基于检测和识别网络架构的细粒度图像分类方法与流程
本发明涉及一种图像分类技术,特别涉及一种基于检测和识别网络架构的细粒度图像分类方法。
背景技术
图像分类是计算机视觉领域的一个经典研究课题。图像分类主要包括粗粒度图像分类和细粒度图像分类。细粒度图像分类,即子类的分类问题,是对一个大类别进行更加细致的子类划分,如区分鸟的种类、车的品牌款式、狗的品种等,因为图像采集中存在姿态、视角、光照、遮挡、背景干扰等差异因素,所以细粒度分类时往往具有细微的类间差异和较大的类内差异,和普通的图像分类相比,细粒度图像分类难度更大。
早期基于人工特征的细粒度图像分类算法,由于人工特征选择过程繁琐,表述能力有限,因此分类效果不佳。随着近年来深度学习的兴起,从卷积神经网络中自动获得的特征,比人工特征有更强大的描述能力,按照模型训练时是否需要人工标注信息,基于深度学习的细粒度图像分类算法可分为强监督和弱监督两类,强监督的细粒度图像分类在模型训练时不仅需要图像的类别标签,还需要图像标注框,局部区域位置等人工标注信息,然而不论是强监督或弱监督的细粒度图像分类算法,大多数细粒度图像分类算法的思路都是先找到前景对象和图像中的局部区域,之后利用卷积神经网络对这些区域分别提取特征,并将这些特征进行一定处理,以此完成分类器的训练和预测。zhang等提出的part-basedr-cnn算法,该算法先采用r-cnn算法对图像进行检测,找到局部区域,再分别对每一块区域提取卷积特征,将不同区域的特征连接起来,构成一维特征表示,最后用svm训练分类。然而,其利用的选择性搜索算法会产生大量无关的候选区域,造成运算上的浪费。branson等提出的姿态归一化cnn算法,它通过原型对图像进行姿态对齐操作,为构造一个更加具区分度的特征,对不同的局部区域提取不同网络层的特征,但是,该算法利用dpm算法对关键点进行检测与实际标注的关键点信息差距较大。xiao等提出两级注意力算法,其仅使用类别标签,算法模型分为三个处理阶段,分别是预处理、对象级和局部级三个不同的子模型,但两级注意力模型利用聚类算法得到局部区域,使准确度十分有限。然而,以上算法都只是利用卷积神经网络提取特征。前景对象、局部区域等的特征提取、特征融合、模型训练,各步骤之间的处理是一个分散的过程,不是一个整体的系统,未从整体上进行端到端的训练优化,这大大增加了细粒度图像分类的难度和复杂度。
技术实现要素:
本发明是针对目前细粒度图像分类的问题,提出了一种基于检测和识别网络架构的细粒度图像分类方法,使用yolov2算法快速检测物体,消除背景干扰和无关信息对分类结果的影响,将检测到的待识别物体采用双线性卷积神经网络的细粒度图像分类算法进行分类。
本发明的技术方案为:一种基于检测和识别网络架构的细粒度图像分类方法,具体包括如下步骤:
1)采用yolov2目标检测算法预训练的模型对标准细粒度图像数据集进行处理,得到数据集中每一张图片中的判别性区域,得到了处理后的目标图像数据集;
2)将处理后的目标图像数据集输入双线性卷积神经网络进行训练与分类,得到细粒度图像分类结果;
双线性卷积神经网络结构由一个四元组β=(fa,fb,p,c)组成,其中,fa和fb是2个基于卷积神经网络的特征提取函数,分别对应cnn网络a和cnn网络b,p是一个池化函数,c则是分类函数;双线性卷积神经网络参数的训练通过分类损失函数r的梯度反向传播来实现;如果cnn网络a和cnn网络b两个网络的输出矩阵a和b,其大小分别为k×m和k×n,则双线性特征为x=φ(h)=atb,大小为m×n;令dr/dx表示分类损失函数r对x的梯度,由梯度的链式法则,有:
计算得到特征a和b的梯度,则整个网络进行端到端的训练。
所述步骤1)中yolov2目标检测算法首先把输入图像划分成s×s的栅格,经过yolov2检测,对每个格子都预测q个边界框,其中每个边界框都包含5个预测值:中心点横坐标tx、纵坐标ty,边界框的宽tw,高th,及置信值to,利用先验框来预测边界框,其采用k-means的方式对训练集图片中的真实标注框做聚类,可以找到合适的先验框;
在实现k-means聚类时,通过iou定义,使得误差和真实标注框box的大小无关,最终距离测度函数公式为:
d(box,centrd)=1-iou(box,centrd)
其中:centrd表示聚类中心;box表示真实标注框;iou(box,centrd)表示聚类中心框和标注框的交并比;
表示预测的边界框的准确度,公式表示为:
其中:bgr表示真实标注框的面积,bpr表示预测边界框的面积;
通过对预测的边界框进行限制,相应的预测为:
bx=σ(tx)+cx
by=σ(ty)+cy
c=σ(to)
σ为logistic激活函数,tx、ty经过logistic激活函数后范围在0到1之间,cx和cy表示网格相对于图像左上角横纵坐标的偏移量,pw和ph表示先验框的宽和高;σ(to)为置信值;最终采用以下的损失函数完成对模型的训练:
其中,s2表示将图像划分的栅格数,q表示每个栅格预测的边界框个数,
所述步骤2)中双线性卷积神经网络运行步骤:
特征提取函数fa和fb的输入为接收一个位置l∈l的图像块h,h∈h,其中,h表示整张输入图像,l为输入图像的位置区域表示,h表示输入图像上的一个图像块,l表示图像块的位置区域;特征提取函数输出k×d大小的特征图,通过矩阵外积将每一个位置点的特征输出汇聚,也就是在l区域fa和fb的双线性特征的融合,公式如下:
bilinear(l,h,fa,fb)=fa(l,h)tfb(l,h)l∈l,h∈h
其中fa和fb必须具有相同的特征维度k,k的值取决于具体的网络;
池化函数p将所有位置的双线性特征汇聚以获得图像的全局特征φ(i),表示如下:
在池化过程中,由于特征的位置信息被忽略,因此双线性特征φ(i)是一个无序的特征表示;如果fa和fb提取的特征维度分别为k×m和k×n,则φ(i)的大小为m×n的矩阵;
令x表示φ(h),并对其进行带符号的开平方根及l2归一化处理,公式如下:
z=y/||y||2
经上述处理后,再将其转化为一个mn×1的列向量,作为最终的双线性特征向量,最后,通过softmax网络层进行分类。
本发明的有益效果在于:本发明基于检测和识别网络架构的细粒度图像分类方法,通过yolov2目标检测算法,能够滤除大部分对细粒度图像分类没有贡献的区域,使得双线性卷积神经网络能够提取到更多对分类有用的细粒度特征。不同于目前绝大多数细粒度图像分类算法,双线性卷积神经网络是一个整体的系统,能够完成端到端的训练,且在训练过程中只依赖于类别标注信息,而无需借助其他的人工标注信息,这不仅大大增强了算法的实用性,而且提高了模型的识别率。
附图说明
图1为本发明系统框架图;
图2为本发明双线性卷积神经网络梯度流图。
具体实施方式
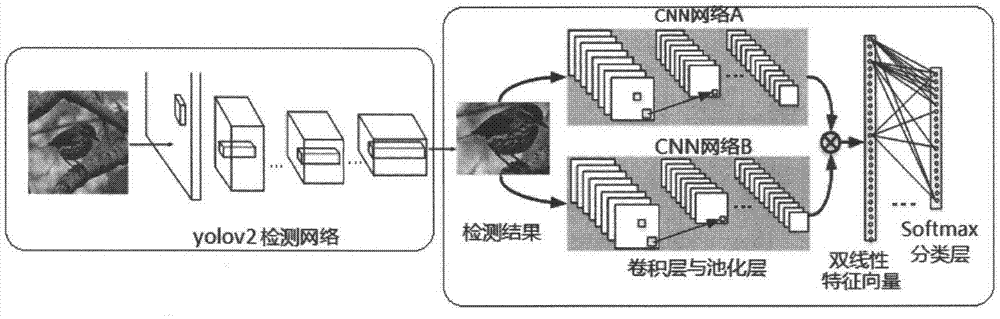
基于检测(yolov2目标检测算法)和识别(双线性cnn图像分类算法)架构的细粒度图像分类方法,框架如图1所示,前部分为yolov2检测,后部分为双线性卷积神经网络。
本发明的实施案例步骤如下:
第一步,采用yolov2目标检测算法预训练的模型对标准细粒度图像数据集进行处理,得到数据集中每一张图片中的判别性区域,得到了处理后的目标图像数据集:
yolov2目标检测算法是对yolov1算法的进一步改进。yolov2算法首先把输入图像划分成s×s的栅格,经过yolov2检测栅格网络,对每个格子都预测q个边界框,其中每个边界框都包含5个预测值:中心点横坐标tx、纵坐标ty,边界框的宽tw,高th,及置信值to。由于模型在训练过程中会不断地学习调整预测的边界框的宽高维度,但是,如果一开始就选择有代表性的先验框维度,则模型对边界框的预测就更加准确。因此,yolov2算法利用先验框来预测边界框,其采用k-means的方式对训练集图片中的真实标注框做聚类,可以找到合适的先验框。在实现k-means聚类时,如果选择欧氏距离作为测度函数,尺寸较大的边界框会产生比较小的边界框更多的错误,通过iou定义,使得误差和box的大小无关,最终距离测度函数公式为:
d(box,centrd)=1-iou(box,centrd)
其中:centrd表示聚类中心,box表示真实的标注框(这个标注框是制作数据集是人工标定的)。iou(box,centrd)表示聚类中心框和标注框的交并比。
表示预测的边界框的准确度,公式表示为:
其中:bgr表示真实标注框的面积,bpr表示预测边界框的面积。最后得到的先验框的形状大多为细高型,短宽的居少。为平衡模型复杂度和召回率,选择先验框的个数为5。yolov1算法直接用全连接层对边界框进行预测。而yolov2算法借鉴faster-rcnn算法使用先验框对检测网络的最后的输出特征图上直接预测,而先验框的引入会导致模型在训练过程中不稳定,尤其在早期迭代过程中。因此通过对预测的边界框进行限制,可以使模型参数更容易学习,模型会更加稳定,因此相应的预测为:
bx=σ(tx)+cx
by=σ(ty)+cy
c=σ(to)
σ为logistic激活函数,tx、ty经过logistic激活函数后范围在0到1之间,cx和cy这表示网格相对于图像左上角横纵坐标的偏移量,pw和ph表示先验框的宽和高。σ(to)为置信值。最终采用以下的损失函数完成对模型的训练:
其中,s2表示将图像划分的栅格数,q表示每个栅格预测的边界框个数,
第二步,将yolov2目标检测算法得到的检测结果(目标图像)输入双线性卷积神经网络进行训练与分类:
双线性卷积神经网络如图1右框所示:双线性卷积神经网络结构由一个四元组β=(fa,fb,p,c)组成。其中,fa和fb是2个基于卷积神经网络的特征提取函数,分别对应于图1中的cnn网络a和cnn网络b,p是一个池化函数,c则是分类函数。特征提取函数fa和fb可以看成它们接收一个位置l∈l的图像块h,h∈h,其中,h表示整张输入图像,l为输入图像的位置区域表示,h表示输入图像上的一个图像块,l表示图像块的位置区域。特征提取函数输出k×d大小的特征图,通过矩阵外积将每一个位置点的特征输出汇聚,也就是在l区域fa和fb的双线性特征的融合,公式如下:
bilinear(l,h,fa,fb)=fa(l,h)tfb(l,h)l∈l,h∈h
其中fa和fb必须具有相同的特征维度k,k的值取决于具体的网络。池化函数p的作用则是将所有位置的双线性特征汇聚以获得图像的全局特征φ(i),表示如下:
在池化过程中,由于特征的位置信息被忽略,因此双线性特征φ(i)是一个无序的特征表示。如果fa和fb提取的特征维度分别为k×m和k×n,则φ(i)的大小为m×n的矩阵,令x表示φ(h),并对其进行带符号的开平方根及l2归一化处理,公式如下:
z=y/||y||2
经上述处理后,再将其转化为一个mn×1的列向量,作为最终的双线性特征向量。最后,通过softmax网络层进行分类。
双线性卷积神经网络结构是一个有向无环图。其参数的训练可通过分类损失函数r的梯度反向传播来实现,如交叉熵。双线性形式简化了梯度运算。如果两个网络的输出矩阵a和b,其大小分别为k×m和k×n,则双线性特征为x=φ(h)=atb,大小为m×n。令dr/dx表示分类损失函数r对x的梯度,由梯度的链式法则,有:
计算得到特征a和b的梯度,则整个网络可以进行端到端的训练,梯度更新如图2。其他部分的训练和常规的cnns网络相同。
- 还没有人留言评论。精彩留言会获得点赞!