一种基于多示例学习的可疑威胁指标验证方法及系统与流程
本发明涉及网络空间安全领域,特别涉及一种基于多示例学习的可疑威胁指标验证方法及系统。
背景技术:
可疑威胁指标验证是对网络或日志中出现的可疑指标进行恶意性判断,即确定其是否为真实的恶意威胁指标的问题。验证可疑威胁指标,可及时识别网络威胁,保证网络安全。
针对具体的可疑威胁指标,可依据与其相关的情报信息来进行验证。目前,该类型的验证方法主要有三种:一种是基于安全专家的人工验证方法,即利用安全专家分析已收集的相关情报信息,人工确定可疑指标的威胁性;一种是基于规则匹配的验证方法,即简单地利用正则表达式或自定义规则匹配已有的情报信息,根据匹配结果判断可疑指标;一种是基于特定上下文词汇的验证方法,即通过查看情报信息中可疑威胁指标的上下文中是否含有特定的上下文词汇来研判可疑指标是否是真实的恶意威胁指标。
基于安全专家的人工验证方法,往往依赖于安全专家积累的经验,人工分析与整理已有情报信息,人力成本高。
基于规则匹配的验证方法,直接应用正则表达式匹配可疑指标,忽略情报信息中的语义信息,导致验证的误报率较高。
基于特定上下文词汇的验证方法,需要提前收集候选上下文词汇,然后抽取情报信息中的上下文词汇匹配,该方法复杂度高,且候选集的更新如若不及时,则验证的准确率也没有办法保证。
技术实现要素:
针对现有技术的不足,本发明的目的在于提供一种基于多示例学习的可疑威胁指标验证方法及系统,本发明充分利用收集到的多个相关威胁信息,高效准确地完成对可疑威胁指标的验证,为解决可疑威胁指标验证提供一种行之有效的方法和思路。
本发明的技术方案为:
一种基于多示例学习的可疑威胁指标验证方法,其步骤包括:
采用自然语言处理技术对各可疑威胁指标相关的情报信息文本内容进行处理,生成含有原语义信息的词序列,并将各所述情报信息文本中的可疑威胁指标替换成统一的设定短语;各所述可疑威胁指标为同一类别的可疑威胁指标,每一可疑威胁指标对应多个情报信息文本;
对于每一所述可疑威胁指标,选择该可疑威胁指标对应的多个处理后的词序列,应用多示例学习算法对选取的各所述可疑指标对应的词序列进行训练并生成一多示例学习验证模型;
采用自然语言处理技术对待测可疑威胁指标的情报信息文本进行处理,生成该待测可以威胁指标对应的词序列;然后利用所述多示例学习验证模型对该待测可疑威胁指标对应的词序列进行预测验证,确定该待预测可疑威胁指标是否为恶意威胁指标。
进一步的,生成所述多示例学习验证模型的方法为:将每一个所述可疑威胁指标对应的各词序列作为一个包,每一个词序列作为一个示例,生成对应可疑威胁指标的训练集;利用多示例学习算法对各所述训练集进行训练,生成所述多示例学习验证模型。
进一步的,所述多示例学习算法为多示例神经网络模型。
进一步的,所述多示例神经网络模型包括embedding层、子神经网络层和多示例学习池化层;所述多示例神经网络模型首先利用embedding层完成对每个输入的词序列转换为词向量并将其输入到该子神经网络层中,该子神经网络层挖掘与分析所述可疑威胁指标的语义特征;最后该多示例学习池化层根据输入的语义特征对所述可疑威胁指标进行分类验证。
进一步的,该子神经网络层为alexnet或rcnn。
进一步的,每一所述可疑威胁指标对应多个情报信息文本。
一种基于多示例学习的可疑威胁指标验证系统,其特征在于,包括情报信息预处理模块、多示例学习验证模型训练模块和验证模型预测模块;其中,
情报信息预处理模块,用于采用自然语言处理技术对各可疑威胁指标相关的情报信息文本内容进行处理,生成含有原语义信息的词序列,并将各所述情报信息文本中的可疑威胁指标替换成统一的设定短语;各所述可疑威胁指标为同一类别的可疑威胁指标,每一可疑威胁指标对应多个情报信息文本;
多示例学习验证模型训练模块,用于应用多示例学习算法对各所述可疑指标对应的词序列进行训练并生成一多示例学习验证模型;对于每一所述可疑威胁指标,选择该可疑威胁指标对应的多个处理后的词序列用于训练;
验证模型预测模块,用于利用所述多示例学习验证模型对待测可疑威胁指标对应的词序列进行预测验证,确定该待预测可疑威胁指标是否为恶意威胁指标;其中,采用自然语言处理技术对该待测可疑威胁指标的情报信息文本进行处理,生成该待测可以威胁指标对应的词序列。
进一步的,所述多示例学习验证模型训练模块利用多示例学习算法对各训练集进行训练,生成所述多示例学习验证模型;其中,将每一个所述可疑威胁指标对应的各词序列作为一个包,每一个词序列作为一个示例,生成对应可疑威胁指标的训练集。
进一步的,所述多示例学习算法为多示例神经网络模型;所述多示例神经网络模型包括embedding层、子神经网络层和多示例学习池化层;所述多示例神经网络模型首先利用embedding层完成对每个输入的词序列转换为词向量并将其输入到该子神经网络层中,该子神经网络层挖掘与分析所述可疑威胁指标的语义特征;最后该多示例学习池化层根据输入的语义特征对所述可疑威胁指标进行分类验证。
进一步的,每一所述可疑威胁指标对应多个情报信息文本。
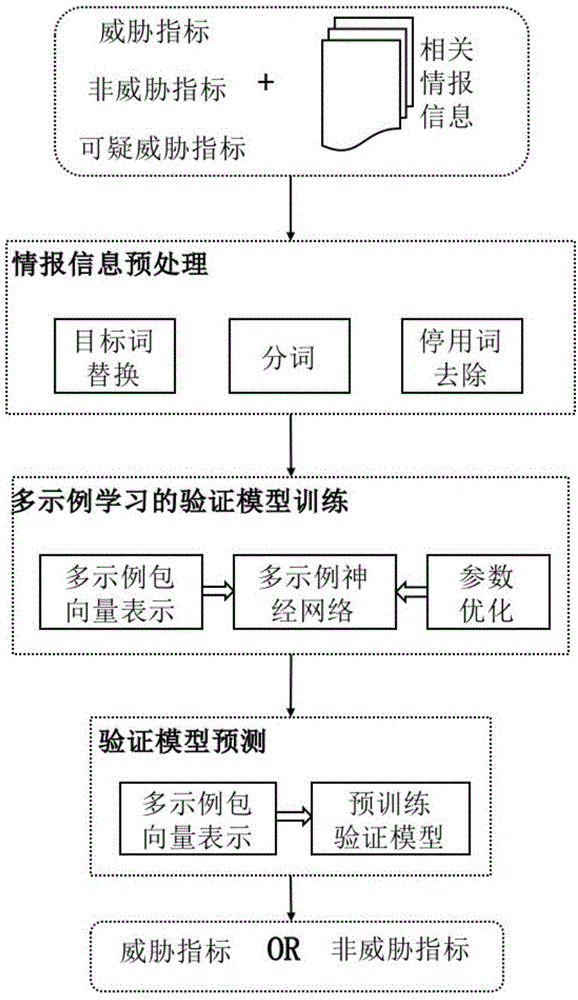
本发明提供了一种基于多示例学习的可疑威胁指标验证方法,如图1所示,主要包括下列步骤:情报信息预处理步骤,多示例学习验证模型训练步骤和验证模型预测步骤。
情报信息预处理步骤,针对提前收集到的与可疑威胁指标相关的情报信息,采用自然语言处理技术处理文本内容,生成含有原语义信息的词序列。
多示例学习验证模型训练步骤,选择同一指标的多个处理后的情报词序列信息,应用多示例学习算法,训练并生成可用的多示例学习验证模型。
验证模型预测步骤,利用上述步骤中训练好的验证模型,和待测可疑威胁指标的情报信息文本对其进行预测验证,确定该待测可疑威胁指标是否为恶意威胁指标。
进一步地,所述情报信息预处理的具体做法为:首先利用正则匹配及替换技术将现有情报信息中的可疑威胁指标识别出并替换成统一的特定短语,避免不同指标命名对验证结果的影响。然后采用自然语言处理中的分词技术对文本信息进行分词,并进行去除停用词等处理,尽可能地保留文本的原语义信息,以便后期学习。
进一步地,所述多示例学习验证模型训练的具体做法为:利用已标注的指标及其相关信息(即训练集)训练验证模型,在训练集中,将每一个指标的所有处理后的相关词序列看作一个“包”,每一个词序列看作一个“示例”,选择多示例学习算法,如多示例神经网络,共同考虑多个示例信息,生成验证准确率较高的验证模型。每一指标有多个不同的样本示例,对多个示例进行分词,处理后的词序列不相同。
进一步地,所述验证模型预测的具体做法为:针对待验证的可疑威胁指标及其相关威胁情报(即测试集),预处理得到其相关的多示例词序列信息,然后利用训练好的验证模型对其恶意性进行预测验证。
本发明的技术关键点在于:
1)定义了一种基于多示例学习的可疑威胁指标验证方法,可低成本、高效准确地对可疑威胁指标做出验证。
2)提供了一种情报信息数据处理方式,处理后得到相关词序列,尽可能地保留信息中的语义信息。
3)利用了多个与可疑威胁指标相关的情报信息,可充分挖掘可疑威胁指标的潜在特征,更加准确地判断其是否是恶意指标。
4)设计了一种多示例神经网络结构,可端到端地自动完成验证,减少人工投入与错误干扰。
与现有技术相比,本发明的积极效果为:
1、本方法对相关的情报信息进行了序列化处理,保留了文本语义信息,可提高可疑威胁指标验证的准确率。
2、本方法综合使用多条相关词序列信息,可加强对可疑指标的主动分析,降低验证的误报率。
3、本方法设计了高效的多示例神经网络结构,可充分挖掘词序列的潜在特征,实现端到端地自动验证,减少开销成本。
4、本方法不单单可应用于简单的可疑威胁指标验证,还可应用于网络威胁情报的ioc指标挖掘,可将准确验证后的威胁指标更新到已有情报库中。
附图说明
图1基于多示例学习的可疑威胁指标验证方法流程示意图。
图2基于多示例学习的可疑威胁指标验证方法模型实例图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要注意的是,在以下描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将会被忽略。
实例1一种基于多示例学习的可疑威胁指标验证方法
本发明可应用于多种类型的可疑威胁指标的自动验证。实例以可疑apt域名为例,说明本发明的具体应用。
针对一些可疑apt域名和与其相关的多篇威胁情报信息,可利用本方法自动验证其是否是apt攻击中的恶意域名。下面是具体步骤:
1)相关情报信息预处理
以一个可疑apt域名“jerrycoper.org”为例说明预处理步骤,现有3篇与其相关的威胁信息报道,首先先匹配每篇报道中的该可疑apt域名,将其替换成“is_apt_domain”特定词组,避免不同的可疑apt域名对后期模型训练的影响。
然后利用自然语言处理的分词工具或分析算法,对每篇文章进行分词处理。最后去除无用的停用词,但尽可能地保留原报道的语义信息,整理得到相对应的词序列,以供后期训练与验证。
2)多示例学习的验证模型训练
选择已有类别标注的域名指标,即已知的apt域名与非apt域名,以及与其相关的处理后的情报词序列作为验证模型的输入,输入到设计好的多示例神经网络模型中,如图2所示。
将单个指标的多个词序列作为“包”整体输入到模型内,模型首先利用embedding层完成对每个词序列的词向量转换。然后转化后的词向量被接入到后续的子神经网络层中,该子神经网络结构灵活,即可直接利用先进的组建好的神经网络,如alexnet,rcnn;也可使用自构建的神经网络,如卷积层和全连接层的组合,该子神经网络是隐形的特征抽取与学习,自动挖掘与分析域名指标的语义特征。最后该多示例学习池化层利用并学习前面的自神经网络学习到的语义特征,对所述可疑威胁指标进行分类验证。
通过上述操作,利用训练集训练后可得到分类效果好的多示例学习验证模型。该模型以域名指标及其情报信息的词序列向量为输入,输出域名指标的验证结果。
3)验证模型预测
有了预训练模型之后,便可对可疑域名指标进行自动验证。针对可疑域名和与其相关的情报信息,先对其进行1)步骤操作,得到相对应的情报词序列。然后将其输入到2)步骤训练好的模型中,模型可自动完成分类验证,输出最后的验证结果。
在具体实验时,我们通过修改模型中的神经网络层结构和多示例学习池化层的池化方法,可得到多种分类验证模型,它们对可疑域名的验证准确率可高达可达92%以上,最高可到98%左右。该实例的实验结果也再一次验证了本发明提出的基于多示例学习的可疑威胁指标验证方法的高效性与准确性。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的研究人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来说,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!