一种基于AI技术的空气质量短期高精度预测模型的制作方法
本发明涉及空气质量监测领域技术领域,具体为一种基于ai技术的空气质量短期高精度预测模型。
背景技术:
环境空气质量与人们日常生活息息相关,同时也在城市环境综合测评评比中占有重要地位。随着人类文明和经济的发展,空气污染日益严重,环境污染、大气污染的监测与防治也逐渐成为国家发展建设中的一项重要工程。根据中华人民共和国生态环境部5月底公布的《2017中国生态环境状况公报》显示:全国338个地级市及以上城市,仅有99个城市环境空气质量达标,占全部城市数量的29.3%;城市环境空气质量超标城市数量高达239,占比高达70.7%。338个城市发生重度污染2311天次、严重污染802天次,以pm2.5为首要污染物的天数占重度及以上污染天数的74.2%,以pm10为首要污染物的占20.4%,以o3为首要污染物的占5.9%。因此城市空气质量(aqi)及其相关有害污染物的预报对公众健康、城市规划、以及政府管控都尤为重要。如何对空气质量以及各项污染物进行高精度预报,并为政府管控部门实施有效管控措施提供预留时间,是空气质量监测与防治的工作重点。
空气污染物预报是根据历史空气污染物排放情况以及气象条的变化、扩散状况、地理地貌等因素进行下一时刻的空气污染程度。空气污染物的预测方法一般分为两类:
1:数值预报方法。2:统计学预报方法。
数值预报是一种以空气动力学理论为基础,基于物理化学过程的确定性预报方法。利用数学方法建立大气污染物浓度在空气中的稀释扩散的数值模型,通过计算机进行计算,从而实现对大气污染物浓度在空气中的变化进行预测。数值预报模型同样存在缺陷不足:数值预报方法更适合区域性空气污染物预报;数值预报需要详细的污染物资料,但是常常难以获得;数值预报方法计算复杂度极高,总体成本巨大,一定程度限制了该理论方法的完善。
统计学方法预报不依赖于污染物的物理化学变化等演变过程。通过分析污染物相关的输入输出的统计规律,进行污染物未来浓度变化趋势预测。该预报方法简单快捷,避免了复杂的理论计算,计算成本相对较低,并且能够实现一定程度的预测精度。统计方法同样存在不足之处:统计学预报方法简化了较多影响因子,一定程度上影响了预测的精度。
现有基于统计方法的空气质量预测一般为考虑把原始数据作为预测模型的特征输入,但是原始数据并不能充分体现数据统计特征,无法体现数据的集中或离散趋势、时间趋势等,因此无法保证预测的准确性,另一方面,现有预测模型大多为以天为单位的预测,也即是基于历史污染物浓度预测接下来一整天的浓度,明显这种精度的预测结果无法满足预期,无法满足人们对于逐小时精度的需求。上述各专利提出的预测方法虽然一定程度上实现了依据历史空气污染物浓度数据对当前或者未来污染物浓度进行预报,但是无法实现逐小时短时高精度的预报,也没有综合考虑各种气象以及地理地貌等因素对污染物扩散的影响,对数据的使用以及模型的范化能力和预报的准确度均有待提高。
技术实现要素:
本发明的目的在于提供一种基于ai技术的空气质量短期高精度预测模型,解决了背景技术中的等问题。
为实现上述目的,本发明提供如下技术方案:一种基于ai技术的空气质量短期高精度预测模型,包括以下步骤:
s1:对原始数据的处理与分析;
s2:神经网络框架的搭建;
s3:全连接fc层。
优选的,针对步骤一中包括错误数据的删减、缺失数据的插值处理、气象因素如风向风级风速的插值处理、时间以及风速等数据的编码等相关数据计算。
优选的,针对步骤二中采用两层lstm+两层全连接fc的网络结构,将历史污染物浓度与使用的气象因素区分开来,实现利用lstm网络提取历史污染物浓度的历史变化的时序特征,在第二层lstm网络输出层后面,连接第一层全连接fc层,该fc层的具体输入为lstm层的输出结果、各项气象因素、时间节点编码信息、以及中心城市周围的插值数据信息。
优选的,针对步骤三中,影响空气质量的各项污染指标由诸多因素决定,温度、湿度、风向、风力等气象因素都会为污染物的传播扩散产生影响,通过分析个各项污染物的分部信息,可以发现不同污染物在时间分布上呈现随时间变化。
一种基于ai技术的空气质量短期高精度预测模型,包括以下步骤:
s11:有关aqi的统计分析;
s21:删除原始数据中无关数据;
s31:错误数据处理;
s41:基于时间的缺失数据插值处理;
s51:对于‘月份’,‘星期’,‘小时’等日期数据进行one_hot编码处理;
s61:数据标准化;
s71:解决one_hot编码对于时间变量在作为神经网络输入的不合理性;
s81:对气象数据做处理:风向数据处理;
s9:地理信息数据处理。
优选的,第一层隐藏神经元个数为512,第二层全连接层隐藏神经单元个数1024;fc全连接模块包含一层全连接层和输出全连接层,全连接层隐藏神经元个数分别为512,24。
优选的,时间变化按照已知规律变化,不需要lstm网络去提取特征,只作为全连接的输入。
与现有技术相比,本发明的有益效果是:
本基于ai技术的空气质量短期高精度预测模型,实现利用lstm网络提取历史污染物浓度的历史变化的时序特征,在第二层lstm网络输出层后面,连接第一层全连接fc层,该fc层的具体输入为lstm层的输出结果、各项气象因素、时间节点编码信息、以及中心城市周围的插值数据信息。最后一层全连接fc层为模型的输出层,该层实现将上述各层的输出压缩为24个节点,每个节点对应一个小时的预测输出结果,从而实现以小时为单位的空气质量预报,最终该预报模型能够实现以小时为单位的污染物短时高精度预报。
附图说明
图1为本发明的神经网路结构图;
图2为本发明的全连接层的激活函数图;
图3为本发明的lstm网络结构图;
图4为本发明的全连接层示意图。
图5为本发明的sigmoid激活函数图;
图6为本发明的tanh激活函数图;
图7为本发明的softplus激活函数图。
具体实施方式
以下将详细说明本发明实施例,然而,本发明实施例并不以此为限。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一:
一种基于ai技术的空气质量短期高精度预测模型,包括以下步骤:
步骤一:对原始数据的处理与分析,包括错误数据的删减、缺失数据的插值处理、气象因素如风向风级风速的插值处理、时间以及风速等数据的编码等相关数据计算;
第一步:有关aqi的统计分析,根据分析结果确定利用分别预测影响aqi指数的污染指标的方法,然后再根据相关理论根据预测得到的各项污染物指标计算aqi指数;
第二步:删除原始数据中无关数据,例如‘空气质量(文字描述:例如‘优良’等)’等对模型构建无关的数据;
第三步:错误数据处理,对于污染物'co','no2','o3','so2','pm10','pm2.5'等数据,由于在任何时间、地点、任意污染物浓度均不应该为‘0’,故对各项污染物所有为‘0’的数据做错误采样处理,将为‘0’的数据设置为‘nan’,等待下一步进行插值处理;
第四步:基于时间的缺失数据插值处理,通过对数据做统计分析,对存在缺失时间点的数据进行插值处理。在处理过程中,发现存在数据丢失现象,对此重新生成“标准时序”(即全部为逐小时时序),将原始数据融合到标准时序,对于原始数据缺失的时间点数据,在标准时序对应时间上将其数值做‘nan’处理。最后对所有为‘nan’的数据时间点,进行基于时间的插值处理;
第五步:对于‘月份’,‘星期’,‘小时’等日期数据进行one_hot编码处理,以‘星期’数据为例:对于‘星期一’,该时间点输入网络的方式为‘[1000000]’;
第六步:数据标准化,除对时间信息数据进行one_hot编码,对于非时间信息数据要进行数据归一化处理,从而可以加快网络的训练,减小计算成本。
所以在这里我们选择标准分数z-score标准化方法,通过:z=x/σ;
其中x为某污染物,或气象数据的具体数值,σ为该指标所有数据的标准差,来实现数据的标准化,表明原数据在其分布中的位置,帮助网络训练;
第七步:解决one_hot编码对于时间变量在作为神经网络输入的不合理性,ont_hot编码在对不同事件进行分类标记时最为常用,但是当作为为神经网络的输入特征时则需要考虑其临近变量对神经网络的神经元的作用,比如第一小时与第二小时在one_hot编码时是离散的两个时间点,但是实际上第一小时与第二小时是过度变化,而污染物的变化也是连续变化,因此有必要对one_hot编码进行一定程度上的连续性处理,因此选择对one_hot编码做基于高斯的softing处理,如图5-7所示分别为对天soft之后的结果,其他时间数据做同样的softing处理;
第八步:对气象数据做处理,对于风向数据的处理,则根据常用的风向‘北风’、‘东风’、‘南风’、‘西风’、‘东南风’、‘东北风’、‘西南风’、‘西北风’进行8个方向数据插值。对于存在缺失的时间数据,利用上述同样的方法进行基于时间的插值处理;
第九步:地理信息数据处理,城市空气质量指数以及各种污染物的来源除本地排放产生,还有来自本地之外由于气象如刮风携带而来的污染物。如污染物‘pm2.5,pm10’除本地扬尘,烟尘排放等,还会受到沙尘暴的影响,这些因素都会对预报的准确度造成影响。因此,在距中心城市100公里,200公里,300公里处插值出各污染物浓度数值,作为全连接层的特征输入,以提高预报的准确度。
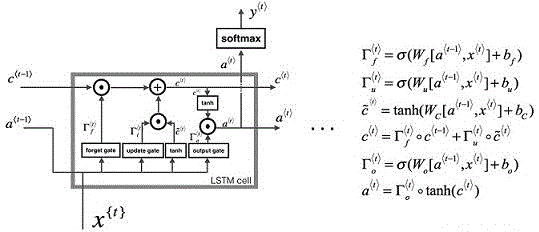
步骤二:神经网络框架的搭建,采用两层lstm+两层全连接fc的网络结构,lstm是长期短期记忆网络,如图1所示,将历史污染物浓度与使用的气象因素区分开来,实现利用lstm网络提取历史污染物浓度的历史变化的时序特征,在第二层lstm网络输出层后面,连接第一层全连接fc层,该fc层的具体输入为lstm层的输出结果、各项气象因素、时间节点编码信息、以及中心城市周围的插值数据信息,第一层隐藏神经元个数为512,第二层全连接层隐藏神经单元个数1024;fc全连接模块包含一层全连接层和输出全连接层,全连接层隐藏神经元个数分别为512,24,lstm网络记忆细胞单元结构。
lstm模块的作用是提取出各项污染的历史信息对未来影响规律,如指标上升或者下降趋势信息,如图2和3所示,
:表示更新门,决定是否用更新替换
:表示遗忘门
:表示输出门
:表示记忆细胞
:表示记忆细胞侯选值
:输出激活值
:sigmoid激活函数
:tranh激活函数
,,,分别表示与遗忘门、更新门、输出门、记忆细胞(同时均与输入x相关)相关的权重矩阵。输入门控制新采样信息是否传输至当前隐藏节点,‘1’表示允许输入,‘0’则不允许,从而实现无用信息的过滤。遗忘门控制历史信息是否保留,‘1’表示保留历史信息,‘0’表示不保留历史信息,从而实现历史节点信息的记忆与清空。输出门控制历史信息是否继续向下一个时间节点传输,‘1’表示允许继续传输,‘0’表示不允许传输,从而实现历史有用信息继续传输,因此,一条信息进入lstm的网络当中,可以根据规则来判断是否有用。只有符合算法认证的信息才会留下,不符的信息则通过遗忘门被遗忘。
步骤三:全连接fc层,影响空气质量的各项污染指标由诸多因素决定,温度、湿度、风向、风力等气象因素都会为污染物的传播扩散产生影响,通过分析个各项污染物的分部信息,可以发现不同污染物在时间分布上呈现随时间变化,时间变化是按照已知规律变化,不需要lstm网络去提取特征,因此只作为全连接的输入,如图4所示,例如污染物‘o3’在以‘小时’为单位的时间信息上规律明显。因此为综合考虑各种影响因素对预测结果准确度的影响,对于这种时间信息也作为特征输入神经网络。
实施例二:
分别对空气质量数据和气象数据做插值、归一化等预处理:具体处理过程如上。对时间等周期性数据做one_hot编码处理以及编码之后softing处理。
训练数据集划分:选用4年历史各项污染物数据作为lstm神经网络的输入,为充分考虑污染物的分布状态,将4年的数据以724为数据片段进行随机打乱。然后按照0.9,0.1的比例划分训练数据与测试数据。将乱序之后的污染物数据输入lstm网络,lstm网络输出连接两层fc。全连接层的输入数据为未来24小时各种气象数据、时间编码数据、以及中心城市周围的插值数据。最终fc全连接层的输出为24小时的预测结果。
训练举例:输入lstm的数据为历史24小时的污染物具体数据,全连接层输入为未来24小时的气象预报数据、时间编码数据,网络最终输出为对应的未来24小时的污染物具体数据。
具体应用进行预测时,输入数据为最近历史24小时的污染物数据,以及对应未来24小时的气象预报数据,网络最终输出结果则是接下来24小时的污染物预测数据。
实施例三:
以北京市为例,预测值与真实值之间的相关性,也即准确度如下:
同时该预报模型具有极强的范化能力,基于任何城市的历史污染无数据,该模型均可进行训练,并且能够实现同等精确度的预报。在空气质量预报,污染物防治领域具有十分重要的社会价值。
综上所述:本基于ai技术的空气质量短期高精度预测模型,实现利用lstm网络提取历史污染物浓度的历史变化的时序特征,在第二层lstm网络输出层后面,连接第一层全连接fc层,该fc层的具体输入为lstm层的输出结果、各项气象因素、时间节点编码信息、以及中心城市周围的插值数据信息。最后一层全连接fc层为模型的输出层,该层实现将上述各层的输出压缩为24个节点,每个节点对应一个小时的预测输出结果,从而实现以小时为单位的空气质量预报,最终该预报模型能够实现以小时为单位的污染物短时高精度预报。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!