值大于0,则nbcol=2,否则,令nacol=1,nbcol=1;其中k变量值是除参与计算的矩阵数据之外的一些临时变量所占用的空间,在本发明中此值为512,n为矩阵的行数;该计算方法是本发明的一部分,由于太湖之光每个从核的ldm容量有限,只有64kb,如何充分发挥ldm的作用,同时确保主核与从核间尽可能少的通讯量,是设计众核算法必须考虑的问题,本发明对参与计算的从核进行任务平摊,确保每个从核完成相同的任务量,例如,对于一个n列的矩阵,那么每个从核处理的列数就是n/ncore,另外,由于ldm容量有限,不可能将n/ncore列数据一下加载到从核,因此需要分步加载,确保ldm够用。根据nacol和nbcol为ldm数组acol和bcol分配空间,数组acol和bcol的大小分别为nacol×n和nbcol×n;采用dma方式将主存的共享内存变量中的系数矩阵数据传输到列数为nacol的数组acol中,将右端项向量数据传输到列数为nbcol的数组bcol中;计算完一个列向量后,在计算下一个列向量时,如果从核处理的nacol和nbcol均大于1,则通过dma方式获取下一个列向量并填充到刚计算完的数组bcol和acol中;从核处理的数据列数不可能小于1,如果小于1,说明这个从核没有计算任务;等于1时,说明待处理的数据量很少,就不需要边计算变获取数据,只需要一次性将数据获取处理完即可;将下一列数据填充刚计算完的数组可以让通信和计算同步进行,避免等待时间,提高计算效率;从核的ldm最大容量是64kb。将右端项向量数据传输到bcol中的传输方式为双缓冲技术。b3)对当前ldm中的数组acol和数组bcol进行回代法求解,求解结果覆盖数组bcol,数组bcol的值为方程组的解;b4)通过dma方式将bcol的值传输给主核;b5)核组所有从核完成计算任务后退出从核任务,至此完成行更新任务。对比例如图1所示,现有技术中主核对行进行更新的方法,过程如下:1)在行更新阶段,获取当前待处理的行矩阵块,依次取该行矩阵块的每一列;2)获取该行更新阶段对应的对角矩阵块分解得到的下三角矩阵,该下三角矩阵是单位下三角矩阵;3)将步骤2)获取的下三角矩阵作为系数矩阵a;将步骤1)中行矩阵块的列作为右端项向量b;调用blas库中的ztrsv函数求解线性方程组ax=b,并将求解结果替换与行矩阵块对应的列;4)对所有矩阵块进行步骤1)-3)的处理后,行更新操作完成;将实施例和对比例用神威太湖之光测试平台进行验证,测试矩阵采用下表中的数据,其矩阵信息见表1:表1矩阵信息表稀疏矩阵维数行数列数非零元数n=69839069839069839029971204n=78399478399478399433520820n=14944161494416149441664149928n=20392162039216203921686526112实施例和对比例的测试平台为申威众核平台26010,测试的数据规模分别为698390维、783994维、1494416维、2039216维稀疏矩阵,数据量最大的接近5gb,运行的核数分别为1024核、2048核、3072核、4096核、5120核以及6000核,图4中的1024(32x32)表示进程总核数是1024核,32x32表示这1024核被划分成32核行进程和32核列进程的进程网格,其他的依次类推。运行结果见附图4,从图中运行结果可以看出,众核程序的运行效率明显好于主核程序,效率提高大约10倍左右。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1