基于大数据的数据自动抽取系统的制作方法
本发明涉及数据抽取技术领域,尤其涉及一种基于大数据的数据自动抽取系统。
背景技术
信息是现代企业的重要资源,是企业运用科学管理、决策分析的基础。据不完全统计,数据量每2~3年时间就会成倍增长,这些数据蕴含着巨大的商业价值,而企业所关注的通常只占在总数据量的2%~4%左右。因此,企业仍然没有最大化地利用已存在的数据资源,以致于浪费了更多的时间和资金,也失去制定关键商业决策的最佳契机。于是,企业如何通过各种技术手段,并把数据转换为信息、知识,已经成了提高其核心竞争力的主要瓶颈。而数据抽取则是主要的一个技术手段。
目前常见的数据抽取过程主要还是需要手动编写shell脚本,设置数据源连接、创建数据库以及建表等操作都需手动完成,这种数据抽取的方式是非常浪费时间和人力成本的。如:目前已有的数据抽取方案为etl工具,etl工具实质上仍为一类数据转换器,提供一种从源到目标系统转换数据的方法。即从操作型系统提取、清洗并转换数据,然后将数据载入决策支持系统的操作型数据存储、数据仓库或数据集市中。具体功能针对不同的数据源编写不同的数据抽取、转换和加载程序处理,这完成了数据集成的大部分工作。总的来说,etl工具提供了一种数据处理的通用解决方案。
elt工具的最复杂点在于其涉及到大量的业务逻辑和异构环境,因此在一般的数据仓库项目中etl部分往往也是牵扯精力最多的,因此其主要的难点在于数据的清晰转换功能:字段映射;映射的自动匹配;字段的拆分;多字段的混合运算;跨异构数据库的关联;自定义函数;多数据类型支持;复杂条件过滤;支持脏读;数据的批量装载;时间类型的转换;对各种码表的支持;环境变量是否可以动态修改;去重复记录;抽取断点;记录间合并或计算;记录拆分;抽取的字段是否可以动态修改;行、列变换;排序;统计;度量衡等常用的转换函数;代理主键的生成;调试功能;抽取远程数据;增量抽取的处理方式;制造样品数据;在转换过程中是否支持数据比较的功能;数据预览;性能监控;数据清洗及标准化;按行、按列的分组聚合等。
上述数据抽取方式存在如下缺陷:1、现有的数据抽取技术通常是需要在数据抽取之前编写shell脚本,将数据源连接、建表等操作写在脚本中,如果是对多个数据源进行抽取的话会产生大量重复性的工作。而且脚本编写好之后还需要对这些shell脚本进行管理;2、在抽取过程中无法对抽取过程进行监控,且无法自动记录日志;3、抽取完成后无法自动验证数据量的准确性。
技术实现要素:
为了解决现有技术存在的问题,本发明提供一种基于大数据的数据自动抽取系统。
为了实现上述目的,本发明采用的技术方案是:一种基于大数据的数据自动抽取系统,包括数据源服务器、客户端、数据抽取服务器、数据存储服务器;数据源服务器,用于存储待抽取数据;客户端,用于提供可视化配置界面,通过参数选择来实现数据抽取服务器的自动化数据抽取的配置;数据抽取服务器,包括配置存储模块、全量抽取模块、增量抓取模块、数据对比模块;配置存储模块,用于存储记录有将数据源的相关配置以及数据源表信息的poll表,在之后的抽取过程中只需要根据页面参数来读取poll表信息即可获取抽取前的所有配置;完成配置后,会将选择的参数传递到数据抽取服务器的shell中,然后启动全量抓取模块或增量抓取模块来进行数据抽取的任务;全量抓取模块,根据客户端的配置要求每次将数据源服务器中的数据全部抽取到数据存储服务器中,每次抽取的数据结果会直接覆盖在数据存储服务器的数据表中;增量抓取模块,根据客户端的配置要求每次将数据源服务器中的新增、修改、删除的数据抽取到数据存储服务器中,每次抽取的数据结果会直接添加在数据存储服务器的数据表中;数据对比模块,比对抽取前后的数据量;日志存储模块,用于记录在抽取过程中将相关信息以参数的形式传递并记录在日志信息表中;数据存储服务器,用于存储抽取之后的结果数据。
采用本申请的技术方案后,借助于用于存储记录有将数据源的相关配置以及数据源表信息的poll表,在之后的抽取过程中只需要根据页面参数来读取poll表信息即可获取抽取前的所有配置;完成配置后,会将选择的参数传递到数据抽取服务器的shell中,然后启动全量抓取模块或增量抓取模块来进行数据抽取的任务的配置存储模块;解决了现有技术存在的多个数据源进行抽取的话会产生大量重复性的工作,而且脚本编写好之后还需要对这些shell脚本进行管理的问题。借助于用于记录在抽取过程中将相关信息以参数的形式传递并记录在日志信息表中的日志存储模块,实现了对抽取过程进行监控,并能将信息储存在日志存储模块内。借助于比对抽取前后的数据量的数据对比模块,解决了抽取完成后无法自动验证数据量的准确性的问题。
附图说明
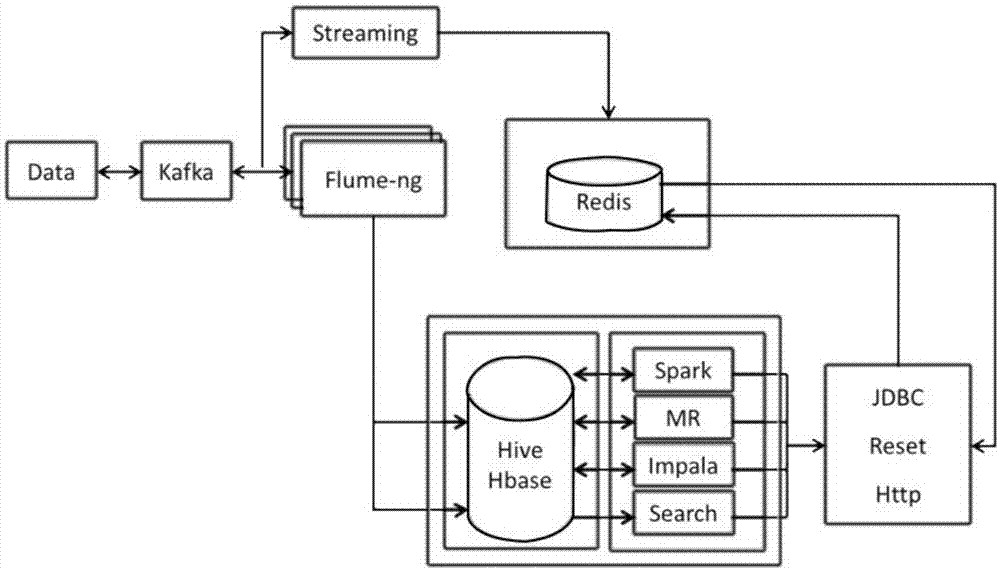
图1是基于大数据的数据自动抽取系统的原理框图。
具体实施方式
下面结合附图对本发明优先的方案做进一步的阐述。
一种基于大数据的数据自动抽取系统,包括数据源服务器、客户端、数据抽取服务器、数据存储服务器。
数据源服务器,用于存储待抽取数据。
客户端,用于提供可视化配置界面,通过参数选择来实现数据抽取服务器的自动化数据抽取的配置。
数据抽取服务器,包括配置存储模块、全量抽取模块、增量抓取模块、数据对比模块;配置存储模块,用于存储记录有将数据源的相关配置以及数据源表信息的poll表,在之后的抽取过程中只需要根据页面参数来读取poll表信息即可获取抽取前的所有配置;完成配置后,会将选择的参数传递到数据抽取服务器的shell中,然后启动全量抓取模块或增量抓取模块来进行数据抽取的任务;全量抓取模块,根据客户端的配置要求每次将数据源服务器中的数据全部抽取到数据存储服务器中,每次抽取的数据结果会直接覆盖在数据存储服务器的数据表中;增量抓取模块,根据客户端的配置要求每次将数据源服务器中的新增、修改、删除的数据抽取到数据存储服务器中,每次抽取的数据结果会直接添加在数据存储服务器的数据表中;数据对比模块,比对抽取前后的数据量;日志存储模块,用于记录在抽取过程中将相关信息以参数的形式传递并记录在日志信息表中。
数据存储服务器,用于存储抽取之后的结果数据。
数据源服务器内设有时间戳生成模块,用于源表数据更新时,该时间戳生成模块将会默认赋值为当前系统时间,并在日志中增加了一个字段进行保存;数据源服务器更新修改表数据的时候,同时修改时间戳字段的值。
数据抽取服务器还包括临时数据存储模块,抽取服务器将从数据源服务器抽取的数据存入到临时数据库中;进行数据抽取时,数据存储模块通过比较数据源服务器的系统时间与时间戳字段的值来决定抽取哪些数据。
数据抽取服务器还包括数据抽取过程针对异常情况进行自动化处理的异常自动处理模块。数据抽取服务器还包括将数据抽取过程出现的异常报错之后进行异常反馈给指定接收人的邮件发送模块。异常自动处理模块将抽取任务会循环执行三次,当第一次执行成功的时候则跳过后两次循环,如果第一次执行错误则会去判断是否是字段类型不匹配的错误,此方式是先读取源库字段类型,然后比对结果库字段类型,如有不正确的地方则自动修改结果库字段类型,然后继续执行抽取任务,并将异常原因和处理结果邮件发送给指定接收人,如果第二次任务仍然失败,那么第三次执行的时候会针对源库连接失败的可能性来自动修正,方式是以更换备用的源库登录名密码的形式来实现的。
为了更好地对本技术方案进行说明,现就对本发明的数据采集原理描述。
如图1所示,数据(data)包括多种数据源,可以是互联网上的海量数据,也可以是已经存储在本地其它数据库内的离线数据。首先通过客户在配置好数据抽取规则。数据的采集分发:多种数据源的数据通过数据抽取服务器上的kafka进行数据采集后进入系统,streaming是一种数据传送技术,它把客户机收到的数据变成一个稳定连续的流,源源不断地送出,使用户听到的声音或看到的图象十分平稳,而且用户在整个文件送完之前就可以开始在屏幕上浏览文件。在streaming的作用下,流式数据转向redis进行直接处理。其它类型的数据通过flume存入hbase或hive进行存储。流式数据:redis需要准备数据通过jdbc等jdbc、reset、http方式存入内存中,流式数据过来后通过内存技术快速处理,处理后的数据可再次使用或通过jdbc、reset、http方式提供数据服务。离线数据:通过flume存入hive或hbase后可以通过spark、mr、impala等方式进行数据处理,可通过jdbc、reset、http的方式提供对外数据服务。
以上实施方式只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人了解本发明的内容并加以实施,并不能以此限制本发明的保护范围,凡根据本发明精神实质所做的等效变化或修饰,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!