本发明涉及光伏发电技术领域,尤其涉及一种基于局部泛化误差模型(localizedgeneralizationerrormodel,简写为l-gem)的径向基函数(radialbasisfunction,简写为rbf)神经网络的光伏发电量预测方法。
背景技术
大规模光伏发电是一种利用太阳能的有效方式,但太阳辐射、大气温度、天气类型和电池板温度等因素容易对光伏发电产生影响,并且呈非线性。因此,光伏发电量的预测对合理安排电器使用时间和最大限度利用太阳能资源、减小用电成本有着重要的意义。而光伏发电量的精确预测依赖于光伏发电量影响因素的合理选择。
径向基函数(radialbasisfunction,rbf)神经网络是一种性能优良的前馈型神经网络,可以任意精度逼近任意的非线性函数,且具有全局逼近能力,而且拓扑结构紧凑,结构参数可实现分离学习,收敛速度快。但采用rbf神经网络进行光伏发电量预测,往往会出现训练好的网络对训练集中的数据产生的误差很小,但对测试集中的数据表现不是很好的情况,即所谓神经网络的泛化能力差的问题;而且,在rbf神经网络应用中,神经网络的参数选择是否合理,会严重影响神经网络的预测。
技术实现要素:
本发明的目的在于克服现有技术中的不足,提供一种基于rbf神经网络的光伏发电量预测方法,解决光伏发电量预测精确度偏低的技术问题。
为解决上述技术问题,本发明所采用的技术方案是:基于rbf神经网络的光伏发电量预测方法,包括如下步骤:
根据光伏发电量及其拟选取影响因素的历史数据构建训练样本;
基于已构建的训练样本,采用改进遗传算法选取光伏发电量影响因素,并对rbf神经网络进行训练,得到光伏发电量影响因素和训练好的rbf神经网络;
将光伏发电量影响因素的待预测日数据输入已训练好的rbf神经网络,得到光伏发电量预测值。
进一步的,所述拟选取影响因素包括:太阳辐射强度、最高温度、最低温度和光伏电池板温度、风速、相对湿度、天气类型。
进一步的,构建训练样本的具体方法如下:
选取光伏发电量的拟选取影响因素的历史数据及其对应的实际发电量;
将光伏发电量的拟选取影响因素的历史数据作为训练样本的输入向量,将对应的光伏实际发电量作为输出向量,并对输入向量和输出向量进行归一化处理。
进一步的,对输入向量和输出向量进行归一化处理的具体方法如下:
将天气类型划分为晴、多云、阴、小雨或雪、中雨或雪、大雨或雪,其对应归一化值分别取1、0.8、0.7、0.5、0.4、0.3,天气类型发生变化的,取变化前后天气类型归一化值的平均值;
除天气类型外,其他拟选取影响因素的历史数据作为输入向量采用以下归一化公式处理:
实际发电量作为输出向量采用以下归一化公式处理:
其中,ni为输入层节点数;xi为归一化处理前历史输入向量中第i个分量;y为归一化处理前历史输出数据,xi,min,xi,max分别为归一化处理前历史输入向量中第i个分量的最小值和最大值,ymin,ymax分别为归一化处理前历史输出数据中的最小值和最大值,为归一化处理后的历史输入向量中第i个分量,为归一化处理后的历史输出数据。
进一步的,针对已构建的训练样本,采用改进遗传算法选取光伏发电量影响因素,并对rbf神经网络进行训练,得到光伏发电量影响因素和训练好的rbf神经网络;具体方法如下:
a、初始化:设置初始种群大小,通过随机分配0和1创建初始种群,令每个染色体的大小等于光伏发电量的拟选取影响因素的个数;约定具有1的特征形成特征子集,rbf神经网络基于该特征子集进行训练;设置最大迭代次数,并置初始迭代次数为1;
b、计算每个染色体的适应度,并计算最佳适应度;
c、迭代次数加1,如迭代次数大于最大迭代次数,则转步骤h;
d、按复制概率进行复制操作;
e、按交叉概率对种群中染色体进行交叉操作;
f、按变异概率对染色体进行变异操作;
g、循环步骤b~f;
h、输出最佳适应度及其对应的最优染色体,其中最优染色体代表最优的光伏发电量影响因素、最佳适应度代表最优的局部泛化误差模型的误差界。
进一步的,计算每个染色体适应度的公式为:
其中,fitnessi为第i个染色体的适应度,是利用局部泛化误差模型计算得到的第i个rbf神经网络的误差界;sq代表全部样本点的q邻域的并集;
rbf神经网络为单输出径向基函数神经网络,表达形式如下:
其中,f(x)是rbf神经网络的真实输出,m代表隐层节点数,由公式求得;n为训练样本输入向量中的特征数;a为1至10之间的常数;wj代表第j个隐层神经元连接到输出层神经元的权重;uj为第j个隐层神经元的中心向量值;vj为第j个隐层神经元的高斯基函数的宽度;x为rbf神经网络的输入;
采用下述公式求得:
其中:
其中,f(x)为rbf神经网络的期望输出;l是训练样本数;和分别代表第i个特征的期望与方差;c为一正常数;q为一给定的正实数;ed[]为数学期望,uji为uj的第i个分量,remp为rbf神经网络输出的均方差;γj、ξj、sj均为中间变量,无实际含义。
进一步的,所述rbf神经网络的中心由k-means聚类算法求得,具体方法如下:
1-a、从nn个数据对象中任意选择kk个数据对象作为初始聚类中心;
1-b、计算每个数据对象与聚类中心的距离,并根据最小距离对相应数据对象进行划分;
1-c、重新计算每个有变化聚类的均值,将求得的均值作为聚类中心;
1-d、重复步骤1-b、1-c,直到所有均值的变化小于给定阈值;
在rbf神经网络的中心已经确定的情况下,采用下述方法求取rbf神经网络的宽度,具体方法如下:
2-a、求出所有聚类中心对的距离m1=1,2,...,m,n1=m1+1,m1+2,...,m,且m1≠n1;其中,代表第m1个聚类中心;代表第n1个聚类中心;m表示需要求解的权值数;
2-b、对所得聚类中心对的距离排序,每个rbf神经网络宽度vj取相同的值v,且正比于前p个最小距离的平均值。
进一步的,采用改进头脑风暴算法求得rbf神经网络的权重,具体方法如下:
3-a、随机产生n2个个体,每个个体有m维,每一维代表一rbf神经网络权值;
3-b、用k-means将这n2个个体分为m2类;
3-c、评估这n2个个体;
3-d、将每一类中的个体进行排序,选出每一类内最优的个体作为该类的聚类中心;
3-e、随机产生一个0到1间的数值r1;
(3-e1)如果r1<概率参数p1,
i.随机选择一个聚类中心;
ii.随机产生一个个体代替该聚类中心;
3-f、进行个体的更新:
(3-f1)随机产生一个0到1间的数值r2;
(3-f2)如果r2小于概率参数p2;
i.按概率随机选择一个聚类;
ii.随机产生一个0到1间的数值r3;
iii.如果r3小于概率参数p3,选择聚类中心加上随机扰动产生新个体;
iv.否则,随机产生一个0到1间的数值r4;
v.如果r4小于概率参数p4,从该类中随机选择一个个体,加上随机扰动产生新个体;
vi.否则,从该类中随机选择2个个体,互相融合加上随机扰动产生一个新个体;
(3-f3)否则,随机选择两个类产生新个体
i.随机产生一个0到1间的数值r5;
ii.如果r5小于概率参数p5,将两个类的聚类中心互相融合加上随机扰动产生一个新个体;
iii.否则,随机产生一个0到1间的数值r6;
iv.如果r6小于概率参数p6,将第一个类的聚类中心与从第二个类中随机选择的一个个体互相融合加上随机扰动产生一个新个体;
v.否则,分别从两个类中选择一个个体互相融合加上随机扰动产生一个新个体;
(3-f4)新产生的个体与当前个体相比,适应值好的个体作为下次迭代的新的个体;
3-g、如果已产生n个新的个体,转步骤3-h,否则转步骤3-f;
3-h、如果达到最大迭代次数则停止,否则转步骤3-b;
3-i、输出最优个体和最佳适应度;
涉及到2个个体融合的,融合过程按下式进行:
inew=α1i1+(1-α1)i2(12)
式中:inew为2个个体融合产生的子代个体;i1和i2表示接受融合操作的2个个体;α1为一个0到1之间的随机数,用于调节2个个体的权重;
在新个体产生过程中要加上随机扰动,方式如下:
式中:为选中个体在d维上的值;为新产生个体在d维上的取值;n(μ,σ)为高斯随机函数,均值为μ,方差为σ;ξ1为步长,用于调节随机扰动的取值范围;
ξ1取值按下式计算得到:
ξ1=logsig((0.5*max_iteration-current_iteration)/k1)*rand()(14)
式中:logsig()为一个对数s变换函数,max_iteration是最大迭代次数,current_iteration是当前迭代次数,k1为控制logsig()的斜率坡度,rand()产生一个0到1之间的随机数。
9.根据权利要求1所述的基于rbf神经网络的光伏发电量预测方法,其特征在于,光伏发电量影响因素的待预测日数据作为输入向量输入至rbf神经网络之前应当进行归一化处理,预测输出数据经反归一化处理得到待预测日的光伏发电量预测值,反归一化处理的公式为:
其中:为经rbf神经网络预测得到的反归一化处理前的光伏发电量预测数据,y*为反归一化处理后的光伏发电量预测值,ymin、ymax分别为归一化处理前历史输出数据中的最小值和最大值。
与现有技术相比,本发明所达到的有益效果是:
通过光伏发电量的拟选取影响因素,采用基于l-gem的rbf神经网络实现光伏发电量预测,较好地解决了rbf神经网络的泛化问题;提高了系统预测结果的准确性;
基于单点变异与序列倒置变异相结合的新的变异操作,实现全局参数最优;
采用改进头脑风暴算法求得rbf神经网络的权值,并利用局部泛化误差模型求得rbf神经网络的误差界,提高了算法抗早熟能力,又提高了算法的求解精度。
附图说明
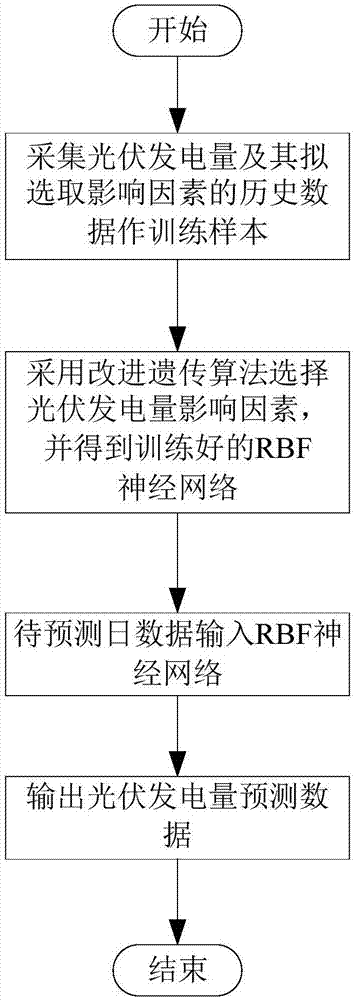
图1是本发明的流程图;
图2是采用改进遗传算法选择光伏发电量影响因素的方法流程图;
图3是采用改进头脑风暴算法计算rbf神经网络权重的方法流程图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
如图1~3所示,本发明包括以下步骤:
步骤(1a):采集光伏发电量的拟选取影响因素的历史数据和其所对应的光伏发电量历史数据,得到训练样本集;
所述光伏发电量的拟选取影响因素包括:待预测日的太阳辐射强度、最高温度、最低温度和电池板温度、风速、相对湿度、天气类型;其所对应的光伏发电量历史数据指:拟选取影响因素的历史数据所对应的待预测日的实际发电量;
步骤(1b):根据步骤(1a)所得光伏发电量的拟选取影响因素的历史数据生成输入向量,以其所对应的光伏发电量的历史数据作为输出向量,并对输入向量和输出向量进行归一化处理,得到训练样本;其具体步骤为:
(1b-i)利用所得光伏发电量的拟选取影响因素的历史数据生成输入向量,以其所对应的光伏发电量的历史数据作为输出向量;
(1b-ii)对步骤(1b-i)所得输入向量和输出数据分别进行归一化处理,其步骤为:
(iia)天气类型划分为晴、多云、阴、小雨(或雪)、中雨(或雪)、大雨(或雪),其对应归一化值分别取1、0.8、0.7、0.5、0.4、0.3,天气类型发生变化的,取变化前后天气类型归一化值的平均值;
(iib)除天气类型外,其他影响因素作为输入向量采用以下归一化公式处理:
(iic)输出向量采用以下归一化公式处理:
其中,ni为输入层节点数;xi为归一化处理前历史输入向量中第i个分量;y为归一化处理前历史输出数据,xi,min,xi,max分别为归一化处理前历史输入向量中第i个分量的最小值和最大值,ymin,ymax分别为归一化处理前历史输出数据中的最小值和最大值,为归一化处理后的历史输入向量中第i个分量,为归一化处理后的历史输出数据。
(1b-iii)保存归一化处理前历史输入向量中各分量的最小值xi,min和最大值xi,max,历史输出数据中的最小值ymin和最大值ymax。
步骤(1c):采用改进遗传算法对步骤(1b)所得训练样本选择光伏发电量影响因素,得到光伏发电量影响因素和训练后的rbf神经网络,其具体步骤为:
(2a)初始化:设置种群大小,按种群大小产生初始种群,初始种群是通过随机分配0和1来创建的。每个染色体是一个二进制数字串,其大小等于训练样本输入向量中的特征数(即光伏发电量的拟选取影响因素的个数)。具有1的特征形成特征子集,rbf神经网络基于该特征子集进行训练;设置最大迭代次数,并置迭代次数为1;
(2b)计算每个染色体的适应度,并计算最佳适应度;
(2c)迭代次数加1,如迭代次数大于最大迭代次数,则转(2h);
(2d)按复制概率进行复制操作;
(2e)按交叉概率对种群中染色体进行交叉操作。其具体步骤是随机产生一个0到1间的数值,如该值小于交叉概率,则从种群中随机选择两条染色体,进行交叉操作。交叉操作采用两点交叉,随机产生两交叉点,两染色体交中两叉点内的基因被交换。
(2f)按变异概率对染色体进行变异操作。其具体步骤是随机产生一个0到1间的数值,如该值小于变异概率,则对当前染色体进行变异操作。其方法是随机产生一个0到1间的数值,如该值小于变异方式选择概率,则采用单点变异,随机选择一变异位,对该基因位进行取反操作;否则则采用序列倒置变异,随机产生两变异点,把两变异点内的基因序列逆序排列。
(2g)转(2b);
(2h)输出最优染色体和最佳适应度。其中最优染色体代表最优的光伏发电量影响因素、最佳适应度代表最优的局部泛化误差模型的误差界。
步骤(1d):采集待预测日光伏发电量影响因素数据生成预测输入向量,进行归一化处理,得到归一化处理后的预测输入向量;归一化处理采用步骤(1b-ii)相同方法;
步骤(1e):将步骤(1d)所述归一化处理后的预测输入向量输入对应的rbf神经网络,得到光伏发电量预测输出数据,预测输出数据经反归一化处理得到待预测日的光伏发电量预测值。
反归一化处理的公式为:
为经rbf神经网络预测得到的反归一化处理前的光伏发电量预测数据,y*为反归一化处理后的光伏发电量预测值,ymin、ymax分别为归一化处理前历史输出数据中的最小值和最大值。
步骤(2b)计算每个染色体的适应度的公式为:
其中,是利用局部泛化误差模型(l_gem)计算得到的第i个rbf神经网络的误差界。rbf神经网络为单输出径向基函数神经网络,可以表达为以下形式:
其中,f(x)是rbf神经网络的真实输出,m代表隐层节点数,由公式求得;n为训练样本输入向量中的特征数;a为1至10之间的常数;wj代表第j个隐层神经元连接到输出层神经元的权重;uj为第j个隐层神经元的中心向量值;vj为第j个隐层神经元的高斯基函数的宽度;x为rbf神经网络的输入;
可由下式求得:
其中:
其中,f(x)为预测器的期望输出;l是训练样本数;和分别代表第i个特征的期望与方差;c为一正常数;q为一给定的正实数;ed[]为数学期望,uji为uj的第i个分量,remp为rbf神经网络输出的均方差;γj、ξj、sj均为中间变量,无实际含义。
其中,rbf神经网络的中心可由k-means聚类算法求得,其具体步骤为:
(3a)从nn个数据对象中任意选择kk个数据对象作为初始聚类中心;
(3b)计算每个数据对象与这些聚类中心的距离,并根据最小距离对相应对象进行划分;
(3c)重新计算每个(有变化)聚类的均值,求得的均值作为聚类中心;
(3d)重复步骤(3b)、步骤(3c),直到所有均值的变化小于给定阈值。
在rbf神经网络的中心已经确定的情况下,可采用下述方法求取rbf神经网络宽度,其步骤为:
(3e)求出所有聚类中心对的距离m1=1,2,...,m,n1=m1+1,m1+2,...,m,且m1≠n1;其中,代表第m1个聚类中心;代表第n1个聚类中心;m表示需要求解的权值数;
(3f)对所得聚类中心对的距离排序,每个rbf神经网络宽度vj取相同的值v,且正比于前p个最小距离的平均值。
在rbf神经网络的中心、宽度已经确定的情况下,可由以下方法求得rbf神经网络的权值,并利用局部泛化误差模型求得rbf神经网络的误差界,其步骤为:
(3h)采用改进头脑风暴算法求得rbf神经网络的权值,并利用局部泛化误差模型求得rbf神经网络的误差界,其具体步骤为:
(4a)随机产生n2个个体,每个个体有m维,每一维代表一rbf神经网络权值;
(4b)用k-means将这n2个个体分为m2类;
(4c)评估这n2个个体;
(4d)将每一类中的个体进行排序,选出每一类内最优的个体作为该类的聚类中心;
(4e)随机产生一个0到1间的数值r1;
如果r1<概率参数p1,
i.随机选择一个聚类中心;
ii.随机产生一个个体代替该聚类中心;
(4f)进行个体的更新
(4f1)随机产生一个0到1间的数值r2;
(4f2)如果r2小于概率参数p2;
i.按概率随机选择一个聚类;
ii.随机产生一个0到1间的数值r3;
iii.如果r3小于概率参数p3,选择聚类中心加上随机扰动产生新个体。
iv.否则,随机产生一个0到1间的数值r4;
v.如果r4小于概率参数p4,从该类中随机选择一个个体,加上随机扰动产生新个体;
vi.否则,从该类中随机选择2个个体,互相融合加上随机扰动产生一个新个体。
(4f3)否则,随机选择两个类产生新个体
i.随机产生一个0到1间的数值r5;
ii.如果r5小于概率参数p5,将两个类的聚类中心互相融合加上随机扰动产生一个新个体;
iii.否则,随机产生一个0到1间的数值r6;
iv.如果r6小于概率参数p6,将第一个类的聚类中心与从第二个类中随机选择的一个个体互相融合加上随机扰动产生一个新个体;
v.否则,分别从两个类中选择一个个体互相融合加上随机扰动产生一个新个体。
(4f4)新产生的个体与当前个体相比,适应值好的个体作为下次迭代的新的个体。
(4g)如果已产生n个新的个体,转步骤(4h),否则转步骤(4f);
(4h)如果达到最大迭代次数则停止,否则转步骤(4b);
(4i)输出最优个体和最佳适应度。
其中,步骤(4c)评估各个体是依据公式(4)中的适应度实现的。
在算法实现过程中涉及到2个个体的融合,融合过程按下式进行:
inew=αi1+(1-α)i2(13)
式中:inew为2个个体融合产生的子代个体;i1和i2表示接受融合操作的2个个体;α为一个0到1之间的随机数,调节2个个体的权重。在新个体产生过程中要加上随机扰动,方式如下:
式中:为选中个体在d维上的值;为新产生个体在d维上的取值;n(μ,σ)为高斯随机函数,均值为μ,方差为σ;ξ1为步长,用于调节随机扰动的取值范围;ξ1取值按下式计算得到:
ξ1=logsig((0.5*max_iteration-current_iteration)/k1)*rand()(15)
式中:logsig()为一个对数s变换函数,max_iteration是最大迭代次数,current_iteration是当前迭代次数,k1为控制logsig()的斜率坡度,rand()产生一个0到1之间的随机数。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。