一种确定漏点生长函数的方法与流程
本发明属于城市供水管网探漏领域,具体地涉及一种确定漏点生长函数的方法。
背景技术
供水管网漏损问题是困扰供水企业的重要问题,漏损不仅会带来水量和能量损失,甚至会带来地面沉降等次生灾害,影响城市安全。长期以来,对于漏损控制的研究多集中于如何快速发现漏点和降低漏损水量。漏点产生后的发展过程关注较少,这一方面是由于供水管网埋于地下,同时也是由于其影响因素较多,难以实现精确的判断。
一个漏点的发展过程可概化为漏点出现,对应的漏失水量非常小,现有技术无法探测到;之后随着时间的发展,漏点不断扩大,漏失水量逐渐增加,现有技术可以探测到;最后发展扩大为明漏,对应的漏失水量较大,很容易被捡漏工人发现。这是一个十分缓慢、复杂的物理化学变化过程。在漏点发展不同阶段,探漏与维修维护费用、节省水量等不尽相同,从节水和经济角度考虑,应当在较早的阶段发现漏水点并进行维修。然而,过多的对新发生尚未可以探测到的漏点进行探漏,将会提高漏损控制费用,导致漏损控制成本高于节水带来的收益。因此,把漏点的发展过程类比于微生物的生长过程,假设漏点的发展过程遵循生长函数的变化规律,从数学的角度描述漏点发展过程,从而实现对漏点发展过程的模拟,对于提高漏损控制效率,降低管网漏损率具有重要的实际意义。
技术实现要素:
为了节约水资源,降低供水管网漏损率,减少经济损失,本发明旨在提供一种确定管线上漏点生长函数的方法,以便日常管理者确定每一类漏点的生长函数,了解漏点的发展状态,从而提高探漏工作效率,辅助自来水公司做出科学合理的决策。
一种确定漏点生长函数的方法,包括如下步骤:
1)收集管线及管线上漏点的信息;
2)设定漏点生长函数为待确定的增长型曲线;
3)构建真实漏点集合;
4)构建探漏数据集合;
5)1次探漏周期内的探漏过程模拟;
6)确定管线漏点的生长函数方程。
进一步,管线信息包括管径、管材、管长;所述管线上漏点的信息包括所有探漏周期内已探测到的漏点的探漏时间、漏点漏失水量、漏水点原因、探漏周期、听漏范围。
进一步,真实漏点集合是对已探测到的管线漏点按漏失水量从小到大排列后组成的集合,计算其漏点漏失水量的概率分布值,把最大概率分布值所对应的漏失水量作为分界点,小于等于分界点的漏点属于低漏失水量集合,大于分界点的漏点属于高漏失水量集合。
进一步,探漏数据集合由“零点”和“非零点”组成,“零点”个数为所有探漏周期内未探测到管线漏点的探漏次数,对应的数值为0,“非零点”个数为所有探漏周期内已探测到管线漏点的探漏次数,对应的数值为已探测到管线漏点的漏失水量。
进一步,探漏过程模拟为对探漏数据集合进行随机抽样,在每次抽样前都采用经典洗牌算法(knuth-durstenfeldshuffle)将探漏数据集合中的元素随机排序,抽样个数为1次探漏周期内的总探漏次数,计算随机样本中非零点的漏失水量的概率分布值,判断是否满足抽样条件,若满足就停止抽样,若不满足则继续抽样。
进一步,确定管线漏点的生长函数方程步骤为:初始化漏点生长函数方程式中的参数;对探漏数据集合进行随机抽样,计算在不同漏点生长函数参数下对应的漏点均方误差值;以漏点的最小均方误差值为优化目标确定生长函数方程式的参数。
更进一步,在随机抽样过程中,抽到漏点的概率分布值大于真实漏点集合的概率分布值,就认为满足抽样条件,停止抽样,否则继续抽样过程。
进一步,真实漏点漏失水量与在生长函数参数下对应的漏点漏失水量的均方误差,最小的均方误差值对应着最优的生长函数曲线。
进一步,增长型曲线可以是s型、j型、线性。
本发明具有以下优点及突出性的技术效果:
1)本发明提供一种确定漏点生长函数的方法,从微观上解析漏点发展过程,让日常管理者了解漏点的发展状态,从而提高探漏效率,辅助自来水公司做出科学合理的决策,具有重要的现实意义。
2)在确定漏点生长函数方法中,把实际探漏过程抽象为从探漏数据集合中不断随机抽样的过程,通过漏点漏失水量的概率分布值来判断漏点是否被发现。该方法能够较为准确地确定漏点生长函数,并且实用性较强。
3)充分考虑实际情况,利用多源数据来确定漏点生长函数,有效地提高了该方法的准确性。
附图说明
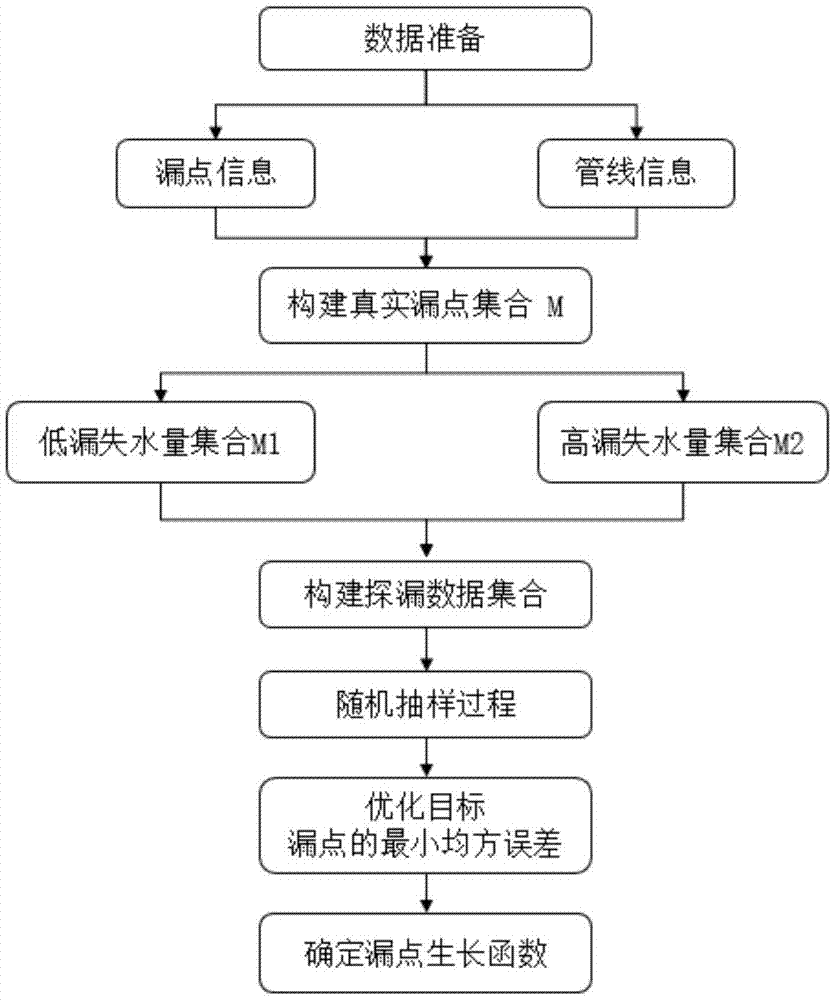
图1示出了本发明确定漏点生长函数的流程图;
图2示出了10年内dn100铸铁管线上漏点漏失水量的概率分布图;
图3示出了利用本发明方法确定的漏点“s型”生长函数的曲线图;
图4示出了利用本发明方法确定的漏点“s型”生长函数计算漏点的结果与实际测量结果的对比图;
图5示出了利用本发明方法确定的漏点“j型”生长函数曲线图;
图6示出了利用本发明方法确定的漏点“j型”生长函数计算漏点的结果与实际测量结果的对比图;
图7示出了利用本发明方法确定的漏点线性生长函数曲线图;
图8示出了利用本发明方法确定的漏点线性生长函数计算漏点的结果与实际测量结果的对比图。
附图标记说明:1—初始漏点,2—极值漏点
具体实施方式
为更好的理解和实施本发明,下面将结合附图和具体实施例对本发明进行详细阐述。应当理解的是,虽然对本发明的实施方式进行了说明,但是显然,本发明不限定于上述实施方式,可以在不脱离其主旨的范围内进行各种变形。
如图1示出了本发明确定漏点生长函数的流程图,包括:
1.前期的数据准备:
1)数据收集:在城市供水管网的维修与暗漏数据库中,收集发生暗漏的漏点信息,包括探漏时间、漏点漏失水量、漏水点原因、探漏周期、听漏范围;对应的管线信息,包括管径、管材、管长。
2)数据预处理:按不同的管材和管径对漏点进行分类,剔除那些由于非自然原因而造成的漏点,如外荷载作用在管道上。
在相同的管材和管径下,管长为h米,探漏周期为t个月,探漏工人平均每h米听漏一次。在t年内,未探测到管线漏点的探漏次数为m,已探测到管线漏点的探漏次数为n(即检测到n个漏点),每个探漏周期内探漏h/h次。
2.设漏点生长函数为f(t),f(t)表示漏点漏失水量,t表示漏点发展时间。
3.构建真实漏点集合,并分为低漏失水量集合和高漏失水量集合两部分:
1)把t年内探测到的n个漏点按漏失水量从小到大排列,记为真实漏点集合m={q1,…,qn}。计算集合m中漏点漏失水量的概率分布值p(qi),其中最大的概率分布值为pmax(ql),对应集合m中第l个漏点,其漏失水量为ql。
2)把集合m分为低漏失水量集合m1和高漏失水量集合m2两部分,集合m1={q1,…,ql},集合m2={ql+1,…,qn}。
4.构建探漏数据集合:探漏数据集合由“零点”和“非零点”组成。“零点”个数为m-n,对应的数值为0,“非零点”个数为n,对应的数值为已经检测到的n个漏点的漏失水量qi(i=1,2,…n)。
5.漏点的随机抽样过程:
从集合m中按漏点漏失水量从小到大依次选出目标漏点,对应的漏失水量为qi,qi∈m。对于每一个漏点,从探漏数据集合中反复随机抽样,每一次抽样模拟一个探漏周期,在每次抽样前都采用经典洗牌算法(knuth-durstenfeldshuffle)将探漏数据集合中的元素随机排序,具体步骤如下:
1)在第k次随机抽样过程中,从探漏数据集合中抽取h/h个漏点,其中有d个“非零点”,记为集合f={qj,j=1,2…d}。计算集合f中漏点漏失水量的概率分布值p(qj)。
2)目标漏点按生长函数f(t)发展,它的漏失水量为f(k),若f(k)∈f,计算目标漏点对应的概率分布值p(f(k));若
3)若p(f(k))或p(f(k)′)大于p(qi),即认为漏点a被发现;否则,继续重复步骤1)至步骤3)。
4)计算目标漏点对应的误差平方值(f(k)-qi)2。
6、优化目标为漏点的均方误差,最小的均方误差值对应着最优的生长函数。
1)集合m中所有的目标漏点都会进行随机抽样过程,计算所有漏点的均方误差值φ:
2)不同生长函数对应不同的均方误差值,选取均方误差值最小的生长函数作为最优解。
7.采用均方误差和平均绝对误差来评价确定漏点生长函数方法的效果:
1)
2)
式中,f(k)i为第i个漏点按漏点发展模型被发现时的漏失水量,qi为第i个漏点的真实漏失水量。
均方误差是反映估计量与被估计量之间差异程度的一种度量,平均绝对误差是所有单个观测值与算术平均值的偏差的绝对值的平均。两个指标越小越能说明漏点函数计算方法的精度高,该方法可以较为准确地确定漏点生长函数。
下面以一个实施例来本发明的方法。在以下实施方式中,利用python3.6软件作为模型的开发平台。本实施例以dn100的铸铁管为例。
1、前期的数据准备。
1)数据收集:在某市供水管网的维修与暗漏数据库中,收集2007年至2016年某市发生暗漏的漏点信息,包括探漏时间、漏点漏失水量、漏水点原因、探漏周期、听漏范围;以及对应的管线信息,包括管径、管材、管长。
2)数据预处理:按不同的管材和管径对漏点进行分类,本实施例以dn100铸铁管为例,剔除那些由于非自然原因而造成的漏损点,如外荷载作用在管道上。
某市dn100的铸铁管管长1009.3千米,探漏周期为3个月,探漏工人平均每100米听漏一次。在10年内,未探测到管线漏点的探漏次数为402053次,已探测到管线漏点的探漏次数为1067次(即检测到1067个漏点),每个探漏周期内探漏10093次。
2.当漏点生长函数为“s型”逻辑函数f(x)=a/(1+eb-cx),f(x)表示漏点漏失水量,x表示漏点发展时间,初始化参数a、b、c,其中a=85;b=[0,10],间隔0.1;c=[0,1],间隔0.1。
3.构建真实漏点集合,并分为低漏失水量集合和高漏失水量集合两部分:
1)10年内探测到的1067个漏点按漏失水量从小到大排列,记为真实漏点集合m={q1,…,q1067}。图2所示为集合m中漏点漏失水量的概率分布图,每个漏点对应的概率分布值为p(qi)。其中最大的概率分布值为0.077,对应集合m中第345个漏点,其漏失水量为5.23m3/h,漏点发展时间为xl=c-1×[b+ln(5.23/(a-5.23))]。
2)把集合m分为低漏失水量集合m1和高漏失水量集合m2两部分,集合m1={q1,…,q345},集合m2={q346,…,q1067}。
4.构建探漏数据集合:探漏数据集合由“零点”和“非零点”组成。“零点”有402653个,对应的数值为0,“非零点”有1067个,对应的数值为已经检测到的1067个漏点的漏失水量qi(i=1,2,…1067)。
5.漏点的随机抽样过程:
从集合m中按漏点漏失水量从小到大依次选出目标漏点,对应的漏失水量为qi,qi∈m。对于每一个漏点,从探漏数据集合中反复随机抽样,每一次抽样模拟一个探漏周期,在每次抽样前都采用经典洗牌算法(knuth-durstenfeldshuffle)将探漏数据集合中的元素随机排序,具体步骤如下:
1)在第k次随机抽样过程中,从探漏数据集合中抽取h/h个漏点,其中有d个“非零点”,记为集合f={qj,j=1,2…d}。计算集合f中漏点漏失水量的概率分布值p(qj)。
2)目标漏点按生长函数f(x)发展,它的漏失水量为f(k),若f(k)∈f,计算目标漏点对应的概率分布值p(f(k));若
3)若p(f(k))或p(f(k)′)大于p(qi),即认为漏点a被发现;否则,继续重复步骤1)至步骤3)。
4)计算目标漏点对应的误差平方值(f(k)-qi)2。
6.优化目标为漏点的均方误差,最小的均方误差值对应着最优的生长函数。
1)集合m中所有的目标漏点都会进行随机抽样过程,计算所有漏点的均方误差值φ:
2)不同生长函数对应不同的均方误差值,在1000个均方误差值中,最小的φ值为2.78(m3/h)2,对应的系数b=5,c=0.3,对应的漏点生长函数为f(x)=85/(1+e5-0.3x)。
图3所示为dn100铸铁管线上漏点的“s型”生长曲线,图中1为初始漏点(0.77m3/h),现有技术刚刚可以发现的漏点,为漏点漏失水量的最小值,2为极值漏点(84.5m3/h),为漏点漏失水量的最大值,一般很少有漏点能够发展到该阶段而不被发现。当漏点漏失水量为10m3/h时,漏点发展时间为885天,所以对于dn100的铸铁管线而言,大部分漏点在2.5年以内就可以被发现。
7.采用均方误差和平均绝对误差来评价漏点生长函数计算方法的效果,1067个真实漏点按漏点生长函数计算方法被检测到时的漏失水量与真实漏失水量之间的均方误差为2.78(m3/h)2,平均绝对误差为0.05m3/h。二者的数值越小,表示该计算方法越准确,所以漏点生长函数为f(x)=85/(1+e5-0.3x)。
图4示出了利用本发明方法确定的漏点“s型”生长函数计算漏点的结果与实际测量结果的对比图。对1067个真实漏点按漏失水量从小到大编号,横坐标为1067个漏点的编号,纵坐标为漏点漏失水量。实线对应真实漏点的漏失水量,虚线对应1067个漏点按生长函数计算方法被发现时的漏失水量,两条曲线的变化趋势基本一致。
以上结果说明,“s型”逻辑函数f(x)=a/(1+eb-cx)可以较为准确的刻画管线上漏点的发展变化规律,用本发明的方法所确定的漏点生长函数来计算漏点的方法是合理的,并且该方法实用性较强。
当漏点生长函数为“j型”指数函数f(x)=aebx,f(x)表示漏点漏失水量,x表示步骤和“s型”逻辑函数的计算步骤相同。
图5所示为dn200铸铁管线上漏点的“j型”生长曲线,图中1为初始漏点(0.5m3/h),现有技术刚刚可以发现的漏点,为漏点漏失水量的最小值,2为极值漏点(96m3/h),为漏点漏失水量的最大值,一般很少有漏点能够发展到该阶段而不被发现。
采用均方误差和平均绝对误差来评价漏点生长函数计算方法的效果,443个真实漏点按漏点生长函数计算方法被检测到时的漏失水量与真实漏失水量之间的均方误差为4.15(m3/h)2,平均绝对误差为0.1m3/h。二者的数值越小,表示该计算方法越准确,所以漏点生长函数为f(x)=0.5e0.3x。
图6示出了利用本发明方法确定的漏点“j型”生长函数计算漏点的结果与实际测量结果的对比图。对443个真实漏点按漏失水量从小到大编号,横坐标为443个漏点的编号,纵坐标为漏点漏失水量。实线对应真实漏点的漏失水量,虚线对应443个漏点按生长函数计算方法被发现时的漏失水量,两条曲线的变化趋势基本一致。
当漏点生长函数为线性函数f(x)=ax+b,f(x)表示漏点漏失水量,x表示漏点发展时间,初始化参数a、b,其中a=[0.1,5],间隔0.1;b=[0,1],间隔0.1。收集dn300铸铁管线上的漏点信息,用线性函数描述漏点的生长过程,具体计算步骤和“s型”逻辑函数的计算步骤相同。
图7所示为dn300铸铁管线上漏点的线性生长曲线,图中1为初始漏点(0.5m3/h),现有技术刚刚可以发现的漏点,为漏点漏失水量的最小值,2为极值漏点(91.5m3/h),为漏点漏失水量的最大值,一般很少有漏点能够发展到该阶段而不被发现。
采用均方误差和平均绝对误差来评价漏点生长函数计算方法的效果,207个真实漏点按漏点生长函数计算方法被检测到时的漏失水量与真实漏失水量之间的均方误差为4.80(m3/h)2,平均绝对误差为0.14m3/h。二者的数值越小,表示该计算方法越准确,所以漏点生长函数为f(x)=2x+0.5。
图8示出了利用本发明方法确定的漏点线性生长函数计算漏点的结果与实际测量结果的对比图。对207个真实漏点按漏失水量从小到大编号,横坐标为207个漏点的编号,纵坐标为漏点漏失水量。实线对应真实漏点的漏失水量,虚线对应207个漏点按生长函数计算方法被发现时的漏失水量,两条曲线的变化趋势基本一致。
本发明弥补了关于供水管线上漏点发展变化的研究内容,从微观的角度解析了漏点的发展过程,指导自来水公司优化探漏工作策略,做出科学合理的决策提供了一种新的思路。
- 还没有人留言评论。精彩留言会获得点赞!