一种相控阵雷达辐射源目标大数据实时关联方法与流程
本发明涉及相控阵雷达辐射源目标关联处理技术。
背景技术
辐射源信息关联是相控阵雷达被动数据处理的重要内容,目标辐射源信息通常包括载频、脉宽、重复周期和到达方位,分别使用rf、pw、pri、doa表示,辐射源数据具有数据量大、目标少、处理速高的大数据特征,有效、准确的数据关联算法直接决定数据实时处理的速度,被动辐射源信息关联权重的选取决定数据处理的质量。
辐射源信息关联处理步骤包括辐射源信号分选和目标编批,首先在交错、密集的复杂脉冲信号中抽取属于同一个雷达辐射源目标的脉冲序列,其次对分选得到的辐射源目标进行关联滤波。被动雷达数据处理的难点在于如何获取合适的关联权重。
目前,传统方法依赖现场人员的主观经验,不能适应复杂变化的外场电磁环境,存在随机性太大、缺乏一致性检验的情况,容易造成被动辐射源目标丢失、分裂和增殖等情况。国内外关于辐射源目标关联方法的研究中,主要集中在聚类、动态关联、启发式算法等方面,存在算法复杂度高造导致的处理效率下降的情况。
层次分析法是20世纪70年代美国运筹学家t.l.satty提出的一种定性与定量相结合的决策分析方法,通过两两比较的方式构建决策判断矩阵,再综合确定各因素重要程度,给权重计算带来便利。信息熵是1948年由shannon研究信息度量问题时提出的,是不确定性和信息量的测度;熵权法根据某指标评价差异越大,熵就越小,其指标的重要性越大的原理进行权值计算,体现其权值计算的客观性。两种方法具有数学理论支撑,且算法复杂度低。
本发明设计了相控阵辐射源目标数据实时关联处理流程,特别针对权重计算提出了区别于一般层次分析法和基于信息熵的数据挖掘方法的两种权重快速计算方法。本发明提出四种调整策略改进层次分析法,克服层次分析法依赖大量专家对权重重要性投票的缺陷,能够在获得一个基本相对重要性矩阵后,根据专家给出的初始判断结果,自动调整相对重要性判断矩阵,从而搜索得到具有一致性的权重;本发提出一种冲突消解和噪声生成策略改进基于信息熵的数据挖掘方法,克服训练样本数据抖动较大以及样本量较少情况下,基于信息熵方法得到的权重受野值影响不能反映辐射源统计特性难题。
技术实现要素:
本发明的目的是:提供基于改进的层次分析法与信息熵挖掘法的相控阵辐射源数据实时关联算法,解决被动辐射源目标关联权重缺乏一致性和计算复杂度高的难题,提高数据处理效率,抑制目标分裂和丢失。
本发明的解决方案是:根据使用场景更新评价因素集合;首先利用改进的层次分析法获得一个通过一致性检验的基准权重,该步骤仅执行一次;程序关联部分利用基准权重和信息熵挖掘得到的个性权重更新关联权重,实现辐射源目标的关联,并更新存储辐射源目标的数据作为信息熵方法的训练样本;最后利用改进的信息熵计算辐射源目标个性权重,当辐射源目标关联的次数较多时,根据需要使用改进的信息熵挖掘个体目标的关联权重,实现目标个性化权重动态更新,该步骤在实际操作中每获得50更新时执行一次挖掘计算。
本发明利用整体扩大相对重要性判断结果、整体缩小相对重要性判断结果、大值放大小值缩小、大值缩小小值放大四种策略调整初始重要度判断矩阵,改进层次分析法对专家数量的要求,并通过迭代计算获得关联权重;在对训练样本进行处理时,首先通过统计被动辐射源诸要素的分布特征,其次在样本量较少使用基于正态分布假设的蒙特卡洛进行数据仿真获得较多的训练样本,再次对数据进行特征分布检验,排除数据野值降低个别数据对权重计算的影响,最后利用信息熵方法计算诸要素的权重。
本发明的有益效果:(1)能够避免专家主观经验对权重选取造成的争议;(2)能够获得通过数学一致性检验的权重,具有理论完善、定性定量结合、可信度高的特点;(3)改进的层次分析方法具有自适应性,能够反应专家的判断倾向,同时降低对专家数量的需求;(4)改进的信息熵挖掘方法能够在样本量不足条件下提供基于蒙特卡洛仿真仿真数据,并利用数据分布特征剔除野值。
下面结合附图对本发明做进一步详细的描述。
附图说明
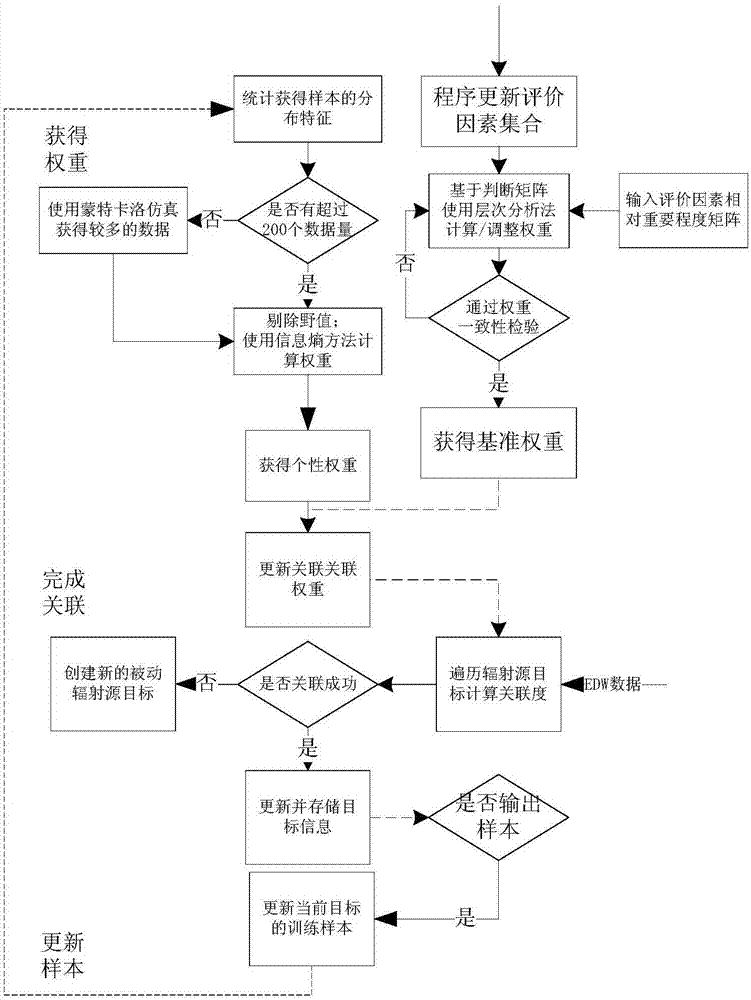
图1被动辐射源数据处理的整体流程。
图2梯形相似度计算图。
图3改进的ahp方法权重计算流程。
图4-7相对重要程度调整策略示意图。
图8基于概率论和蒙特卡洛方法改进权重挖掘处理流程。
具体实施方式
1)被动数据源数据处理流程;
设计相控阵雷达辐射源目标大数据实时关联处理流程,如图1所示。此处利用wrf、wpw、wpri、wdoa分别表示载频、脉宽、重复周期和到达方位的关联权重,改进的层次分析法和信息熵挖掘方法具体计算步骤见2)。
首先根据使用场景使用者动态调整辐射源目标的要素信息,其次利用改进的层次分析法获得辐射源目标的基准关联权重,如wbase={wrfbase,wpwbase,wpribase,wdoabase},关联程序利用信息熵方法计算得到的个性关联权重wobj={wrfobj,wpwobj,wpriobj,wdoaobj},实时更新w={wrf,wpw,wpri,wdoa}方法是:
在辐射源目标刚开始进行关联处理时:
w=wbase
在当前目标持续更新一定的数据量后,利用信息熵处理挖掘得到个性关联权重:
w=a*wbase+(1-a)wobj
其中a∈(0,1],此处取值a=0.8。
在获得了目标关联权重后利用梯形相似度公式实现辐射源目标信息要素的去量纲化,结合图2,具体以载频(rf)为例:
其中rfmax、rfmin分别表示最大、最小载频值,δrf表示当前载频值。重复周期、脉宽、到达方位计算方法类似。
然后计算辐射源目标与辐射源信息的关联度wval:
wval=wrf·drf+wpw·dpw+wpri·dpri+wdoa·ddoa
在关联度wval小于0.9时,认为关联失败,并创建临时辐射源目标,临时辐射源目标连续3个周期没有更新则删除。到此完成辐射源目标的关联更新和编批。
在获得了较多的训练样本后,存储在本地,提供训练使用
2)权重快速计算方法
针对改进的层次分析和信息熵方法计算权重的过程分别给予说明。
(1)改进的层次分析权重计算
层次分析法依赖专家建立相对重要性互反判断矩阵
第一种策略是重要程度矩阵上三角乘以大于1的系数放大,同时改变下三角的值。该系数按照满足下式的模糊性的式子进行计算:
y=a*exp(-x2*b)
其中a表示最小重要性程度对应的系数(图例中取值1.5),d表示最大重要性程度对应的系数(图例中取值1),b=-log(d/a)/e表示一个修正系数,其中e表示最大重要性程度取值,通常取值9。如图4所示。
第二种策略是重要程度矩阵上三角乘以系数d<1缩小,原理类似第一种。如图5所示。
第三种策略是小于中位数的重要度判断值乘以小于1的值缩小,大于中位数的判断值乘以大于1的值放大,其公式为:
其中f是中位数,b1=-log(a)/f2,b2=-log(d)/(9-f)2。如图6所示。
第四种策略是小于中位数的重要度判断值乘以大于1的值放大,大于中位数的判断值乘以小于1的值缩小,其公式为:
其中f是中位数,b1=-log(d/a)/f2,b2=-log(d/a)/(9-f)2。如图7所示。
(2)改进的数据挖掘权重计算
首先对户提供的训练样本中的信息要素进行统计,基于信息熵的权重计算方法首先统计得到样本中每个要素的均值和方差统计值,在样本量不足时,使用蒙特卡洛方法模拟被动辐射源噪声,使样本量达到至少200个,当辐射源目标信息要素值的在3倍外则认为是野值并剔除,防范野值对数据污染导致权重计不能反映数据本身的分布特征。如图8所示。
在对数据进行处理后,利用信息熵方法对辐射源数据首先进行归一化:
其次计算辐射源信息要素j的信息熵:
最终得到射源信息要素j的权重:
- 还没有人留言评论。精彩留言会获得点赞!