一种基于docker的深度学习管理方法与流程
本发属于云计算虚拟化技术和人工智能深度学习领域,尤其涉及一种基于docker的深度学习管理方法。
技术背景
21世纪以来,人类在人工智能上取得的成果可谓愈加丰硕。深度学习是机器学习的一个分支,目的在于建立一个模拟人脑进行分析学习的神经网络,通过模仿人脑的工作机制来进行数据处理,例如图像通常应用在视频识别、图像识别或者声音识别领域。但面对越来越大的数据,深度学习训练时所需的计算资源越来越大,我们希望使用一套管理平台将这些计算资源进行统一管理和监控,提高计算资源的使用率。
故,针对现有技术的缺陷,实有必要提出一种技术方案以解决现有技术存在的技术问题。
技术实现要素:
本发明的目的在于提出一种基于docker的深度学习管理方法,从而提高深度学习训练时计算资源利用率。
本发明的目的是通过以下技术方案来实现:
一种基于docker的深度学习管理方法,具体包括以下步骤:
步骤s1、通过用户模块提供的服务进行身份认证,登陆后用户选择指定的docker镜像,设置生成docker容器时所需的参数和深度学习模型训练时所需的配置,并向集群模块发送请求以申请特定的资源;
步骤s2、集群模块收到用户模块的请求后,先选择集群内的节点检查当前集群内环境是否有足够资源生成docker;若空余资源不满足要求,任务进行等待,并返回等待原因至用户模块;若空余资源满足要求,集群模块指定本次任务使用的节点,进入步骤s3;
步骤s3、判断步骤s2中集群模块指定的节点是否包含本次任务所需的docker镜像;若各节点均包含所需的docker镜像,进入步骤s4;若存在节点没有所需的docker镜像,节点会向registry模块申请从存储模块中接收所需docker镜像;若registry模块中也没用所需镜像,返回错误信息;若各节点接受完所需的docker镜像,进入步骤s4;
步骤s4、在各个节点中生成新的docker容器并根据设置的深度学习模型训练参数进行训练;
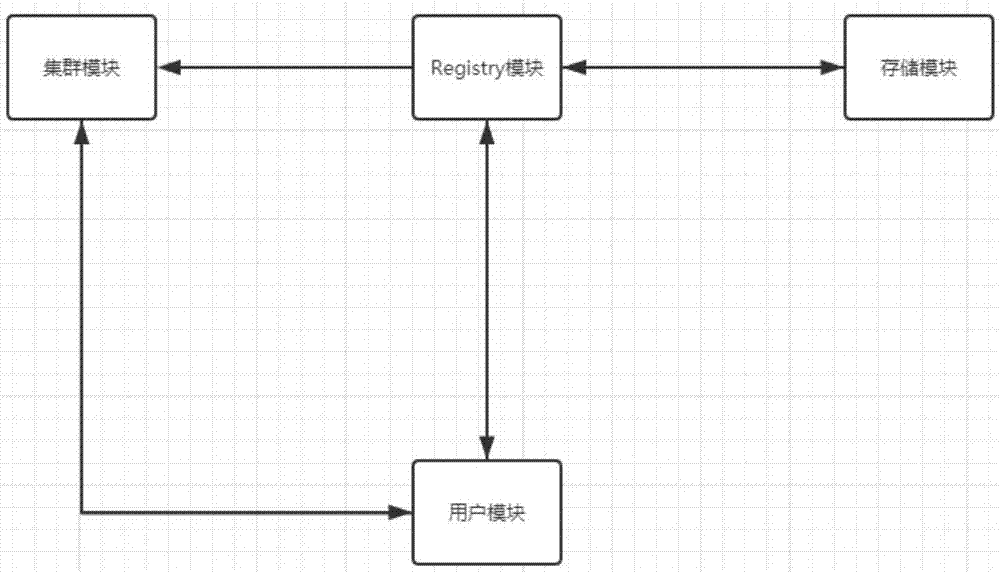
作为优选的技术方案,实现本发明方法的系统架构包括集群模块,registry模块,存储模块,用户模块。所述registry模块用于记录存储模块中保存的docker镜像信息,并在必要时向集群模块中的节点传递docker镜像;所述存储模块用于存储registry模块中记录的docker镜像;所述集群模块由多个节点组成,用于接收用户模块请求,生成包含指定资源的docker容器完成相对于的任务;所述用户模块用于提供身份验证、用户登陆和任务提交服务,可以通过该模块向集群模块申请docker容器来进行深度学习任务。
进一步的,所述registry模块,由linux主机中运行的私有库docker容器实现。registry模块主要负责记录当前存储模块保存的docker镜像,以便后续集群模块中的节点进行下载。当需要上传新的docker镜像时,用户通过用户模块将新的docker镜像进行上传。进一步的,所述集群模块由多个节点组成,用于接收用户模块请求,生成包含指定资源的docker容器完成相对于的任务。集群模块可通过集群软件进行搭建,例如hadoop、etcd等。docker容器在生成后定时向用户模块返回容器的运行情况、日志输出等信息。任务结束后,docker容器自动销毁并将销毁信息返回给用户模块。
进一步的,所述用户模块用于提供身份验证、用户登陆和任务提交服务,可以通过该模块向集群模块申请docker容器来进行深度学习任务。用户模块提供的身份验证、集群监控和任务提交服务均通过web服务的信息实现。通过浏览器访问对应的url可完成身份认证。完成身份认证之后,我们可以在浏览器中观察集群各节点的资源使用情况和网络通信情况等信息,也可以选择指定的资源配置和深度学习任务开始训练。任务训练时,用户模块接收集群模块的信息,实时显示任务的运行情况。
与现有技术相比较,本发明的有益效果为:
1、本发明可以在浏览器中动态的申请指定资源来进行完成任务,操作步骤比单纯使用docker技术更为便捷。
2、在需要更多计算资源时,能够通过集群软件快速添加。
3、以可视化的方式统一管理集群内的资源,大大的提高了集群内计算资源的利用率。
附图说明
图1为本发明基于docker的深度学习管理方法的系统结构框图;
图2为本发明基于docker的深度学习管理方法的流程步骤图;
具体实施方式
下面结合说明书附图和实施例对本发明作进一步限定,但不限于此。
docker是一个开放源代码软件项目,让应用程序部署在软件容器下的工作可以自动化进行。我们可以通过docker技术动态的分配指定的资源,生成特定环境的计算环境。因此,docker镜像为我们动态的管理计算资源,提高计算资源的使用率提供了一种思路。
如图1和2所示,本发明基于docker的深度学习管理方法的系统结构图和流程步骤图,具体包括以下步骤:
s1、用户通过用户模块提供的服务进行身份认证,登陆后用户选择指定的docker镜像,设置生成docker容器时所需的参数(包括但不仅限于gpu数量、cpu核心数和内存大小)和深度学习模型训练时所需的配置(包括但不仅限于网络框架、训练所需数据的路径和训练模型种类),向集群模块申请特定的资源;
s2、集群模块收到用户模块的请求后,先选择集群内的节点检查当前集群内环境是否有足够资源生成docker。若空余资源不满足要求,任务进行等待,一段时间之后,该任务会再次执行s2;若空余资源满足要求,集群模块指定本次任务使用的节点,进入s3。
s3、判断s2时集群模块指定的节点是否包含本次任务所需的docker镜像。若各节点均包含所需的docker镜像,进入s4;若存在节点没有所需的docker镜像,节点会向registry模块申请从存储模块中接收所需docker镜像。若registry模块中也没用所需镜像,返回错误信息;若各节点接受完所需的docker镜像,进入s4。
s4、在各个节点中生成新的docker容器并根据设置的深度学习模型训练参数进行训练。
其中,实现本发明方法的系统架构进一步包括集群模块,registry模块,存储模块,用户模块。
进一步的,所述registry模块,由linux主机中运行的私有库docker容器实现。在registry模块所在的linux主机中安装docker软件,并通过docker的pull命令下载registry镜像,通过该镜像创建私有仓库,以保存当前后续上传至registry模块中的镜像。
进一步的,所述存储模块,由registry模块所在的linux主机实现。我们在registry所在的linux主机中挂在容量较大的硬盘,并将registry模块中的docker镜像存储路径设置在新挂载硬盘对应的路径上。
进一步的,所述集群模块由多个节点组成,用于接收用户模块请求,生成包含指定资源的docker容器完成相对于的任务。集群模块搭建需要多台linux主机。首先,我们将这些主机相互之间进行ssh免密登陆操作,保证各台主机之间可以使用ssh服务免密登陆。其次,我们设置通过当前已有的集群软件将这些linux主机搭建为一个集群。最后,我们需要在集群内的各台linux主机安装docker软件,并实现各主机内和主机间的docker均可进行通信。除此之外,集群模块内主机需要执行相对于的脚本,返回主机和主机内容器的实时信息。
进一步的,所述用户模块可在集群内某一节点中实现,也可以在单独在集群外的linux主机中实现。用户模块主要实现身份验证、用户登陆和任务提交服务功能。我们使用java的一系列框架实现这些功能,并让我们通过浏览器进行访问。
以上实施例的说明只是用于帮助理解本发明的方法及其核心思想。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!