一种基于FPGA的卷积神经网络加速系统的制作方法
本发明属于神经网络计算技术领域,具体涉及一种基于fpga的卷积神经网络加速系统。
背景技术
随着深度学习技术的不断成熟,卷积神经网络被广泛用于计算机视觉、语音识别、自然语言处理等领域,并且在人脸检测、语音识别等实际应用场景中取得了不错的效果。近年来,由于规模不断壮大的可训练数据集和不断创新的神经网络结构,卷积神经网络的准确度和性能都得到了显着提高,但是随着卷积神经网络网络结构变得越来越复杂,在实际应用场景中对高实时性、低成本的要求越来越高,对于运行神经网络的硬件的计算能力和能耗的要求也越来越高。
fpga具有计算资源丰富、灵活性较高和能源效率高等特点,而且与传统数字电路系统相比,具有可编程、高集成度、高速和高可靠性等优点,已不断被尝试用来加速神经网络。opencl是基于传统c语言的异构计算语言,可运行在cpu、gpu、pfga和dsp等加速处理器上,具有较高的语言抽象层次,程序员不必了解硬件电路及底层细节就可以开发出高性能的应用程序,大大减少了编程过程的复杂性。
2012年11月,altera公司正式推出了集fpga的强大并行体系结构以及opencl并行编程模型于一体,用于在fpga上进行opencl开发的软件开发套件(sdk),熟悉c语言的程序员利用该软件开发套件能够很快的适应并掌握在opencl高级语言环境下实现高性能、低功耗、高功效的开发fpga应用的方法。采用alteraopenclsdk在fpga上加速卷积神经网络的计算,fpga作为宿主机的外部加速器,能够实现宿主机与外部fpga加速器的协同工作。
技术实现要素:
针对现有技术的以上缺陷或改进需求中的至少一点,本发明提供了一种基于fpga的卷积神经网络加速系统,其目的在于对已有的卷积神经网络计算结构进行重新调整以充分挖掘卷积神经网络在计算过程当中的并行性以及各计算层之间的流水性,提高卷积神经网络的处理速度。
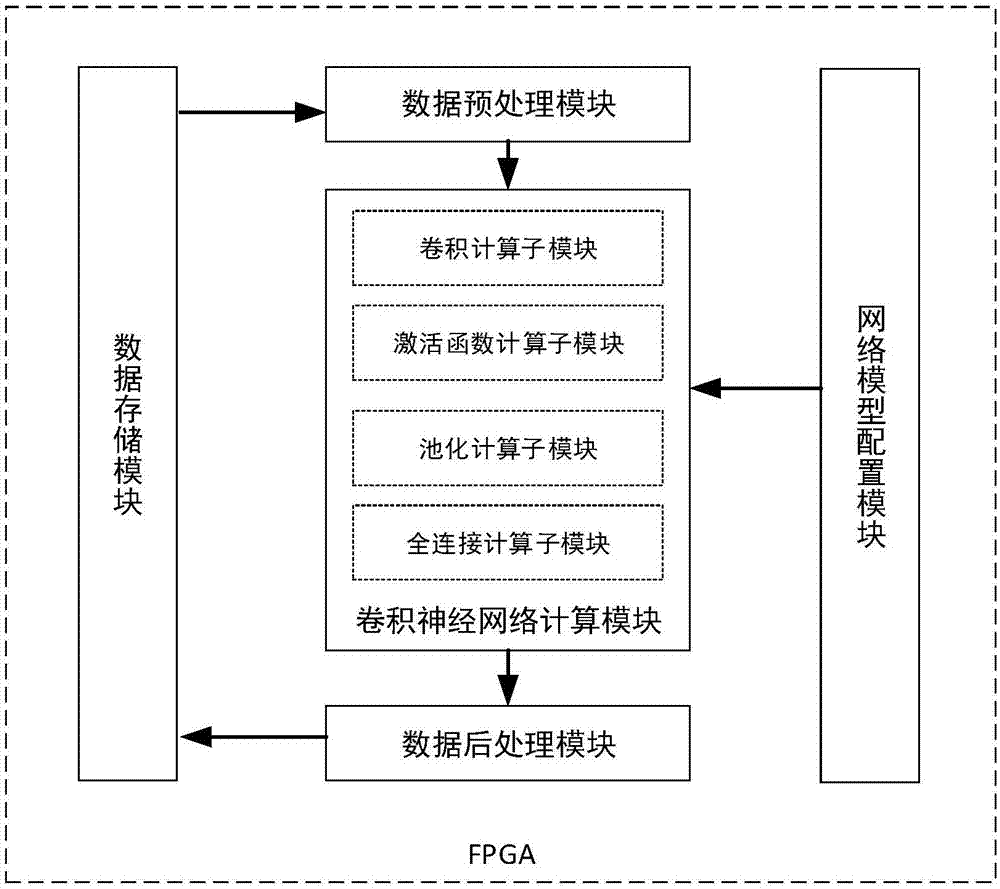
为实现上述目的,按照本发明的一个方面,提供了一种基于fpga的卷积神经网络加速系统,包括数据预处理模块、卷积神经网络计算模块、数据后处理模块、数据存储模块和网络模型配置模块;其中,数据预处理模块、卷积神经网络计算模块和数据后处理模块基于fpga实现,数据存储模块基于fpga的片外存储实现,网络模型配置模块基于fpga的片上存储实现;
其中,数据预处理模块用于根据当前所处的计算阶段从数据存储模块中读取相应的卷积核参数和输入特征图,并对卷积核参数和输入特征图进行预处理:将4维卷积核参数整理成3维,并对输入特征图利用滑动窗口展开并复制,使得滑动窗口中的局部特征图与卷积核参数一一对应,获得便于直接计算的卷积核参数序列和局部特征图系列;预处理完成后将处理好的卷积核参数和输入特征图发送到卷积神经网络计算模块;
网络模型配置模块用于对卷积神经网络计算模块进行参数配置;所述卷积神经网络计算模块将卷积神经网络中的卷积层、激活函数层、池化层和全连接层独立设置,通过参数配置来构建多种不同的网络结构,并根据配置参数对接收自数据预处理模块的卷积核参数和输入特征图进行卷积、激化、池化和全连接计算的层间流水处理,层内则为并行处理;处理结果发送到数据后处理模块;
数据后处理模块用于将卷积神经网络计算模块的输出数据写入到数据存储模块中;
数据存储模块用于存储卷积神经网络的模型参数caffemodel、中间特征图计算结果和最终计算结果,数据存储模块模块通过pcie接口与外部宿主机进行数据交换。
优选的,上述的卷积神经网络加速系统,其卷积神经网络计算模块包括卷积计算子模块、激活函数计算子模块、池化计算子模块和全连接计算子模块,卷积神经网络计算模块内部的这些子模块之间根据网络模型配置模块预定义的网络模型配置参数来连接;
卷积神经网络计算模块接收到数据预处理模块发送的卷积核参数和特征图后,根据配置参数组织好的各个子模块即开始进行处理,处理完成后将结果发送到数据后处理模块;
具体地,卷积计算子模块利用输入的卷积核参数和特征图进行卷积计算,将结果发送到激活函数计算子模块;
激活函数计算子模块根据网络模型参数配置模块预定义的激活函数配置参数选择激活函数,利用选定的激活函数对特征图进行激活计算,完成后根据参数配置将结果发送到池化计算子模块或者全连接计算子模块中;
池化计算子模块用于对接收的特征图进行池化计算,并根据网络模型配置模块预定义的配置参数将池化结果发送到全连接计算模块,或直接发送到数据后处理模块;
全连接计算子模块用于对接收的特征图进行全连接计算,将全连接结果发送到数据后处理模块。
优选地,上述的卷积神经网络加速系统,其数据预处理模块包括数据传输子模块、卷积核参数预处理子模块和特征图预处理子模块;
其中,数据传输子模块用于控制特征图和卷积核参数在数据存储模块与卷积神经网络计算模块之间的传输;卷积核参数预处理子模块用于对卷积核参数进行重排、整理处理;特征图预处理子模块用于对特征图进行展开、复制和整理处理。
优选地,上述的卷积神经网络加速系统,其数据存储模块包括卷积核参数存储子模块、特征图存储子模块,卷积核参数存储子模块用于存储卷积核参数,特征图存储子模块用于存储输入特征图和计算过程中的临时特征图;这些存储子模块优选均由与fpga连接的ddr存储器划分而成,在opencl编程框架中,数据存储模块被作为全局内存来使用。
优选地,上述的卷积神经网络加速系统,其数据传输子模块包括ddr控制器、数据传输总线和存储缓存;
其中,ddr控制器用于控制数据在ddr与fpga中间的数据传输,数据传输总线连接ddr与fpga,是数据传输的通道;存储缓存用于暂存数据、减少fpga对ddr的读取,提高数据传输速度。
优选地,上述的卷积神经网络加速系统,其卷积计算子模块包括一个或多个矩阵乘法计算子模块;矩阵乘法计算子模块的数量由网络模型配置模块预定义的配置参数设定;各个矩阵乘法计算子模块之间的计算是并行执行的;
矩阵乘法计算子模块使用winograd最小滤波算法来加速运算,用于计算获取单个卷积核与对应的局部特征图之间的矩阵乘法。
优选地,上述的卷积神经网络加速系统,其激活函数计算子模块包括激活函数选择子模块、sigmoid函数计算子模块、tanh函数计算子模块和relu函数计算子模块;
激活函数选择子模块分别与sigmoid函数计算子模块、tanh函数计算子模块和relu函数计算子模块相连,特征图的数据发送到这三个计算子模块中的一个;
其中,激活函数选择子模块用于设定卷积神经网络中特征图的激活计算方式;
sigmoid函数计算子模块用于进行sigmoid函数的计算;tanh函数计算子模块用于进行tanh函数的计算;relu函数计算子模块用于进行relu函数的计算。
优选地,上述的卷积神经网络加速系统,其池化计算子模块包括由两个fpga片上存储构成的双缓存;
用于存储池化计算过程中的临时特征图数据,缓冲区大小由网络模型参数配置模块预定义的网络配置参数设定,不同池化层的缓冲区大小不一样,通过这种双缓存区结构来实现乒乓读写操作,实现池化计算的流水处理。
优选地,上述的卷积神经网络加速系统,其网络模型参数配置模块由fpga片上存储实现,用于存储网络模型配置参数,包括网络输入特征图的尺寸大小、卷积计算子模块中卷积核参数的尺寸和数量、池化计算子模块中池化窗口大小、全连接计算子模块的参数规模、计算并行度;网络模型参数配置模块中的数据优选在系统启动之前预先写入。
优选地,上述的卷积神经网络加速系统,其卷积神经网络计算模块由卷积计算子模块、激活函数计算子模块、池化计算子模块、全连接计算子模块根据网络模型配置参数级联而成,这些子模块间使用openclchannel进行数据传输,这些子模块内的计算是并行执行的,这些子模块间的计算是流水进行的。
本发明提供的上述基于fpga的卷积神经网络加速系统,结合卷积神经网络模型结构特点和fpga芯片特点及opencl编程框架的优势,对已有的卷积神经网络计算结构进行重新调整并且设计相应的模块,充分挖掘卷积神经网络在计算过程当中的并行性以及各计算层之间的流水性,使之更匹配于fpga的设计特点,合理高效地利用fpga设计的计算资源,提高卷积神经网络的处理速度。总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
(1)本发明提供的基于fpga的卷积神经网络加速系统,利用卷积神经网络各层的计算特性设计了适于一种流水线处理、并行计算的系统架构;将数据预处理模块、卷积神经网络计算模块和数据后处理模块组成一个流水线结构;通过数据预处理模块与数据后处理模块控制存储模块与计算模块之间的数据传输,卷积核参数和特征图依次通过流水线结构中的三个大模块完成数据读取、数据计算和数据存储的流水过程;并将卷积神经网络中的卷积层、激活函数层、池化层和全连接层分别设计成单独的计算模块,通过参数配置来构建多种不同的网络结构;以将卷积神经网络的各个子模块的处理拆分成许多小的处理过程,每一层对应的子模块的数据都会经历数据读取、数据处理、数据存储等不同的阶段,形成类似于计算机指令流水线形式的流水线结构;使得神经网络层内的计算可以并行执行、层间的计算可以流水执行,可有效的提高卷积神经网络的处理速度。
(2)本发明提供的基于fpga的卷积神经网络加速系统,基于卷积神经网络计算中的卷积核参数、局部特征图之间的数据低关联特性,在卷积计算子模块的并行计算结构中,每次计算时有卷积核与输入特征图对应窗口的数据进行计算,在这种架构下,由于卷积核之间的计算数据没有关联,可以并行进行多个计算处理;而在传统的卷积计算过程中,输入特征图的数据是通过滑动窗口的形式获取的,滑动窗口在特征图上滑动获取相应卷积窗口内的数值,在本发明的并行计算结构中,将滑动窗口去掉并直接将原先滑动窗口中的数据铺展开来形成多个数据块,计算时直接输入相应的数据块,这种方式将多个数据块同时与卷积核进行计算,进一步提高了处理速度。
(3)通过本发明提供的基于fpga的卷积神经网络加速系统,可实现在卷积神经网络的计算过程中如果数据进入到池化计算子模块,可以进行部分池化计算;由于多个卷积核的计算是并行的,所以可以同时产生部分通道上的部分结果,也就是说池化计算子模块的部分输入已经产生了;池化计算子模块的计算和卷积计算子模块一样都是以滑动窗口为单位进行计算的,因此当池化计算子模块中的某个窗口内的数据全部获得后即可开始池化操作而不用等卷积计算子模块的所有计算完成后再开始池化操作;卷积计算子模块可以同时产生多个通道上数据,而且池化计算时通道与通道间没有关联,所以池化计算子模块中各个通道上的计算可以并行进行,极大提高卷积神经网络的处理速度。
(4)本发明提供的基于fpga的卷积神经网络加速系统,网络模型参数可配置,使用配置文件来设置网络模型的结构和网络计算中的并行度,使得不同种类的网络模型和不同计算能力的fpga能够通过参数配置运行卷积神经网络。
(5)本发明提供的基于fpga的卷积神经网络加速系统,其优选方案在卷积层的计算过程中采用了winograd最小滤波算法,可起到加速卷积计算的作用;
在池化层的计算过程中采用乒乓缓冲区,可起到加速池化计算并减少存储空间的使用的作用;
在全连接层的计算中采用了批量计算的方法,可达到减少计算过程中对外部存储空间的访问的目的,并且采用了分段计算,可起到简化高维的矩阵乘法运算的作用,提升处理速度,降低对fpga硬件运算能力的要求;
采用opencl内核程序来实现卷积神经网络中的各个计算模块,可减少开发难度。
附图说明
图1是本发明提供的基于fpga的卷积神经网络加速系统的一个实施例的架构示意图;
图2为实施例中的数据预处理模块的处理示意图;
图3为实施例中的卷积计算子模块的处理示意图;
图4为实施例中的激活函数计算子模块的处理示意图;
图5为实施例中的池化计算子模块的处理示意图;
图6为实施例中的全连接计算子模块的处理示意图;
图7为实施例中的数据后处理模块的处理示意图;
图8为实施例中的加速系统的处理流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
参照图1,本发明提供的基于fpga的卷积神经网络加速系统的一个实施例包括数据预处理模块、卷积神经网络计算模块、数据后处理模块、数据存储模块和网络模型配置模块;
其中,数据预处理模块的输入端与数据存储模块相连,卷积神经网络计算模块的输入端与数据预处理模块的输出端,数据后处理模块的输入端与卷积神经网络计算模块的输出端相连,数据存储模块的输入端与数据后处理模块的输出端相连;卷积神经网络计算模块还与网络模型配置模块相连;
其中,数据预处理模块用于根据当前所处的计算阶段从数据存储模块中读取相应的卷积核参数和输入特征图,并对卷积核参数和输入特征图进行预处理,将4维卷积核参数重新整理成3维的,并对输入特征图利用滑动窗口将其展开并复制,使得滑动窗口中的局部特征图与卷积核参数一一对应,获得便于直接计算的卷积核参数序列和局部特征图系列,预处理完成后将处理好的卷积核参数和输入特征图发送到卷积神经网络计算模块;
网络模型配置模块用于对卷积神经网络计算模块进行参数配置;卷积神经网络计算模块用于根据配置参数对接收自数据预处理模块的卷积核参数和输入特征图进行重排处理,并将处理结果发送到数据后处理模块;
其卷积神经网络计算模块包括卷积计算子模块、激活函数计算子模块、池化计算子模块和全连接计算子模块,卷积神经网络计算模块内部的这些子模块之间根据网络模型配置模块预定义的网络模型配置参数来连接;
数据后处理模块用于将卷积神经网络计算模块的输出数据写入到数据存储模块中;
数据存储模块用于存储卷积神经网络的模型参数caffemodel、中间特征图计算结果和最终计算结果,该模块通过pcie接口与外部宿主机进行数据交换。
参照图2,数据预处理模块从数据存储模块中读取卷积核参数和输入特征图,读取卷积核时根据模型参数配置模块中预定义的参数读取parallel_kernel个尺寸大小为k*k*ci的卷积核,其中ci表示输入特征图的通道数。读入卷积核后开始对卷积核进行序列化操作,即将尺寸为k*k*ci*parallel_kernel的四维卷积核排列成尺寸大小为k*k*(ci*parallel_kernel)的三维形式。
处理输入特征图时,首先将尺寸大小为h*w*ci的特征图读入,然后根据特征图上滑动窗口的大小和移动步长将特征图铺展开来,展开后的特征图的尺寸大小为((w-k)/stride+1)*((h-k)/stride+1)*ci。
输入特征图展开后,根据配置参数截取尺寸大小为(parallel_feature_w)*(parallel_feature_h)*ci的部分特征图,将截取的特征图复制多份,使其数量与卷积核的数量相同,最终得到了尺寸大小为(parallel_feature_w)*(parallel_feature_h)*(ci*parallel_kernel)的特征图,以使多个卷积核与特征图的计算能够并行。在卷积核和特征图处理完成后,将处理后卷积核参数与特征图发送到卷积神经网络计算模块进行处理。
卷积神经网络计算模块的卷积计算子模块的处理流程参照图3,该模块的输入为数据预处理模块生成的卷积核参数和特征图以及网络模型配置模块中预定义的相关配置参数。预处理后的卷积核和特征图均为三维矩阵,通道数都是parallel_kernel*ci;将每一个通道上的卷积核和特征图分别输入到不同的opencl计算单元中使用winograd矩阵乘法子模块进行二维矩阵乘法运算,opencl计算单元之间的计算可以并行进行,计算结果是长为(parallel_feature_w/k)、宽为(parallel_feature_h/k)、通道数为(ci*parallel_kernel)的特征图。输入的特征图经过卷积计算子模块的处理后产生该卷积层的部分输出特征图,该部分输出特征图会根据下一层的类型进行不同的处理。如果网络模型配置中预定义的下一层是卷积层或者全连接层,那么输出特征图跳过池化层由数据后处理模块将结果写回到外部存储中等待处理;如果网络模型配置中预定义的下一层是池化层则将输入特征图发送到池化计算子模块中进行池化处理。
参照图4,实施例中的激活函数计算子模块包含一个激活函数选择子模块和三个函数计算子模块,激活函数选择子模块中的选择器由模型配置模块中的配置参数决定,三个函数计算子模块分别对应sigmoid、tanh和relu激活函数的计算。输入的特征图根据激活函数选择子模块决定的路径发送到函数计算子模块中进行激活函数计算处理,处理完成后根据配置参数发送到数据存储模块或者池化计算子模块中。
参照图5,在池化计算子模块中使用两个尺寸大小为pool_size*w的ping-pongbuffer来保存来自激活函数计算子模块的计算结果,其中pool_size和w是配置参数,卷积计算子模块的计算结果首先不断的被填充到buffer1中,在填充过程中即可进行该buffer中的部分池化计算,在buffer1被填充满后,卷积计算模块的计算结果被填充到buffer2中,在buffer2的填充过程中可以对buffer2内的数据进行池化计算,同时buffer1和buffer2之间的数据也可以进行池化计算,当buffer2被填充满时,卷积计算模块的计算结果又填充到buffer1中,两个buffer就这样交替工作直到整个池化计算完成。在两个buffer之间还包含有池化窗口,该窗口的数据来自两个buffer,在其中一个buffer进行计算操作而另一个buffer进行填充操作时就可以进行两个buffer中间的池化窗口的计算。由于池化窗口间的数据没有计算关联性,所以可以使用循环展开方法使得不同窗口内的计算同步进行。
参照图6,池化计算子模块在处理过程中,将n个输入向量构成的输入矩阵横向分为dim1/m段,其中n表示输入特征向量的数量,dim1表示输入特征向量的维数,m表示输入特征向量的分段长度,每一段单独构成一个大小为m*n的子矩阵,子矩阵分别与权值矩阵中的对应部分相乘即可得到大小为n*n的子矩阵构成的部分结果,dim1/m段的部分结果合并就是最终的n的输出向量构成的计算结果,在计算子矩阵与权值矩阵中的对应部分的矩阵乘法运算时,使用winograd最小滤波矩阵乘法进行加速计算。
参照图7,当卷积神经网络计算模块中的池化计算子模块或者全连接计算子模块的处理完成后,数据后处理模块开始将上述池化计算或全连接计算子模块输出的数据写回数据存储模块中,该过程中使用opencl框架中的barrier操作以保证获得全部的计算结果后才开始传输和所有的数据传输完成后才开始下一步处理。
参照图8,是实施例提供的上述加速系统的处理流程,主要包括三大部分;第一部分为内核程序编译过程,为了最大化利用fpga上的计算资源和存储资源,需要设置合适的网络计算并行度参数。实施例中,设置并行度参数的过程是通过程序自动完成的,首先设定卷积神经网络内核程序中的parallel_feature和parallel_kernel初值,然后利用alteraopenclsdk对内核程序进行编译,编译完成后从编译报告中获取资源利用情况,包括存储资源、逻辑资源、计算资源等,如果资源利用没有达到最大,则更新parallel_feature和parallel_kernel的值重新编译,直至获得最大的硬件资源利用,编译完成后得到可以运行在fpga上的硬件程序。
第二部分为参数配置过程,包括网络模型计算参数和模型配置参数,网络模型计算参数直接从caffe的模型文件caffemodel中读取,模型配置参数包括各层的输入特征图尺寸、卷积核的尺寸、池化窗口大小等,参数的配置利用opencl中的clsetkernelarg()函数完成,一下表1以vgg16为例说明了模型配置参数的类型和参数值。
表1模型配置参数的类型和参数值示例
在上表中,activatefunc列中,0表示没有激活函数,1表示采用relu激活函数,2表示采用sigmoid激活函数,3表示采用tanh激活函数;outputdst列中,1表示输出到数据存储模块,2表示输出到池化计算子模块,3表示输出到卷积计算子模块。
第三部分为神经网络的运行过程,当宿主机将图片传输到数据存储模块中后fpga上的系统开始运行,运行完成后数据存储模块将计算结果返回宿主机,没有图片输入时结束运行。
实施例提供的基于fpga的卷积神经网络加速系统在de5a-net开发板上实现了vgg16和alexnet网络模型,并使用尺寸大小为224*224*3的图片数据进行了性能测试,实验数据表明vgg16的处理速度为160ms/image,alexnet的处理速度为12ms/image,优于其他的fpga实现方案。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!