一种基于托普利兹核偏最小二乘的近重复视频检测方法与流程
本发明属于视频检测领域,尤其涉及一种基于托普利兹核偏最小二乘的近重复视频检测方法。
背景技术
随着互联网的发展,大量的视频相关的应用和服务不断地涌现于互联网上,如视频分享、视频推荐和视频广播等,互联网上充斥着海量的视频数据并呈现高速增长的趋势,在这些海量的视频数据中存在着大量潜在的内容近重复的视频,因此,如何检测和去除这些近重复视频吸引着大量的研究。
现存的近重复视频检测方法主要有三种,分别是:视频级别、帧级别和混合级别的近重复视频检测方法。
首先,有人提出基于监督方法的多特征散列(multifeaturehashing,mfh)方法是一种典型的视频级别的近重复视频检测方法,该方法使用多个图像特征并学习一组散列函数,将视频关键帧映射到hamming空间。该方法的优点是紧凑性强,可以高效地存储和检索,但是由于信息丢失较大,这种方法很容易得出错误的结论。
其次,帧级别的近似重复的视频由各个帧或候选视频序列之间的比较来确定,有局部、全局和时空三种。以尺度不变特征变换(sift)为局部特征,有人提出了穷举匹配来度量相似度。但是,计算成本高。所以后来研究人员提出了将描述符聚合为词袋来降低匹配成本的方法。在全局特征方法中,提出了将帧编码为符号以及利用协方差矩阵来表示帧的方法,尽管这些方法能够实现高效地在线检索,但帧的细节很大程度上丢失了。考虑到时间帧之间的关系,时空方法应运而生,来提高准确性和降低匹配的计算成本,如:将视频序列建模为一组w-shingling以及引入强度标记(imark)来执行序列匹配。这些方法在应对时间变换方面具有优势,但在强烈的空间变换方面较弱。
第三,混合级别的近重复视频方法是应用分层筛选和细化方案来聚类和筛选出近似重复的视频,提出的使用基于模式的索引树对非近似重复的视频进行过滤,并使用基于m-模式的动态编程和时移m-模式相似性对候选视频进行排名的方法。但是,该方法仅在当视频不能清晰地分类为异常或接近重复时具有优势。
技术实现要素:
本发明根据现有技术的不足与缺陷,提出了一种基于托普利兹核偏最小二乘的近重复视频检测方法,目的在于通过关联分析去进行近重复视频检测,以提高准确性,并且通过循环矩阵变换实现快速运算的目标。
本发明采用的技术方案如下:
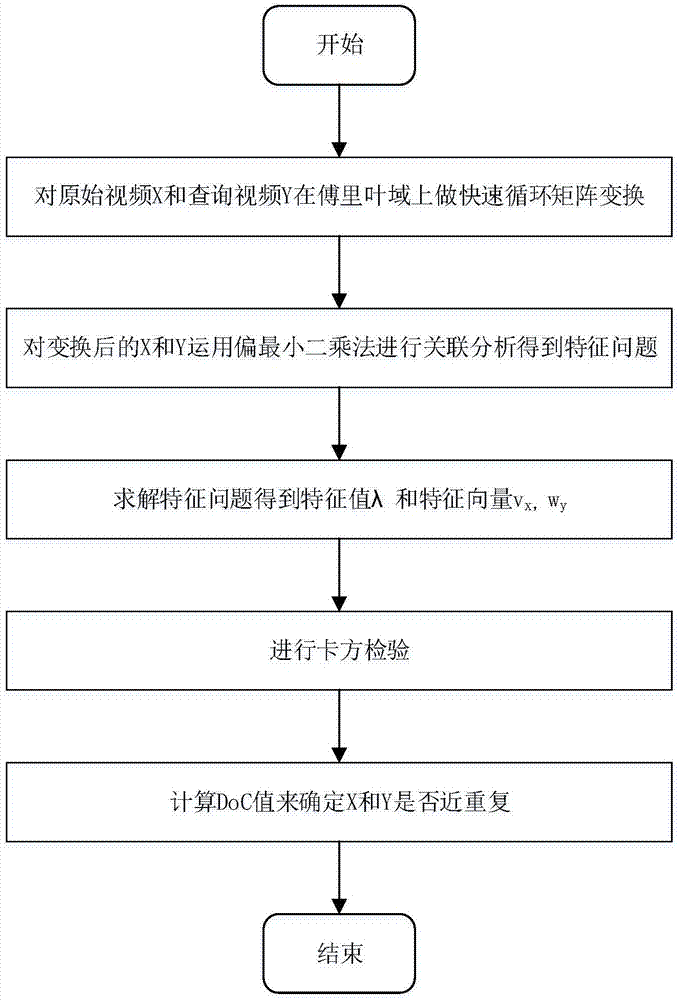
一种基于托普利兹核偏最小二乘的近重复视频检测方法,包括以下步骤:
步骤1,对原始视频x与查询视频y分别在傅里叶域上做快速循环矩阵变换;
步骤2,对变换后的原始视频x与查询视频y运用偏最小二乘法进行关联分析得到特征问题;
步骤3,求解特征问题,得到特征值以及特征向量;
步骤4,使用卡方检验消除统计随机性λ中的值;
步骤5,计算doc值确定原始视频x与查询视频y是否近重复。
进一步,原始视频x={x1,x2,...xi}t、查询视频y={y1,y2,...yi}t分别在傅里叶域上做快速循环矩阵变换,得到
进一步,所述关联分析得到特征问题的方法为:
其中,
其中,
进一步,所述特征值λ=(λ1,...,λj),其中,j=1,2,3…,m,特征值λ介于0~1之间;特征向量
进一步,所述卡方检验的过程为:
其中,i表示第i次迭代,i=1,2,3…,d,π表示乘积,(m-i+1)(m-i+1)表示自由度。χ2的值用于接受或拒绝两组变量无关的无效假设,s表示显著性水平,其中较高水平的显著性表示可以接受虚拟假设的较高可能性,如果零假设对于λj被拒绝,那么在λj下两组变量被认为是显著相关的,迭代执行这个测试从λ1到λm,对于每个λj,如果其s值大于预定义的阈值ε,则将其视为随机相关值,在卡方检验之后,λj中的那些随机相关值被消除。
进一步,所述计算doc值的方法为:
其中,n是原始视频x中的帧数,
进一步,判断原始视频与查询视频是否近重复的方法为:
doc值介于0~1之间,根据设定的阈值,将doc值与阈值进行对比,确定两个视频是否近重复,实现对近重复视频的判断。
本发明的有益效果:
本发明将关联分析与快速算法应用到近重复视频检测方法中,形成基于托普利兹核偏最小二乘的近重复视频检测方法。通过运用核偏最小二乘法进行关联分析,来提高近重复视频检测的准确性,并且通过运用托普利兹矩阵在傅里叶域上进行快速运算,来减少运算消耗,使得资源查找更加快速准确。
附图说明
图1本发明的主流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用于解释本发明,并不用于限定本发明。
为了评估本发明提出的基于托普利兹核偏最小二乘的近重复视频检测方法(kpls_fft)的性能,将此方法与四种现有的近重复视频检测方法进行比较,该四种方法分别是:基于全局特征的方法(bcs)、基于编辑距离的序列匹配方法(se)、自相似带方法(ssbelt)以及基于典型相关分析的检索方法(cca)。
为了测量检测精度,本发明使用precision-recall(pr)曲线。其中,
此外,采用平均精确度(map)来检验近重复视频检测的有效性。为了比较计算效率,采用平均处理时间(mp-time),是用于处理用于产生检索和定位结果的查询的平均时间(单位:秒)。
本发明在windows平台下利用matlabr2016b进行程序的编写及运行,使用的数据集是由香港城市大学和卡内基梅隆大学的研究小组提供的cc_web_video数据集。cc_web_video是一个众所周知的近重复视频检测数据集,总共有12,790段视频,包含398,015个关键帧,如下表1所示:
表1从youtube、谷歌视频和雅虎!视频上收集的24个视频查询(#:视频数量)
如图1,本发明所采用的技术方案具体如下:
步骤1,对原始视频x与查询视频y分别在傅里叶域上做快速循环矩阵变换;原始视频x={x1,x2,...xi}t、查询视频y={y1,y2,...yi}t分别在傅里叶域上做快速循环矩阵变换,i=1,2,3…,d,得到
步骤2,对变换后的原始视频x与查询视频y运用偏最小二乘法进行关联分析;
其中,
其中,
步骤3,求解特征问题,得到特征值以及特征向量,所述特征值λ=(λ1,...,λj),其中,j=1,2,3…,m,特征值λ介于0~1之间;特征向量
步骤4,使用卡方检验消除统计随机性λ中的值,
其中,i表示第i次迭代,i=1,2,3…,d,π表示乘积,(m-i+1)(m-i+1)表示自由度。χ2的值用于接受或拒绝两组变量无关的无效假设。s表示显著性水平,s的阈值ε设置为0.02,其中较高水平的显著性表示可以接受虚拟假设的较高可能性。如果零假设对于λi被拒绝,那么在λi下两组变量被认为是显著相关的。我们迭代执行这个测试从λ1到λm。对于每个λi,如果其s值大于预定义的阈值ε,则将其视为随机相关值。在卡方检验之后,λ中的那些随机相关值被消除。
步骤5,计算doc值确定原始视频x与查询视频y是否近重复,在卡方检验后,通过分析λ中保留的相关值来建立一个度量,组成一个携带所有重要相关性的单值doc,以确定两个视频是否近重复。对于任何两个视频x和y,如果在去除所有不重要的相关值之后更新的相关矢量
其中,n是视频x中的帧数,
表2部分中间结果
基于卡方检验,相关值0.5074和0.4285很可能是偶然出现的,因为它们的显著性水平s值高于默认值ε=0.02。因此,最后的两个相关值不予考虑。对于第一个相关值1.0000,表明视频y中的第一帧和第二帧在视频x中具有接近的帧。对于相关性值0.9777,显然表明视频y中的第三帧与视频x中的帧接近复制。类似地,根据相关值0.8345和0.6696,我们还可以确定视频y中的第五和第六帧在视频x中具有近似重复的帧。
以上实施例仅用于说明本发明的设计思想和特点,其目的在于使本领域内的技术人员能够了解本发明的内容并据以实施,本发明的保护范围不限于上述实施例。所以,凡依据本发明所揭示的原理、设计思路所作的等同变化或修饰,均在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!