从下采样的低分辨率LIDAR3-D点云和摄像机图像生成高分辨率3-D点云的制作方法
本公开的实施方式总体涉及操作自动驾驶车辆。更具体地,本公开的实施方式涉及从下采样的低分辨率激光雷达(lidar)3-d点云和摄像机图像生成高分辨率三维(3-d)点云。
背景技术:
以自动驾驶模式运行(例如,无人驾驶)的车辆可以将乘员、尤其是驾驶员从一些驾驶相关的职责中解放出来。当以自动驾驶模式运行时,车辆可以使用车载传感器导航到各个位置,从而允许车辆在最少人机交互的情况下或在没有任何乘客的一些情况下行驶。
高分辨率lidar数据对实现用于自动驾驶车辆(adv)应用(诸如,对象分割、检测、跟踪和分类)的实时3-d场景重建很重要。然而,高分辨率的lidar设备通常是昂贵的,且未必能够获得。
技术实现要素:
在本公开的一方面,提供了一种用于操作自动驾驶车辆的计算机实施的方法,所述方法包括:
接收由第一摄像机捕捉的第一图像,所述第一图像捕捉所述自动驾驶车辆的驾驶环境的一部分;
接收第二图像,所述第二图像表示由激光雷达装置产生的、与所述驾驶环境的一部分相对应的第一点云的第一深度图;
以预定的比例因子对所述第二图像下采样,直到所述第二图像的分辨率达到预定的阈值;以及
通过对所述第一图像和下采样的第二图像应用卷积神经网络模型来生成第二深度图,所述第二深度图比所述第一深度图具有更高的分辨率,其中,所述第二深度图表示感知所述自动驾驶车辆周围的所述驾驶环境的第二点云。
在本公开的另一方面,提供了一种存储有指令的非暂时性机器可读介质,所述指令在由处理器执行时致使所述处理器执行操作,所述操作包括:
接收由第一摄像机捕捉的第一图像,所述第一图像捕捉所述自动驾驶车辆的驾驶环境的一部分;
接收第二图像,所述第二图像表示由激光雷达装置产生的、与所述驾驶环境的一部分相对应的第一点云的第一深度图;
以预定的比例因子对所述第二图像下采样,直到所述第二图像的分辨率达到预定的阈值;以及
通过对所述第一图像和下采样的第二图像应用卷积神经网络模型来生成第二深度图,所述第二深度图比所述第一深度图具有更高的分辨率,其中,所述第二深度图表示感知所述自动驾驶车辆周围的所述驾驶环境的第二点云。
在本公开的再一方面,提供了一种数据处理系统,包括:
处理器;以及
存储器,所述存储器联接至所述处理器,以存储指令,所述指令在由所述处理器执行时致使所述处理器执行操作,所述操作包括:
接收由第一摄像机捕捉的第一图像,所述第一图像捕捉所述自动驾驶车辆的驾驶环境的一部分;
接收第二图像,所述第二图像表示由激光雷达装置产生的、与所述驾驶环境的一部分相对应的第一点云的第一深度图;
以预定的比例因子对所述第二图像下采样,直到所述第二图像的分辨率达到预定的阈值;以及
通过对所述第一图像和下采样的第二图像应用卷积神经网络模型来生成第二深度图,所述第二深度图比所述第一深度图具有更高的分辨率,其中,所述第二深度图表示感知所述自动驾驶
车辆周围的所述驾驶环境的第二点云。
附图说明
本公开的实施方式在附图的各图中以举例而非限制的方式示出,附图中的相同参考数字指示相似元件。
图1是示出根据一个实施方式的网络化系统的框图。
图2是示出根据一个实施方式的自动驾驶车辆的示例的框图。
图3是示出根据一个实施方式的与自动驾驶车辆一起使用的感知与规划系统的示例的框图。
图4是示出根据一个实施方式的与自动驾驶车辆一起使用的高分辨率点云模块的示例的框图。
图5a是示出根据一个实施方式的示例性adv的图示。
图5b和图5c示出根据一些实施方式的与自动驾驶车辆一起使用的lidar/全景摄像机配置的顶视图和侧视图。
图5d至图5f示出根据一些实施方式的单色/立体全景摄像机配置的示例。
图6a和图6b分别示出根据一个实施方式的推理模式和训练模式的流程图。
图6c和图6d分别示出根据一个实施方式的推理模式和训练模式的流程图。
图7a和图7b是示出根据一些实施方式的深度图生成的示例的框图。
图8是示出根据一个实施方式的卷积神经网络模型的收缩层和扩张层的图示。
图9a和图9b是示出根据一些实施方式的高分辨率深度图生成的示例的框图。
图10是示出根据一个实施方式的方法的流程图。
图11a和图11b是示出根据一些实施方式的深度图生成的示例的框图。
图12是示出根据一个实施方式的卷积神经网络模型的收缩(例如,编码器/卷积)层和扩张(例如,解码器/反卷积(deconvolutional))层的图示。
图13是示出根据一个实施方式的方法的流程图。
图14a和图14b是示出根据一些实施方式的深度图生成的示例的框图。
图15是示出根据一个实施方式的方法的流程图。
图16是示出根据一个实施方式的数据处理系统的框图。
具体实施方式
将参考以下所讨论的细节来描述本公开的各种实施方式和方面,附图将示出所述各种实施方式。下列描述和附图是对本公开的说明,而不应当解释为限制本公开。描述了许多特定细节以提供对本公开的各种实施方式的全面理解。然而,在某些情况下,并未描述众所周知的或常规的细节以提供对本公开的实施方式的简洁讨论。
本说明书中对“一个实施方式“或”实施方式“的提及意味着结合该实施方式所描述的特定特征、结构或特性可以包括在本公开的至少一个实施方式中。短语“在一个实施方式中”在本说明书中各个地方的出现不必全部指同一实施方式。
根据一些实施方式,一种方法或系统从低分辨率的3-d点云和摄像机捕捉的图像生成高分辨率的3-d点云,以操作自动驾驶车辆(adv)。使用机器学习(深度学习)技术将低分辨率lidar单元与校准的多摄像机系统组合起来,以实现功能等效的高分辨率lidar单元,以便生成3-d点云。多摄像机系统设计成输出广角(例如,360度)单色或立体色(例如,红色、绿色和蓝色或rgb)全景图像。然后,使用可靠的数据训练端对端深度神经网络,并基于离线校准参数,应用该端对端深度神经网络,以从包括广角单色或立体全景图像的输入信号实现广角全景深度图,以及从投影到单色或立体全景图像上的低成本lidar实现3-d点云的深度网格。最后,可从广角全景深度图生成高分辨率的3-d点云。相同的过程适用于具有较窄视角(例如,有限范围的角度)立体摄像机和较窄视角低分辨率lidar的配置。
根据一个方面,该系统接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。该系统接收第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。系统以预定的比例因子对第二图像下采样,直到第二图像的分辨率达到预定的阈值。系统通过对第一图像和下采样的第二图像应用卷积神经网络(cnn)模型生成第二深度图,该第二深度图比第一深度图具有更高的分辨率,使得第二深度图表示感知adv周围的驾驶环境的第二点云。
根据另一方面,该系统接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。该系统接收第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。系统以预定的比例因子对第二图像上采样,以匹配第一图像的图像比例。系统通过对第一图像和上采样的第二图像应用卷积神经网络(cnn)模型生成第二深度图,该第二深度图比第一深度图具有更高的分辨率,使得第二深度图表示用于感知adv周围的驾驶环境的第二点云。
根据另一方面,该系统接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。该系统接收第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。该系统通过对第一图像应用卷积神经网络(cnn)模型来确定第二深度图。系统通过对第一图像、第二图像和第二深度图应用条件随机域函数来生成第三深度图,该第三深度图比第一深度图具有更高的分辨率,使得第三深度图表示感知adv周围的驾驶环境的第二点云。
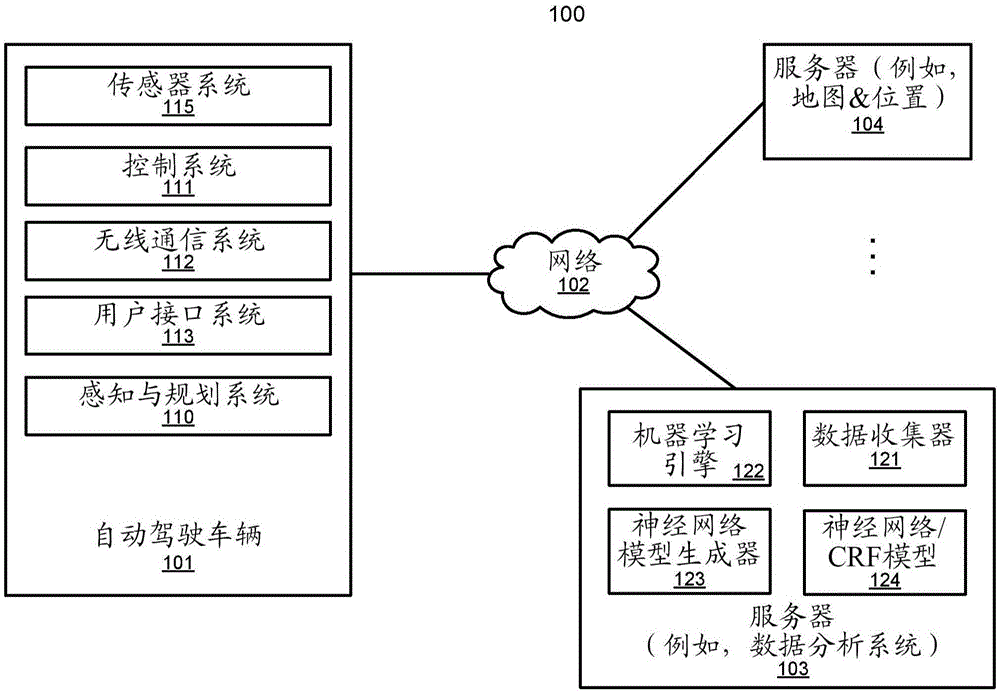
图1是示出根据本公开的一个实施方式的自动驾驶车辆网络配置的框图。参考图1,网络配置100包括可以通过网络102通信地联接到一个或多个服务器103至104的自动驾驶车辆101。尽管示出一个自动驾驶车辆,但多个自动驾驶车辆可以通过网络102联接到彼此和/或联接到服务器103至104。网络102可以是任何类型的网络,例如,有线或无线的局域网(lan)、诸如互联网的广域网(wan)、蜂窝网络、卫星网络或其组合。服务器103至104可以是任何类型的服务器或服务器群集,诸如,网络或云服务器、应用服务器、后端服务器或其组合。服务器103至104可以是数据分析服务器、内容服务器、交通信息服务器、地图和兴趣点(mpoi)服务器或位置服务器等。
自动驾驶车辆是指可以被配置成处于自动驾驶模式下的车辆,在所述自动驾驶模式下车辆在极少或没有来自驾驶员的输入的情况下导航通过环境。这种自动驾驶车辆可以包括传感器系统,所述传感器系统具有被配置成检测与车辆运行环境有关的信息的一个或多个传感器。所述车辆和其相关联的控制器使用所检测的信息来导航通过所述环境。自动驾驶车辆101可以在手动模式下、在全自动驾驶模式下或者在部分自动驾驶模式下运行。
在一个实施方式中,自动驾驶车辆101包括,但不限于,感知与规划系统110、车辆控制系统111、无线通信系统112、用户接口系统113和传感器系统115。自动驾驶车辆101还可以包括普通车辆中包括的某些常用部件,诸如:发动机、车轮、方向盘、变速器等,所述部件可以由车辆控制系统111和/或感知与规划系统110使用多种通信信号和/或命令进行控制,该多种通信信号和/或命令例如,加速信号或命令、减速信号或命令、转向信号或命令、制动信号或命令等。
部件110至115可以经由互连件、总线、网络或其组合通信地联接到彼此。例如,部件110至115可以经由控制器局域网(can)总线通信地联接到彼此。can总线是被设计成允许微控制器和装置在没有主机的应用中与彼此通信的车辆总线标准。它是最初是为汽车内的复用电气布线设计的基于消息的协议,但也用于许多其它环境。
现在参考图2,在一个实施方式中,传感器系统115包括但不限于一个或多个摄像机211、全球定位系统(gps)单元212、惯性测量单元(imu)213、雷达单元214以及光探测和测距(lidar)单元215。gps系统212可以包括收发器,所述收发器可操作以提供关于自动驾驶车辆的位置的信息。imu单元213可以基于惯性加速度来感测自动驾驶车辆的位置和定向变化。雷达单元214可以表示利用无线电信号来感测自动驾驶车辆的本地环境内的对象的系统。在一些实施方式中,除感测对象之外,雷达单元214可以另外感测对象的速度和/或前进方向。lidar单元215可以使用激光来感测自动驾驶车辆所处环境中的对象。除其它系统部件之外,lidar单元215还可以包括一个或多个激光源、激光扫描器以及一个或多个检测器。摄像机211可以包括用来采集自动驾驶车辆周围环境的图像的一个或多个装置。摄像机211可以是静物摄像机和/或视频摄像机。摄像机可以是可机械地移动的,例如,通过将摄像机安装在旋转和/或倾斜平台上。
传感器系统115还可以包括其它传感器,诸如:声纳传感器、红外传感器、转向传感器、油门传感器、制动传感器以及音频传感器(例如,麦克风)。音频传感器可以被配置成从自动驾驶车辆周围的环境中采集声音。转向传感器可以被配置成感测方向盘、车辆的车轮或其组合的转向角度。油门传感器和制动传感器分别感测车辆的油门位置和制动位置。在一些情形下,油门传感器和制动传感器可以集成为集成式油门/制动传感器。
在一个实施方式中,车辆控制系统111包括但不限于转向单元201、油门单元202(也被称为加速单元)和制动单元203。转向单元201用来调整车辆的方向或前进方向。油门单元202用来控制电动机或发动机的速度,电动机或发动机的速度进而控制车辆的速度和加速度。制动单元203通过提供摩擦使车辆的车轮或轮胎减速而使车辆减速。应注意,如图2所示的部件可以以硬件、软件或其组合实施。
回到图1,无线通信系统112允许自动驾驶车辆101与诸如装置、传感器、其它车辆等外部系统之间的通信。例如,无线通信系统112可以与一个或多个装置直接无线通信,或者经由通信网络进行无线通信,诸如,通过网络102与服务器103至104通信。无线通信系统112可以使用任何蜂窝通信网络或无线局域网(wlan),例如,使用wifi,以与另一部件或系统通信。无线通信系统112可以例如使用红外链路、蓝牙等与装置(例如,乘客的移动装置、显示装置、车辆101内的扬声器)直接通信。用户接口系统113可以是在车辆101内实施的外围装置的部分,包括例如键盘、触摸屏显示装置、麦克风和扬声器等。
自动驾驶车辆101的功能中的一些或全部可以由感知与规划系统110控制或管理,尤其当在自动驾驶模式下操作时。感知与规划系统110包括必要的硬件(例如,处理器、存储器、存储设备)和软件(例如,操作系统、规划和路线安排程序),以从传感器系统115、控制系统111、无线通信系统112和/或用户接口系统113接收信息,处理所接收的信息,规划从起始点到目的地点的路线或路径,随后基于规划和控制信息来驾驶车辆101。替代地,感知与规划系统110可以与车辆控制系统111集成在一起。
例如,作为乘客的用户可以例如经由用户接口来指定行程的起始位置和目的地。感知与规划系统110获得行程相关数据。例如,感知与规划系统110可以从mpoi服务器中获得位置和路线信息,所述mpoi服务器可以是服务器103至104的一部分。位置服务器提供位置服务,并且mpoi服务器提供地图服务和某些位置的poi。替代地,此类位置和mpoi信息可以本地高速缓存在感知与规划系统110的永久性存储装置中。
当自动驾驶车辆101沿着路线移动时,感知与规划系统110也可以从交通信息系统或服务器(tis)获得实时交通信息。应注意,服务器103至104可以由第三方实体进行操作。替代地,服务器103至104的功能可以与感知与规划系统110集成在一起。基于实时交通信息、mpoi信息和位置信息以及由传感器系统115检测或感测的实时本地环境数据(例如,障碍物、对象、附近车辆),感知与规划系统110可以规划最佳路线并且根据所规划的路线例如经由控制系统111来驾驶车辆101,以安全且高效到达指定目的地。
服务器103可以是数据分析系统,从而为各种客户执行数据分析服务。在一个实施方式中,数据分析系统103包括数据收集器121、机器学习引擎122、神经网络模型生成器123和神经网络/crf模型124。数据收集器121可从配备有lidar传感器/摄像机的各种车辆收集不同的训练数据,其中,lidar传感器/摄像机通信地联接至服务器103,各种车辆为自动驾驶车辆或由人类驾驶员驾驶的普通车辆。训练数据的示例可以是用于图像识别函数的深度/图像数据,诸如对象分割、检测、跟踪和分类。训练数据可编译成类别并与地面真实标签相关联。在另一实施方式中,数据收集器121可从万维网的在线存档中下载训练数据集。
基于由数据收集器收集的训练数据,机器学习引擎122可出于各种目的生成或训练一组神经网络/crf模型124。例如,机器学习引擎122可使用训练数据对作为神经网络/crf模型124的一部分的cnn模型执行端对端训练,其中,训练数据诸如为rgb图像/3-d低分辨率点云和3-d高分辨率点云输入/输出对。
cnn是一种前馈人工神经网络(ann),在该前馈人工神经网络(ann)中,它的神经元之间的连接模式是受动物视觉皮质的组织的启发。单个的皮质神经元对被称为“接受域”的有限空间区域中的刺激做出响应。不同神经元的接收域部分地重叠,使得它们的视野平铺。单个神经元对其接收域内的刺激的响应可通过卷积运算进行数学近似。深度cnn是具有多个内层的cnn。神经网络的“内层”是指在神经网络的输入层与输出层之间的层。
ann是基于大量神经单元或神经元的计算方法,对具有由轴突连接的大量神经元的生物大脑松散地建模。每个神经元均与许多其它神经元相连接,轴突或连接可通过学习或训练增强或抑制它们对所连接的神经元的激活状态的作用。每个单独的神经元均可具有将其所有输入的值组合在一起的函数。每个连接上和单元本身上都可能有阈值函数或限制函数:使得信号在传播到其它神经元之前必须超过限制。这些系统进行自学习和训练,而不是明确地程序化。
“训练”cnn涉及对cnn的输入层进行迭代地输入,并将期望的输出与cnn的输出层处的实际输出进行比较,以计算误差项。这些误差项用于调节cnn的隐蔽层中的权重和偏差,使得下一次输出值将更接近“正确”值。每个层的输入的分布会减慢训练(即,收敛需要较低的训练速率),并且需要仔细的参数初始化,即,将内层的激活的初始权重和偏差设置为特定的范围,以便进行收敛。“收敛”是指当误差项达到最小值时。
一旦cnn模型进行了训练,该模型可上载到诸如adv101的adv中,以生成实时高分辨率3-d点云。高分辨率3-d点云可通过从摄像机捕捉的光学图像和由低成本radar和/或lidar单元捕捉的低分辨率3-d点云推理深度图而实时的生成。应注意,神经网络/crf模型124并不限于卷积神经网络和条件随机域(crf)模型,而是可包括径向基函数网络模型、递归神经网络模型、kohonen自组织网络模型等。神经网络/crf模型124可包括不同的深度cnn模型,诸如lenettm、alexnettm、zfnettm、googlenettm、vggnettm或其组合。另外,激活层处可引入归一化层,以减少训练时间和增大收敛速率。另外,随机节点处可引入退出(dropout)层,以移除节点对激活层的贡献,从而防止训练数据的过度拟合。
图3是示出根据一个实施方式的与自动驾驶车辆一起使用的感知与规划系统的示例的框图。系统300可以被实施为图1的自动驾驶车辆101的一部分,包括但不限于感知与规划系统110、控制系统111和传感器系统115。参考图3,感知与规划系统110包括但不限于定位模块301、感知模块302、预测模块303、决策模块304、规划模块305、控制模块306以及高分辨率点云模块307。
模块301至307中的一些或全部可以以软件、硬件或其组合实施。例如,这些模块可以安装在永久性存储装置352中、加载到存储器351中,并且由一个或多个处理器(未示出)执行。应注意,这些模块中的一些或全部可以通信地联接到图2的车辆控制系统111的一些或全部模块或者与它们集成在一起。模块301至307中的一些可以一起集成为集成模块。
定位模块301确定自动驾驶车辆300(例如,利用gps单元212)的当前位置。定位模块301(也被称为地图与路线模块)管理与用户的行程或路线相关的任何数据。用户可以例如经由用户接口登录并且指定行程的起始位置和目的地。定位模块301与自动驾驶车辆300的诸如地图和路线信息311的其它部件通信,以获得行程相关数据。例如,定位模块301可以从位置服务器和地图与poi(mpoi)服务器获得位置和路线信息。位置服务器提供位置服务,并且mpoi服务器提供地图服务和某些位置的poi,从而可以作为地图和路线信息311的一部分高速缓存。当自动驾驶车辆300沿着路线移动时,定位模块301也可以从交通信息系统或服务器获得实时交通信息。
基于由传感器系统115提供的传感器数据和由定位模块301获得的定位信息,感知模块302确定对周围环境的感知。感知信息可以表示普通驾驶员在驾驶员正驾驶的车辆周围将感知到的东西。感知可以包括例如采用对象形式的车道配置(例如,直线车道或弯曲车道)、交通灯信号、另一车辆的相对位置、行人、建筑物、人行横道或其它交通相关标志(例如,停止标志、让行标志)等。
感知模块302可以包括计算机视觉系统或计算机视觉系统的功能,以处理并分析由一个或多个摄像机采集的图像,从而识别自动驾驶车辆环境中的对象和/或特征。所述对象可以包括交通信号、道路边界、其它车辆、行人和/或障碍物等。计算机视觉系统可以使用对象识别算法、视频跟踪以及其它计算机视觉技术。在一些实施方式中,计算机视觉系统可以绘制环境地图,跟踪对象,以及估算对象的速度等。感知模块302也可以基于由诸如雷达和/或lidar的其它传感器提供的其它传感器数据来检测对象。
针对每个对象,预测模块303预测对象在这种情况下将如何表现。预测是基于感知数据执行的,该感知数据在考虑一组地图/路线信息311和交通规则312的时间点感知驾驶环境。例如,如果对象为相反方向上的车辆且当前驾驶环境包括十字路口,则预测模块303将预测车辆是否可能会笔直向前移动或转弯。如果感知数据表明十字路口没有交通灯,则预测模块303可能会预测车辆在进入十字路口之前可能需要完全停车。如果感知数据表明车辆目前处于左转唯一车道或右转唯一车道,则预测模块303可能预测车辆将更可能分别左转或右转。
针对每个对象,决策模块304作出关于如何处置对象的决定。例如,针对特定对象(例如,交叉路线中的另一车辆)以及描述对象的元数据(例如,速度、方向、转弯角度),决策模块304决定如何与所述对象相遇(例如,超车、让行、停止、超过)。决策模块304可以根据诸如交通规则或驾驶规则312的规则集来作出此类决定,所述规则集可以存储在永久性存储装置352中。
基于针对所感知到的对象中的每个的决定,规划模块305为自动驾驶车辆规划路径或路线以及驾驶参数(例如,距离、速度和/或转弯角度)。换言之,针对给定的对象,决策模块304决定对该对象做什么,而规划模块305确定如何去做。例如,针对给定的对象,决策模块304可以决定超过所述对象,而规划模块305可以确定在所述对象的左侧还是右侧超过。规划和控制数据由规划模块305生成,包括描述车辆300在下一移动循环(例如,下一路线/路径段)中将如何移动的信息。例如,规划和控制数据可以指示车辆300以30英里每小时(mph)的速度移动10米,随后以25mph的速度变到右侧车道。
基于规划和控制数据,控制模块306根据由规划和控制数据限定的路线或路径通过将适当的命令或信号发送到车辆控制系统111来控制并驾驶自动驾驶车辆。所述规划和控制数据包括足够的信息,以沿着路径或路线在不同的时间点使用适当的车辆设置或驾驶参数(例如,油门、制动和转弯命令)将车辆从路线或路径的第一点驾驶到第二点。
在一个实施方式中,规划阶段在多个规划周期(也称作为指令周期)中执行,例如,在每个时间间隔为100毫秒(ms)的周期中执行。对于规划周期或指令周期中的每一个,将基于规划和控制数据发出一个或多个控制指令。即,对于每100ms,规划模块305规划下一个路线段或路径段,例如,包括目标位置和adv到达目标位置所需要的时间。可替代地,规划模块305还可规定具体的速度、方向和/或转向角等。在一个实施方式中,规划模块305为下一个预定时段(诸如,5秒)规划路线段或路径段。对于每个规划周期,规划模块305基于在前一周期中规划的目标位置规划用于当前周期(例如,下一个5秒)的目标位置。控制模块306然后基于当前周期的规划和控制数据生成一个或多个控制指令(例如,油门、制动、转向控制指令)。
应注意,决策模块304和规划模块305可以集成为集成模块。决策模块304/规划模块305可以包括导航系统或导航系统的功能,以确定自动驾驶车辆的驾驶路径。例如,导航系统可以确定用于实现自动驾驶车辆沿着以下路径移动的一系列速度和前进方向:所述路径在使自动驾驶车辆沿着通往最终目的地的基于车行道的路径前进的同时,基本上避免感知到的障碍物。目的地可以根据经由用户接口系统113进行的用户输入来设定。导航系统可以在自动驾驶车辆正在运行的同时动态地更新驾驶路径。导航系统可以将来自gps系统和一个或多个地图的数据合并,以确定用于自动驾驶车辆的驾驶路径。
决策模块304/规划模块305还可以包括防撞系统或防撞系统的功能,以识别、评估并且避免或以其它方式越过自动驾驶车辆的环境中的潜在障碍物。例如,防撞系统可以通过以下方式实现自动驾驶车辆的导航中的变化:操作控制系统111中的一个或多个子系统来采取变向操纵、转弯操纵、制动操纵等。防撞系统可以基于周围的交通模式、道路状况等自动确定可行的障碍物回避操纵。防撞系统可以被配置成使得当其它传感器系统检测到位于自动驾驶车辆将变向进入的相邻区域中的车辆、建筑障碍物等时不采取变向操纵。防撞系统可以自动选择既可使用又使得自动驾驶车辆乘员的安全性最大化的操纵。防撞系统可以选择预测使得自动驾驶车辆的乘客舱中出现最小量的加速度的避让操纵。
高分辨率点云模块307基于摄像机捕捉的图像和由雷达和/或lidar单元捕捉的低分辨率3-d点云生成高分辨率3-d点云。高分辨率3-d点云可由感知模块302进行使用,以感知adv的驾驶环境。这种图像/3-d点云可由传感器系统115集聚。点云模块307可对摄像机捕捉的图像和低分辨率lidar数据应用一个或多个cnn模型(作为神经网络/crf模型313的一部分),以生成更高分辨率的lidar点云。应注意,点云模块307和感知模块302可集成为集成式模块。
图4是示出根据一个实施方式的与自动驾驶车辆一起使用的高分辨率点云生成器的示例的框图。高分辨率点云模块307包括上采样和/或修复模块401、下采样模块402、全景模块403、条件随机域(crf)模块404和高分辨率深度图模块405。上采样和/或修复模块401可对输入图像上采样,即,使图像尺寸增大一个因子。修复模块可应用修复算法以恢复或重构图像的丢失部分或劣化部分,如深度图中由黑色对象引入的暗点。下采样模块402可对图像下采样,即,使图像尺寸减小一个因子。全景模块403可将较窄角度的图像转换成较宽角度视图的(例如,360度视图)全景图像,或反之亦然。例如,全景模块403可将透视图像的重叠视野首先映射到圆柱坐标或球形坐标中。然后,映射的图像混合和/或拼接在一起。此处,拼接的图像显示了对于圆柱坐标的更宽程度的水平视野和有限竖直视野,或者是对球形坐标的180度的竖直视野。该投影中的全景旨在被视为仿佛该图像被卷绕成圆柱体/球体进行察看并从内部进行察看。当在2d平面上察看时,水平线呈弯曲状,而竖直线仍是竖直的。crf模块404可对cnn模型的输出和低分辨率深度图应用crf(例如,优化模型)模型,以进一步细化深度图的估算。最后,高分辨率深度图模块405对rgb图像/lidar深度图像输入应用cnn模型,以生成高分辨率lidar深度图像。
模块401至405中的一些或全部可以在软件、硬件或其组合中实施。例如,这些模块可安装在永久性存储装置352中,加载到存储器351中,并且由一个或多个处理器(未示出)执行。应注意,这些模块中的一些或全部可以通信地联接至图2的车辆控制系统111中的一些或全部模块,或与图2的车辆控制系统111中的一些或全部模块集成在一起。模块401至405中的一些可集成在一起作为集成式模块。例如,上采样模块401和下采样模块402可与高分辨率深度图模块405集成在一起。
图5a是示出根据一个实施方式的示例性adv的图示。参照图5a,adv101包括在顶部安装的lidar/全景摄像机配置501。在另一实施方式中,lidar/全景摄影机配置501可安装在adv101的引擎盖或车厢上,或adv上适于放置这种传感器单元的任何地方。
图5b和图5c示出根据一些实施方式的lidar/全景摄影机配置的顶视图和侧视图。参照图5b,在一个实施方式中,配置501包括低清晰度或低分辨率lidar单元502和立体全景摄影机504(例如,多摄像机)。在一个实施方式中,lidar单元502可放置在摄像机单元504的顶部上。该单元可校准为具有相似的参考点,诸如中心竖直参考线(未示出),以便lidar和全景摄影机围绕参考线旋转。参照图5c,在一个实施方式中,配置501包括具有单色全景摄影机506的低分辨率lidar单元502。类似地,lidar单元502可放置在摄像机单元506的顶部上,并且这些单元可校准为具有相似的参考点,诸如中心竖直参考线(未示出),以便lidar和全景摄影机围绕该参考线旋转。应注意,低分辨率或低清晰度lidar单元是指与高分辨率lidar单元相比较捕捉稀疏的3-d点云或具有更少点的点云的lidar单元。与密集的3-d点云相比较,稀疏的3-d点云包含更少的深度数据或信息。作为示例性比较,与具有以每秒二百万点捕捉较宽角度视图的较多通道数(例如,64通道)的lidar单元相比较,具有以每秒300,000点捕捉较宽程度视图的16通道或更少通道的lidar单元可为低分辨率单元。
图5d示出根据一个实施方式的单色全景摄影机配置的顶视图和侧视图。在一个实施方式中,单色全景摄影机配置506包括放置为六边形形状的六个摄像机。六边形的中心可以是用于确定摄像机焦点、视野和视角的中心参考点。每个摄像机和其相邻的摄像机都可以放置成在水平视角中间隔约60度,以获得完全更宽的水平视角(例如,360度视图)。在一个实施方式中,六个摄像机中的每个都可以捕捉到视角约为120度水平角的图像,使得由左侧摄像机和右侧相邻的摄像机捕捉到的图像之间有大约30度的重叠。该重叠可用于将捕捉的图像混合和/或拼接在一起以生成全景图像。
具有生成的圆柱形或球形全景图像(例如,全景rgb图像)后,3-d点云可投影到(2-d)圆柱形或球形图像平面上,从而与圆柱形或球形全景rgb图像对齐。例如,3-d点可投影到如下所示的2–d圆柱形(或扭曲的)图像平面上。令(u,v)是扭曲的图像平面上的像素的位置。然后,2-d柱面上的像素位置将是(r,h),其中
以及f为摄像机焦距。相同的3-d点可投影到如下所示的2-d球形图像平面上。
令(u,v)是扭曲的图像平面上的像素的位置。然后,2-d球面上的像素位置将是(r,h),其中
以及f为摄像机焦距。为了从深度图重构点云,可通过将2-d全景深度图反投影到3-d空间上执行逆向转换。可基于全景表面的像素执行三角测量。在一个实施方式中,可从摄像机图像平面上的那些像素的位置直接执行三角测量。在一些实施方式中,更多的摄像机(诸如,三个至八个摄像机)可用于全景摄影机配置506。摄像机可分别以三角形、矩形、五边形或八边形的形状进行布置。
图5e和图5f示出根据一些实施方式的立体全景摄影机配置的示例。参照图5e,在一个实施方式中,立体全景摄影机配置514(例如,图5b的摄像机配置504)包括放置为六边形形状的十二个摄像机。六边形形状的中心可以是用于确定摄像机视角的中心参考点,并作为用于立体摄像机对建立立体全景图像的基线。每个立体成对的摄像机及其相邻的立体摄像机(左摄像机和右摄像机)可呈60度间隔开。
参照图5f,在一个实施方式中,立体全景摄影机配置524(例如,图5b的摄像机配置504)包括两个单色全景摄影机配置,每个均具有放置为六边形形状的六个摄像机。此处,立体全景摄影机配置不是左右立体成对,而是竖直的顶部和底部立体成对。捕捉的立体全景图像可投影到如上所示的柱面或球面上。由立体成对的摄像机捕捉的图像随后用作为高分辨率深度图模块的输入(与低分辨率lidar图像一起),诸如图4的高分辨率深度图模块405,以生成高分辨率深度图或lidar图像。
图6a和图6b分别示出根据一个实施方式的推理模式和训练模式的流程图。图6c和图6d分别示出根据一个实施方式的推理模式和训练模式的流程图。图6a和图6b涉及从摄像机图像构建单色或立体全景图像(通过图像混合和/或拼接技术),然后将全景图像与lidar图像熔合,以生成高分辨率全景深度/视差图。图6c和图6d涉及将摄像机图像与lidar图像熔合以生成高分辨率深度/视差图,然后将深度图混合和/或拼接在一起以生成全景深度图。
参照图6a,描述了根据一个实施方式的推理模式。过程600可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程600可由自动驾驶车辆的点云模块执行,诸如图3的点云模块307。参照图6a,在框601处,处理逻辑校准或配置摄像机装置(例如,确定用于全景配置的参考中心,确定和/或调节摄像机的焦距)。在框603处,处理逻辑生成较宽角度(例如,360度)的立体或单色、圆柱形或球形的全景图像。在框605处,处理逻辑将lidar3d点云投影到全景图像上,以生成深度网格或深度图。在框607处,基于深度网格和单色/立体全景图像,处理逻辑使用编码器-解码器网络611(例如,训练的cnn/cnn+crf模型)执行推理,以生成全景深度图。在框609处,处理逻辑将全景深度图反投影回3-d空间以生成高分辨率点云。
参照图6b,通过过程620描述了根据一个实施方式的训练模式。过程620可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程620可由机器学习引擎执行,诸如图1的服务器103的机器学习引擎122。对于该训练模式,收集了诸如高分辨率lidar点云和单色/立体rgb图像的训练数据。在框621处,根据数据图像源,处理逻辑校准或至少确定用于摄像机图像的摄像机焦距。在框623处,处理逻辑基于单色/立体图像生成全景图像。在框625处,处理逻辑将lidar点云投影到图像平面上和/或将lidar图像上采样为rgb图像比例。对于单色全景,编码器-解码器网络627学习从低分辨率深度全景推理高分辨率深度全景。对于立体全景,编码器-解码器网络627学习改善与低分辨率深度全景相匹配的立体全景,其中,低分辨率深度全景从低分辨率lidar3-d点云投影得来。
参照图6c,描述了根据一个实施方式的推理模式。过程640可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程640可由自动驾驶车辆的点云模块执行,诸如图3的点云模块307。参照图6c,在框641处,处理逻辑校准或配置摄像机装置(例如,确定用于全景配置的参考中心,确定和/或调节摄像机的焦距)。在框643处,处理逻辑预处理摄像机视图,诸如将摄像机视图扭曲成立体视图或非全景圆柱形视图/球形视图。在框645处,处理逻辑将低分辨率lidar3d点云投影到摄像机图像上,以生成低分辨率深度网格或深度图。在框647处,基于深度网格和单色/立体全景图像,处理逻辑使用编码器649(例如,训练的cnn/cnn+crf模型)执行推理,以生成高分辨率深度图。在框653处,处理逻辑基于校准信息651(诸如,校准信息641)生成较宽角度的全景深度图。在框655处,处理逻辑将全景深度图反投影回3-d空间以生成高分辨率点云。
参照图6d,通过过程660描述了根据一个实施方式的训练模式。过程660可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程660可由机器学习引擎执行,诸如图1的服务器103的机器学习引擎122。对于该训练模式,收集了一组众所周知的训练数据,诸如高分辨率lidar点云和单色/立体rgb图像。在框661处,根据数据图像源,处理逻辑校准或至少确定用于摄像机图像的摄像机焦距。在框663处,处理逻辑基于单色/立体图像准备用于训练的摄像机图像。在框665处,处理逻辑将lidar点云投影到rgb图像的图像平面上和/或将lidar图像上采样为rgb图像比例。对于单色摄像机图像,编码器-解码器网络667学习从低分辨率深度全景推理高分辨率深度全景。对于立体摄像机图像,编码器-解码器网络667学习改善与低分辨率深度全景相匹配的立体全景,其中,低分辨率深度全景从低分辨率lidar3-d点云投影得来。
编码器/解码器网络627(例如,cnn模型)的输出与预期结果相比较,以确定编码器/解码器网络627的输出与预期结果之间的差异是否低于预定阈值。如果差异超出预定阈值,则可通过修改该模型的某些参数或系数迭代地执行上述过程。可执行重复的过程,直到该差异降到低于预定阈值,此时,认为模型的最终产品已完成。然后,基于低分辨率点云和由一个或多个摄像机捕捉的图像,该模型在adv中实时的使用以生成高分辨率点云。
图7a和图7b是示出根据一些实施方式的深度图生成的示例的框图。参照图7a,在一个实施方式中,深度图生成器700可以包括下采样模块402和cnn模型701。cnn模型701(作为神经网络/crf模型313的一部分)可以包括收缩层(或编码器或卷积层)713和扩张层(或解码器或反卷积层)715。图7b示出另一示例性实施方式的深度图生成器720。深度图生成器700和720可由图4的深度图模块405执行。
参照图4和图7b,生成器720接收由第一摄像机捕捉的第一图像(例如,摄像机捕捉的图像703),该第一图像捕捉adv的驾驶环境的一部分。第一图像可以是由摄像机装置捕捉的rgb图像。生成器720接收例如低分辨率lidar图像707的第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。下采样模块402以预定的比例因子对第二图像(例如,图像707)下采样,直到第二图像的分辨率达到预定阈值。在一个实施方式中,对第二图像下采样,直到它是密集的,即,直到第二图像的两个相邻云点中的任一个中的重叠或“间隙”的量降到低于预定阈值。生成器720通过对第一图像(例如,图像703)和下采样的第二图像应用cnn模型701来生成第二深度图(例如,高分辨率深度图709),该第二深度图(例如,图像709)比第一深度图(例如,图像707)具有更高的分辨率,使得第二深度图(例如,图像709)表示感知adv周围的驾驶环境的第二点云。应注意,术语“图像”通常指rgb图像或lidar图像。术语“深度图”或“lidar图像”是指映射到透视图像平面或全景图像平面上的3-d点云的2-d图像。“摄像机捕捉的图像”是指由针孔摄像机装置捕捉的光学图像。
在一个实施方式中,摄像机捕捉的图像703和lidar图像707是扭曲或投影到圆柱形或球形图像平面上的非全景图像。在另一实施方式中,摄像机捕捉的图像703和lidar图像707是全景图像,诸如圆柱形或球形全景图像。在另一实施方式中,摄像机捕捉的图像703和lidar图像707是透视图像。此处,对于该摄像机配置,透视图像可从来自单色/立体全景摄影机配置的单个摄像机集或任何单个摄像机生成。对于单色全景摄影机配置,该配置可包括大约在同时捕捉多个图像的多个摄像机,诸如图5c的配置506。图像将通过全景模块(诸如图4的全景模块403)扭曲并混合和/或拼接在一起,以生成圆柱形或球形全景图像。
对于lidar配置,lidar图像707通过将由lidar检测器捕捉的3-d点云从3-d空间/平面映射到2-d图像平面而生成。此处,图像707的2-d图像平面可以是与图像703相同的图像平面。在另一实施方式中,lidar图像707可以是与摄像机捕捉的透视图像703相对应的透视lidar图像。此处,可对若干透视的成对图像703和图像707连续地应用cnn模型701,以生成透视lidar图像。然后,生成的透视lidar图像可由全景模块(诸如,图4的全景模块403)拼接或混合在一起,以生成全景lidar图像。在另一实施方式中,生成器720可包括多个cnn模型,并且这些模型可同时地应用于多个透视的成对图像703和图像707,以生成多个透视lidar图像,从而进行全景图像生成。
参照图4和图7a,在另一实施方式中,生成器700接收第三图像,例如摄像机捕捉的图像705,该摄像机捕捉的图像705由第二摄像机捕捉。生成器700的高分辨率深度图模块(诸如,图4的高分辨率深度图模块405)通过对第一图像、第三图像和上采样的第二图像应用cnn模型来生成第二深度图。此处,图像703和图像705可以是左右立体图像(例如,由图5e的配置514捕捉的图像),或竖直的顶部和底部立体图像(例如,由图5f的配置524捕捉的图像)。尽管仅示出了摄像机捕捉的两个图像,但是还可将由更多摄像机捕捉的更多图像用作为cnn模型的输入。
图8是示出根据一个实施方式的cnn模型的收缩(例如,编码器/卷积)层和扩张(例如,解码器/反卷积)层的图示。cnn模型800接收摄像机图像801、低分辨率深度图像803,并输出高分辨率深度图像825。出于说明的目的,此处使用了单个rgb图像801。然而,还可以应用从多个摄像机捕捉的多个图像,例如,在立体配置中。应注意,在该申请中,rgb图像是指彩色图像。参照图8,摄像机图像801和低分辨率深度图像803可分别表示图7b的图像703和图像707。高分辨率图像825可表示图7b的图像709。cnn模型800可包括不同的层,诸如下采样层805、卷积层(807、809)、反卷积层(811、817)、预测层(813、819、823)和串接层(815、821)。
卷积层(作为图7的收缩层713的一部分)和反卷积层(作为图7的扩张层715的一部分)可以在单个管线中进行连接。卷积层或收缩层中的每个都可对前一输入层下采样,以及扩张层或反卷积层中的每个都可对前一输入层上采样。最后一层收缩层713(例如,层809)连接至第一层扩张层715(例如,层811),以形成单个管线。预测层(813、819、823)执行单通道深度图预测,并将该预测前馈给下一层。
预测层通过减小在训练过程中传播的误差而有助于使最终的cnn输出的估计误差最小化。预测层可以像具有以下的特征的卷积层那样实施:输出图像具有与输入图像相同图像尺寸的一个输出通道。然而,预测层可包括上采样函数,以对输出图像尺寸上采样,以便匹配下一层的图像尺寸。串接层(808、815、821)执行组合函数,该组合函数组合一个或多个图像,诸如,反卷积层、卷积层和/或预测层的输出图像。卷积层/反卷积层能够使cnn通过寻找低水平特征(诸如,边缘和弯曲)来执行图像分类,从而构建更高水平的特征。下采样是指将图像的高度和/或宽度除以一个因子,诸如因子2(即,图像尺寸减少了四倍)。上采样是指将图像的高度和/或宽度乘以一个因子,诸如因子2(即,图像尺寸增大了四倍)。
参照图8,出于说明的目的,在一个实施方式中,在立体配置中图像801可包括单色rgb摄像机图像(例如,组合的3通道、192像素×96像素的图像)或多个rgb图像。低分辨率深度图像803可包括单通道(即,灰度)48像素×24像素的lidar图像(即,图像803是图像801比例的四分之一)。卷积层807可接收图像801,并以因子2对图像801下采样,从而输出64通道、96像素×48像素的图像。随后的卷积层可对来自对应输入的图像以一个因子进行下采样,诸如因子2。
输入的lidar图像803可通过下采样805进行下采样,直到它是密集的。例如,如果在像素和输出中没有间隙或具有较少的间隙,则图像就是密集的,例如,512通道、24像素×12像素的图像。串接层808可对卷积层的对应输出(例如,512通道、24像素×12像素的图像)和下采样层805的输出(例如,512通道、24像素×12像素的图像)执行组合,以产生具有较高分辨率的组合图像(例如,1024通道、24像素×12像素的图像)。应注意,为了使下采样的摄像机图像与下采样的深度图像或深度图进行组合,两个图像的尺寸或维度必须相匹配。根据已进行下采样的深度图像层的尺寸或维度,使用与深度图像的尺寸相匹配的对应卷积层将两个图像组合。卷积层809例如可具有1024通道、24像素×12像素的图像作为输入,以及2048通道、12像素×6像素的图像作为输出。
反卷积层811可具有2048通道、12像素×6像素的图像作为输入,以及1024通道、24像素×12像素的图像作为输出。预测层813可以以因子2对输入进行上采样,并且可具有2048通道、12像素×6像素的图像作为输入,以及1通道、24像素×12像素的图像作为输出。串接层815可具有三个输入,这三个输入具有相匹配的图像尺寸,诸如,来自卷积层809的输入(例如,1024通道、24像素×12像素的图像)、来自预测813的输出(例如,1通道、24像素×12像素的图像)以及来自反卷积层811的输出(例如,1024通道、24像素×12像素的图像)。因此,串接层815可输出2049通道、24像素×12像素的图像。
反卷积层817可具有1024通道、48像素×24像素的图像作为输入,以及512通道、96像素×48像素的图像作为输出。预测层819可以以因子2对先前的输入进行上采样,并且可具有1024通道、48像素×24像素的图像作为输入,以及1通道、96像素×48像素的图像作为输出。串接821可具有三个输入:来自卷积层的前馈(例如,64通道、96像素×48像素的图像)、来自预测层819的输出(例如,1通道、96像素×48像素的图像)以及来自反卷积层817的输出(例如,512通道、96像素×48像素的图像)。然后,串接821将这些输入进行组合,并输出577通道、96像素×48像素的图像。预测层823可以以因子2对输入进行上采样,并且可具有577通道、96像素×48像素的图像作为输入,以及输出1通道、96像素×48像素的深度图像作为输出825。应注意,在一些实施方式中,卷积层可配置成在随机层处的前馈。在一些实施方式中,卷积层之间插入有池化(pooling)层,以及反卷积层之间插入有上池化(unpooling)层。应注意,图8示出了一个cnn模型实施方式,但不应解释为限制。例如,在一些实施方式中,cnn模型可包括不同的激活函数(例如,relu、反曲、阶跃、双曲正切等)、退出层和归一化层等。
图9a和图9b是示出根据一些实施方式的高分辨率深度图生成的示例的框图。图9a的全景转换器903和地图生成器905可分别表示图6a的编码器-解码器网络611和全景生成603。图9b的全景转换器903和地图生成器905共同地可分别表示图6c的编码器-解码器网络649和全景生成653。高分辨率深度图生成器905可由高分辨率深度图模块405执行,以及全景生成器903可由图4的全景模块403执行。参照图9a,高分辨率深度图生成器905的输入联接至全景转换器903的输出。此处,输入901,诸如图7a的摄像机捕捉的图像703和705以及图7a的低分辨率lidar图像707,可由全景转换器903转换为全景图像。生成器905接收全景图像并生成输出905,例如生成高分辨率深度图,诸如图7a的lidar图像709。在该配置中,输入图像通过混合在一起进行组合,以在馈送给cnn模型之前生成全景图像,从而生成高分辨率深度图。
参照图9b,在一个实施方式中,高分辨率深度图生成器905的输出联接至全景转换器903的输入。此处,输入901,诸如图7a的摄像机捕捉的图像703和705以及图7a的低分辨率lidar图像707,可由生成器905通过cnn模型(作为高分辨率深度图生成器905的一部分)进行应用。输出的深度图由全景转换器903接收。转换器903将生成器905的输出转换为全景深度图,例如,输出907。在该示例中,由摄像机捕捉的原始图像馈送到cnn模型中,以分别生成单独的高分辨率深度图。然后,各个深度图通过混合而组合成高分辨率全景深度图。
图10是示出根据一个实施方式的方法的流程图。过程1000可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程1000可由自动驾驶车辆的点云模块执行,诸如图3的点云模块307。参照图10,在框1001处,处理逻辑接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。在框1002处,处理逻辑接收第二图像,该第二图像表示由lidar装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。在框1003处,处理逻辑以预定的比例因子对第二图像下采样,直到第二图像的分辨率达到预定的阈值。在框1004处,处理逻辑通过对第一图像和下采样的第二图像应用卷积神经网络(cnn)模型生成第二深度图,第二深度图比第一深度图具有更高的分辨率,使得第二深度图表示感知adv周围的驾驶环境的第二点云。
在一个实施方式中,处理逻辑接收由第二摄像机捕捉的第三图像,并通过对第一图像、第三图像和下采样的第二图像应用cnn模型来生成第二深度图。在一个实施方式中,第一图像包括圆柱形全景图像或球形全景图像。在另一实施方式中,圆柱形全景图像或球形全景图像是基于由若干摄像机装置捕捉的若干图像生成的。在另一实施方式中,处理逻辑通过将第二深度图投影到基于圆柱形全景图像或球形全景图像的3-d空间中来重构第二点云。
在一个实施方式中,处理逻辑将下采样的第二图像映射到第一图像的图像平面上。在一个实施方式中,第二深度图是通过将一个或多个生成的深度图进行混合而生成,使得第二深度图是全景图。
在一个实施方式中,cnn模型包括收缩层和扩张层,其中,每个收缩层均包括编码器以对相应的输入进行下采样,以及扩张层联接至收缩层,每个扩张层均包括解码器以对相应的输入进行上采样。在一个实施方式中,收缩层的信息前馈给扩张层,例如,收缩层的输出前馈给具有相匹配的图像尺寸或维度的扩张层的输入。在一个实施方式中,扩张层中的每个均包括预测层,以预测用于后续层的深度图。
图11a和图11b是示出根据一些实施方式的深度图生成的示例的框图。参照图11a,在一个实施方式中,深度图生成器1100可以包括上采样/修复模块401和cnn模型701。cnn模型701(作为神经网络/crf模型313的一部分)可以包括收缩层(或编码器或卷积层)713和扩张层(或解码器或反卷积层)715。图11b示出另一示例性实施方式的深度图生成器1120。深度图生成器1100和1120可由图4的深度图模块405执行。
参照图4和图11b,生成器1120接收由第一摄像机捕捉的第一图像(例如,摄像机捕捉的图像703),该第一图像捕捉adv的驾驶环境的一部分。生成器1120接收例如低分辨率lidar图像707的第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。上采样/修复模块401以预定的比例因子对第二图像(例如,图像707)上采样,以将图像707匹配为图像703的图像比例。在一个实施方式中,对上采样的第二图像应用算法地修复函数,以恢复图像的任何缺失部分,例如,修复上采样的图像的背景部分。修复是对图像的丢失或劣化部分进行恢复或重构的过程。在另一实施方式中,修复算法可包括将lidar捕捉的图像与在前一时间帧中捕捉的lidar图像进行比较。生成器1120通过对第一图像(例如,图像703)和上采样的和/或修复的第二图像应用cnn模型701来生成第二深度图(例如,高分辨率深度图709),其中,第二深度图(例如,图像709)比第一深度图(例如,图像707)具有更高的分辨率,使得第二深度图(例如,图像709)表示感知adv周围的驾驶环境的第二点云。
在一个实施方式中,摄像机捕捉的图像703和lidar图像707是全景图像,诸如圆柱形或球形全景图像。在另一实施方式中,摄像机捕捉的图像703和lidar图像707是透视图像。此处,对于该摄像机配置,透视图像可从来自单色/立体全景摄影机配置的单个摄像机集或单个摄像机生成。对于单色全景摄影机配置,该配置可包括大约在同时捕捉多个图像的多个透视摄像机,诸如,图5c的配置506。图像将通过全景模块混合或拼接在一起,诸如图4的全景模块403,以生成全景图像。
对于lidar配置,lidar图像707通过以下步骤生成:将由lidar检测器捕捉的3-d点云从3-d空间/平面映射,接着是3-d点云到2-d图像平面的转换。此处,图像707的2-d图像平面可以是与图像703相同的图像平面。在另一实施方式中,lidar图像707可以是与摄像机捕捉的透视图像703相对应的透视lidar图像。此处,可对若干透视的成对图像703和图像707连续地应用cnn模型701,以生成透视lidar图像。然后,生成的透视lidar图像可通过全景模块(诸如,图4的全景模块403)拼接或混合在一起,以生成全景lidar图像。在另一实施方式中,生成器1120可包括多个cnn模型,并且这些模型可同时地应用于多个透视的成对图像703和图像707,以生成多个透视lidar图像,从而进行全景图像生成。
参照图4和图11a,在另一实施方式中,生成器1100接收第三图像,例如摄像机捕捉的图像705,该摄像机捕捉的图像705由第二摄像机捕捉。生成器1100通过对第一图像、第三图像和上采样的和/或修复的第二图像应用cnn模型来生成第二深度图。此处,图像703和图像705可以是左右立体图像(例如,由图5e的配置514捕捉的图像),或竖直的顶部和底部立体图像(例如,由图5f的配置524捕捉的图像)。
图12是示出根据一个实施方式的cnn模型的收缩(例如,编码器/卷积)层和扩张(例如,解码器/反卷积)层的图示。cnn模型1200接收摄像机图像801、低分辨率深度图像803并输出高分辨率深度图像825。摄像机图像801和低分辨率深度图像803可分别是图11b的图像703和图像707。高分辨率深度图像825可以是图11b的图像709。cnn模型1200可包括不同的层,诸如上采样层1203、卷积层(807、809)、反卷积层(811、817)、预测层(813、819、823)和串接层(815、821)。图12在大多数方面与图8相类似,除了在cnn模型的输入层处应用lidar图像(例如,低分辨率深度图像803)以及串接层(例如,图8的层808)可省略之外。
参照图12,例如,摄像机图像801可包括单色rgb摄像机图像(例如,3通道、192像素×96像素)。低分辨率深度图像803可包括单通道(即,灰度)48像素×24像素的lidar图像(即,图像803是图像801比例的四分之一)。上采样层1203以比例因子(即,四)对图像803上采样,以便匹配图像801的图像比例,并输出一个通道、192像素×96像素的图像。上采样层1203可包括修复层,使得可应用修复算法以重构缺失的像素,其中,缺失的像素可以通过由lidar检测器感知的暗点/人工因素引入,诸如凹坑、阴影和/或天气现象。该上采样的/修复的图像在其由卷积层807接收之前,与单色rgb摄像机图像进行组合(将图像通道加在一起)。例如,层807的输入图像可以是具有4通道、192像素×96像素尺寸的图像。
图13是示出根据一个实施方式的方法的流程图。过程1300可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程1300可由自动驾驶车辆的点云模块执行,诸如图3的点云模块307。参照图13,在框1301处,处理逻辑接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。在框1302处,处理逻辑接收第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。在框1303处,处理逻辑以预定的比例因子对第二图像上采样,以匹配第一图像的图像比例。在框1304处,处理逻辑通过对第一图像和上采样的第二图像应用卷积神经网络(cnn)模型来生成第二深度图,该第二深度图比第一深度图具有更高的分辨率,使得第二深度图表示用于感知adv周围的驾驶环境的第二点云。
在一个实施方式中,处理逻辑接收由第二摄像机捕捉的第三图像,并通过对第一图像、第三图像和上采样的第二图像应用cnn模型来生成第二深度图。在一个实施方式中,第一图像包括圆柱形全景图像或球形全景图像。在另一实施方式中,圆柱形全景图像或球形全景图像是基于由若干摄像机装置捕捉的若干图像生成的。在另一实施方式中,处理逻辑通过将第二深度图投影到基于圆柱形全景图像或球形全景图像的3-d空间中来重构第二点云。
在一个实施方式中,处理逻辑将上采样的第二图像映射到第一图像的图像平面上。在一个实施方式中,第二深度图是通过将一个或多个生成的深度图进行混合而生成,使得第二深度图是全景图。
在一个实施方式中,cnn模型包括收缩层和扩张层,其中,每个收缩层均包括编码器以对相应的输入进行下采样,以及扩张层联接至收缩层,每个扩张层均包括解码器以对相应的输入进行上采样。在一个实施方式中,收缩层的信息前馈给扩张层。在一个实施方式中,扩张层中的每个均包括预测层,以预测用于后续层的深度图。在一个实施方式中,对第二图像上采样包括修复第二图像。
图14a和图14b是示出根据一些实施方式的卷积神经网络模型的示例的框图。参照图14a,在一个实施方式中,深度图生成器1400可以包括上采样模块1401和cnn模型701。cnn模型701(作为神经网络/crf模型313的一部分)可以包括收缩层(或编码器或卷积层)713和扩张层(或解码器或反卷积层)715。图14b示出另一示例性实施方式的深度图生成器1420。深度图生成器1400和1420可由图4的深度图模块405执行。
参照图4和图14b,生成器1420接收由第一摄像机捕捉的第一图像(例如,摄像机捕捉的图像703),该第一图像捕捉adv的驾驶环境的一部分。生成器1420接收例如低分辨率lidar图像707的第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。上采样模块1401以预定的比例因子对第二图像(例如,图像707)上采样,以匹配cnn模型701的输出图像的图像比例。生成器1420通过对第一图像(例如,图像703)应用cnn模型701来确定第二深度图(例如,cnn模型701的输出图像)。生成器1420通过对第一图像(例如,图像703)、第二图像(例如,图像707)和第二深度图(例如,cnn模型701的输出图像)应用条件随机域(crf)模型(由crf1403执行,即图4的crf404)来生成第三深度图,该第三深度图比第一深度图具有更高的分辨率,使得第三深度图表示用于感知adv周围的驾驶环境的第二点云。
可使用诸如crf的优化模型来细化深度/视差的估计。根据一个方面,端对端cnn模型包括crf模型,该crf模型包括三个成本项以优化(或最小化)总成本函数。例如,crf成本函数可以是:
crf(x)=∑i∈vfi(x)+∑ij∈ufij(xij)+∑k∈wgk(xk),
其中,xi是第i个像素的视差值,v是所有像素的集合,u是一组图像边缘,以及w是lidar图像的网格点的集合。前两项(例如,fi(xi)和fij(xij))可分别是立体匹配成本的一元项和估计对比敏感边缘权重的平滑的成对的项(即,图像像素平滑度/不连续性)。
例如,cnn-crf模型可配置成使得一元项可基于立体左rgb图像和立体右rgb图像(诸如,图14a的图像703和图像705)的相关性(例如,基于图14a的cnn模型701的输出)进行确定,即立体匹配成本。在替代方案中,cnn-crf模型可配置成使得一元项可基于第i个像素的视差值的“信息增益”(即,基于图14b的cnn模型701的输出)进行确定,其中,该第i个像素的视差值的“信息增益”具有来自应用于单色(或单目)rgb图像(诸如,图14b的图像703)的所有其它视差值的贡献。
平滑成对的项可基于任一对像素的表示所估计的深度图的平滑度/不连续性的视差值(例如,基于cnn模型701的输出)进行确定。这种成本项的示例在knobelreiter等人的“end-to-endtrainingofhybridcnn-crfmodelsforstereo(对混合式立体cnn-crf模型的端对端训练)”(2016年11月)中进行了限定,该文献的内容通过引用以其整体并入本文中。在替代实施方式中,成本项可以是在cao等人的“estimatingdepthfrommonocularimagesasclassificationusingdeepfullyconvolutionalresidualnetworks(使用深度完全卷积残余网络估计单目图像的深度进行分类)”(2016年5月)中限定的信息增益,该文献的内容通过引用以其整体并入本文中。第三项(例如,g(x))可以是成本项,该成本项表示所估计的lidar图像相对于低分辨率lidar图像的误差项(即,基于图14a至图14b的cnn模型701的输出和上采样1401的输出)。
在一个实施方式中,g(x)可限定为:
其中,阈值是诸如1.0或2.0的预定阈值,xi是第i个像素的视差值,以及dk是低分辨率lidar图像的视差值。应注意,f(x)和g(x)项可包括基于输入图像703的权重项,这些权重项逐像素的应用于输入图像,以突出图像的对比度。例如,crf1403可基于图14a至图14b的输入的rgb图像703对f(x)和/或g(x)应用权重项。
在一个实施方式中,摄像机捕捉的图像703和lidar图像707是全景图像,诸如圆柱形或球形全景图像。在另一实施方式中,摄像机捕捉的图像703和lidar图像707是透视图像。要捕捉图像703的摄像机配置可包括图5d至图5f的摄像机配置的任何摄像机。
对于lidar配置,lidar图像707通过以下步骤生成:将由lidar检测器捕捉的3-d点云从3-d空间/平面映射,接着是3-d点云到2-d图像平面的转换。此处,图像707的2-d图像平面可以是与图像703相同的图像平面。在另一实施方式中,lidar图像707可以是与摄像机捕捉的透视图像703相对应的透视lidar图像。如先前所描述的,可对若干透视的成对图像703和图像707连续地应用cnn模型701,以生成透视lidar图像。在另一实施方式中,可对多个透视的成对图像703和图像707同时地应用若干cnn模型,以生成多个透视lidar图像,从而进行全景图像生成。
参照图4和图14a,在另一实施方式中,生成器1400接收第三图像,例如摄像机捕捉的图像705,该摄像机捕捉的图像705由第二摄像机捕捉。生成器1400通过对第一图像和第三图像应用cnn模型来确定第二深度图。通过crf1403对第二深度图应用crf模型,以生成第三深度图。此处,图像703和图像705可以是左右立体图像(例如,由图5e的配置514捕捉的图像),或竖直的顶部和底部立体图像(例如,由图5f的配置524捕捉的图像)。
图15是示出根据一个实施方式的方法的流程图。过程1550可以由处理逻辑执行,所述处理逻辑可以包括软件、硬件或其组合。例如,过程1550可由自动驾驶车辆的点云模块执行,诸如图3的点云模块307。参照图15,在框1551处,处理逻辑接收由第一摄像机捕捉的第一图像,该第一图像捕捉adv的驾驶环境的一部分。在框1552处,处理逻辑接收第二图像,该第二图像表示由激光雷达(lidar)装置产生的、与该驾驶环境的一部分相对应的第一点云的第一深度图。在框1553处,处理逻辑通过对第一图像应用卷积神经网络(cnn)模型来确定第二深度图。在框1554处,处理逻辑通过对第一图像、第二图像和第二深度图应用条件随机域函数来生成第三深度图,该第三深度图比第一深度图具有更高的分辨率,使得第三深度图表示感知adv周围的驾驶环境的第二点云。
在一个实施方式中,处理逻辑接收由第二摄像机捕捉的第三图像,并通过对第一图像和第三图像应用cnn模型来生成第三深度图。在一个实施方式中,第一图像包括圆柱形全景图像或球形全景图像。在另一实施方式中,圆柱形全景图像或球形全景图像是基于由若干摄像机装置捕捉的若干图像生成的。在另一实施方式中,处理逻辑通过将第三深度图投影到基于圆柱形全景图像或球形全景图像的3-d空间中来重构第二点云。
在一个实施方式中,处理逻辑将第三图像映射到第一图像的图像平面上。在一个实施方式中,第三深度图是通过将一个或多个生成的深度图进行混合而生成,使得第三深度图是全景图。
在一个实施方式中,cnn模型包括收缩层和扩张层,其中,每个收缩层均包括编码器以对相应的输入进行下采样,以及扩张层联接至收缩层,每个扩张层均包括解码器以对相应的输入进行上采样。在一个实施方式中,收缩层的信息前馈给扩张层。在一个实施方式中,扩张层中的每个均包括预测层,以预测用于后续层的深度图。
应注意,如上文示出和描述的部件中的一些或全部可以在软件、硬件或其组合中实施。例如,此类部件可以实施为安装并存储在永久性存储装置中的软件,所述软件可以通过处理器(未示出)加载在存储器中并在存储器中执行以实施贯穿本申请所述的过程或操作。替代地,此类部件可以实施为编程或嵌入到专用硬件(诸如,集成电路(例如,专用集成电路或asic)、数字信号处理器(dsp)或现场可编程门阵列(fpga))中的可执行代码,所述可执行代码可以经由来自应用的相应驱动程序和/或操作系统来访问。此外,此类部件可以实施为处理器或处理器内核中的特定硬件逻辑,作为可由软件部件通过一个或多个特定指令访问的指令集的一部分。
图16是示出可以与本公开的一个实施方式一起使用的数据处理系统的示例的框图。例如,系统1500可以表示以上所述的执行上述过程或方法中的任一个的任何数据处理系统,例如,图1的感知与规划系统110或者服务器103至104中的任一个。系统1500可以包括许多不同的部件。这些部件可以实施为集成电路(ic)、集成电路的部分、分立电子装置或适用于电路板(诸如,计算机系统的主板或插入卡)的其它模块或者实施为以其它方式并入计算机系统的机架内的部件。
还应注意,系统1500旨在示出计算机系统的许多部件的高阶视图。然而,应当理解的是,某些实施例中可以具有附加的部件,此外,其它实施例中可以具有所示部件的不同布置。系统1500可以表示台式计算机、膝上型计算机、平板计算机、服务器、移动电话、媒体播放器、个人数字助理(pda)、智能手表、个人通信器、游戏装置、网络路由器或集线器、无线接入点(ap)或中继器、机顶盒或其组合。此外,虽然仅示出了单个机器或系统,但是术语“机器”或“系统”还应当被理解为包括单独地或共同地执行一个(或多个)指令集以执行本文所讨论的任何一种或多种方法的机器或系统的任何集合。
在一个实施方式中,系统1500包括通过总线或互连件1510连接的处理器1501、存储器1503以及装置1505至1508。处理器1501可以表示其中包括单个处理器内核或多个处理器内核的单个处理器或多个处理器。处理器1501可以表示一个或多个通用处理器,诸如,微处理器、中央处理单元(cpu)等。更具体地,处理器1501可以是复杂指令集计算(cisc)微处理器、精简指令集计算(risc)微处理器、超长指令字(vliw)微处理器、或实施其它指令集的处理器、或实施指令集组合的处理器。处理器1501还可以是一个或多个专用处理器,诸如,专用集成电路(asic)、蜂窝或基带处理器、现场可编程门阵列(fpga)、数字信号处理器(dsp)、网络处理器、图形处理器、通信处理器、加密处理器、协处理器、嵌入式处理器、或者能够处理指令的任何其它类型的逻辑。
处理器1501(其可以是低功率多核处理器套接口,诸如超低电压处理器)可以充当用于与所述系统的各种部件通信的主处理单元和中央集线器。这种处理器可以实施为片上系统(soc)。处理器1501被配置成执行用于执行本文所讨论的操作和步骤的指令。系统1500还可以包括与可选的图形子系统1504通信的图形接口,图形子系统1504可以包括显示控制器、图形处理器和/或显示装置。
处理器1501可以与存储器1503通信,存储器1503在一个实施方式中可以经由多个存储器装置实施以提供给定量的系统存储。存储器1503可以包括一个或多个易失性存储(或存储器)装置,诸如,随机存取存储器(ram)、动态ram(dram)、同步dram(sdram)、静态ram(sram)或者其它类型的存储装置。存储器1503可以存储包括由处理器1501或任何其它装置执行的指令序列的信息。例如,各种操作系统、装置驱动程序、固件(例如,输入输出基本系统或bios)和/或应用的可执行代码和/或数据可以加载到存储器1503中并由处理器1501执行。操作系统可以是任何类型的操作系统,例如,机器人操作系统(ros)、来自
系统1500还可以包括i/o装置,诸如装置1505至1508,包括网络接口装置1505、可选的输入装置1506,以及其它可选的i/o装置1507。网络接口装置1505可以包括无线收发器和/或网络接口卡(nic)。所述无线收发器可以是wifi收发器、红外收发器、蓝牙收发器、wimax收发器、无线蜂窝电话收发器、卫星收发器(例如,全球定位系统(gps)收发器)或其它射频(rf)收发器或者它们的组合。nic可以是以太网卡。
输入装置1506可以包括鼠标、触摸板、触敏屏幕(其可以与显示装置1504集成在一起)、指针装置(诸如,手写笔)和/或键盘(例如,物理键盘或作为触敏屏幕的一部分显示的虚拟键盘)。例如,输入装置1506可以包括联接到触摸屏的触摸屏控制器。触摸屏和触摸屏控制器例如可以使用多种触敏技术(包括但不限于电容、电阻、红外和表面声波技术)中的任一种,以及其它接近传感器阵列或用于确定与触摸屏接触的一个或多个点的其它元件来检测其接触和移动或间断。
i/o装置1507可以包括音频装置。音频装置可以包括扬声器和/或麦克风,以促进支持语音的功能,诸如语音识别、语音复制、数字记录和/或电话功能。其它i/o装置1507还可以包括通用串行总线(usb)端口、并行端口、串行端口、打印机、网络接口、总线桥(例如,pci-pci桥)、传感器(例如,诸如加速度计运动传感器、陀螺仪、磁强计、光传感器、罗盘、接近传感器等)或者它们的组合。装置1507还可以包括成像处理子系统(例如,摄像机),所述成像处理子系统可以包括用于促进摄像机功能(诸如,记录照片和视频片段)的光学传感器,诸如电荷耦合装置(ccd)或互补金属氧化物半导体(cmos)光学传感器。某些传感器可以经由传感器集线器(未示出)联接到互连件1510,而诸如键盘或热传感器的其它装置可以根据系统1500的具体配置或设计由嵌入式控制器(未示出)控制。
为了提供对诸如数据、应用、一个或多个操作系统等信息的永久性存储,大容量存储设备(未示出)也可以联接到处理器1501。在各种实施方式中,为了实现更薄且更轻的系统设计并且改进系统响应性,这种大容量存储设备可以经由固态装置(ssd)来实施。然而,在其它实施方式中,大容量存储设备可以主要使用硬盘驱动器(hdd)来实施,其中较小量的ssd存储设备充当ssd高速缓存以在断电事件期间实现上下文状态以及其它此类信息的非易失性存储,从而使得在系统活动重新启动时能够实现快速通电。另外,闪存装置可以例如经由串行外围接口(spi)联接到处理器1501。这种闪存装置可以提供系统软件的非易失性存储,所述系统软件包括所述系统的bios以及其它固件。
存储装置1508可以包括计算机可访问的存储介质1509(也被称为机器可读存储介质或计算机可读介质),其上存储有体现本文所述的任何一种或多种方法或功能的一个或多个指令集或软件(例如,模块、单元和/或逻辑1528)。处理模块/单元/逻辑1528可以表示上述部件中的任一个,例如规划模块305、控制模块306和高分辨率点云模块307。处理模块/单元/逻辑1528还可以在其由数据处理系统1500、存储器1503和处理器1501执行期间完全地或至少部分地驻留在存储器1503内和/或处理器1501内,数据处理系统1500、存储器1503和处理器1501也构成机器可访问的存储介质。处理模块/单元/逻辑1528还可以通过网络经由网络接口装置1505进行传输或接收。
计算机可读存储介质1509也可以用来永久性地存储以上描述的一些软件功能。虽然计算机可读存储介质1509在示例性实施方式中被示为单个介质,但是术语“计算机可读存储介质”应当被认为包括存储所述一个或多个指令集的单个介质或多个介质(例如,集中式或分布式数据库和/或相关联的高速缓存和服务器)。术语“计算机可读存储介质”还应当被认为包括能够存储或编码指令集的任何介质,所述指令集用于由机器执行并且使得所述机器执行本公开的任何一种或多种方法。因此,术语“计算机可读存储介质”应当被认为包括但不限于固态存储器以及光学介质和磁性介质,或者任何其它非暂时性机器可读介质。
本文所述的处理模块/单元/逻辑1528、部件以及其它特征可以实施为分立硬件部件或集成在硬件部件(诸如,asic、fpga、dsp或类似装置)的功能中。此外,处理模块/单元/逻辑1528可以实施为硬件装置内的固件或功能电路。此外,处理模块/单元/逻辑1528可以以硬件装置和软件部件的任何组合来实施。
应注意,虽然系统1500被示出为具有数据处理系统的各种部件,但是并不旨在表示使部件互连的任何特定架构或方式;因为此类细节和本公开的实施方式没有密切关系。还应当认识到,具有更少部件或可能具有更多部件的网络计算机、手持计算机、移动电话、服务器和/或其它数据处理系统也可以与本公开的实施方式一起使用。
前述详细描述中的一些部分已经根据在计算机存储器内对数据位的运算的算法和符号表示而呈现。这些算法描述和表示是数据处理领域中的技术人员所使用的方式,以将他们的工作实质最有效地传达给本领域中的其他技术人员。本文中,算法通常被认为是导致所期望结果的自洽操作序列。这些操作是指需要对物理量进行物理操控的操作。
然而,应当牢记,所有这些和类似的术语均旨在与适当的物理量关联,并且仅仅是应用于这些量的方便标记。除非在以上讨论中以其它方式明确地指出,否则应当了解,在整个说明书中,利用术语(诸如所附权利要求书中所阐述的术语)进行的讨论是指计算机系统或类似电子计算装置的动作和处理,所述计算机系统或电子计算装置操控计算机系统的寄存器和存储器内的表示为物理(电子)量的数据,并将所述数据变换成计算机系统存储器或寄存器或者其它此类信息存储设备、传输或显示装置内类似地表示为物理量的其它数据。
本公开的实施方式还涉及用于执行本文中的操作的设备。这种计算机程序被存储在非暂时性计算机可读介质中。机器可读介质包括用于以机器(例如,计算机)可读的形式存储信息的任何机构。例如,机器可读(例如,计算机可读)介质包括机器(例如,计算机)可读存储介质(例如,只读存储器(“rom”)、随机存取存储器(“ram”)、磁盘存储介质、光存储介质、闪存存储器装置)。
前述附图中所描绘的过程或方法可以由处理逻辑来执行,所述处理逻辑包括硬件(例如,电路、专用逻辑等)、软件(例如,体现在非暂时性计算机可读介质上)或两者的组合。尽管所述过程或方法在上文是依据一些顺序操作来描述的,但是应当了解,所述操作中的一些可以按不同的顺序执行。此外,一些操作可以并行地执行而不是顺序地执行。
本公开的实施方式并未参考任何特定的编程语言进行描述。应认识到,可以使用多种编程语言来实施如本文描述的本公开的实施方式的教导。
在以上的说明书中,已经参考本发明的具体示例性实施方式对本公开的实施方式进行了描述。将显而易见的是,在不脱离所附权利要求书中阐述的本公开的更宽泛精神和范围的情况下,可以对本发明作出各种修改。因此,应当在说明性意义而不是限制性意义上来理解本说明书和附图。
- 还没有人留言评论。精彩留言会获得点赞!