基于图像目标检测的物流车辆车型分类识别方法与流程
本发明涉及一种图像目标检测的方法,特别涉及一种物流车辆车型分类的图像智能识别的方法。
技术背景
近年来随着交通物流的发展,越来越多的物流车辆服务于我们的工作和生活中。但这也造成了一个问题,过多的物流工程车辆,导致园区的物流车辆停放管理难度系数加大。
据不完全统计,日本的物流企业就曾因物流车辆识别不准确,每年对企业造成的经济损失高达十几兆亿日元,德国也这一问题上造成的经济损失高达1100亿欧元,而美国,这一数字已经达到了1300亿美元。我国的物流企业也存在上述问题,严重时,甚至物流企业造成灾难性的损失。由此可见,对配送在配送过程中实施精确控制和管理,就能够在一定程度上减少企业的运输成本。从这一点来说,准确的识别出配送物资的具体车辆,就更有重要的意义。从管理的角度来看,识别物流车辆类型是一种轻便、有效、准确、科学的管理方法,大大减少了人力、物力、财力的投入。
目前主要有以下几个方式的车型识别方法:一、申请号:201410489933.1申请日:2014.09.23的文件介绍了一种基于多特征融合的车型分类方法。首先对视频中的车辆进行检测并定位与分割,经过形态学处理,提取三种融合信息,利用支持向量机方法训练分类器;二、在申请号为:201610511830.x申请日为:2016.07.01的文件中,提到了道路车型分类方法,将视频图像输入至卡尔曼滤波器中,得到最优帧,将最优帧输入至卷积神经网络中,得到高维特征向量,将高维特征向量输入车型分类模型中,得到车型分析结果。
以上提到的方法也存在不足之处,如方案一,提取车辆图像的三种特征,特征提取采用三种模型,设计复杂度较大;方案二,只大致划分了车辆类型,大汽车、大suv、摩托车、小suv、小汽车这五类,并没有进行细致划分,而识别出的车辆类型只是基于整张图像,并没有定位出来。
技术实现要素:
为了解决现有技术的不足,本发明提供一种基于图像目标检测的物流车辆车型分类的识别方法,这种方法精准有效、成本低、智能化、操作简单。
为实现上述目的,本发明采用以下技术方案:
基于图像目标检测的物流车辆车型分类的识别方法,包括如下步骤:
步骤一,通过视觉设备获取物流园区的实时影像;
步骤二,数据增强工作,在图片的指定位置对采集的物流车辆图像进行裁剪,并将图片缩放到固定的像素:宽为w,高为h;
步骤三,将统一大小的图片,经过图片数据批量标准化处理,具体过程如下:
步骤3.1确定每次处理的图片数量为m张,每张图片包含有宽高的像素点信息,定义图片集合:
x=[x1,x2,kxi...,xm](1)
式(1)中,x为该批次图片的集合;xi为第i张图片的所有像素信息;
用以下表达式将每张二维图片像素信息按照从左往右,从上到下顺序平摊为一维像素信息:
xi=[xi1,xi2,k,xilk,xiη],1≤i≤m,1≤l≤η(2)
式(2)中η=w*h,表示一张图片像素信息的总长度;xil表示第i张图片的第l位置的一维像素信息;
通过将每张图片的一维像素信息缩放为0到1,得到白化处理的结果:
ci=xi/255;(3)
式(3)中ci为一张图片像素白化结果;图片集合x的白化处理结果矩阵为:
cx=[c1,c2,kci,kcm](4)
式(4)中cx为该批次图片的白化结果集合;
步骤3.2计算图片集合白化处理结果矩阵cx的均值:
式(5)中,k表示当前批次;e[ci]表示当前批次中第i张图片白化处理结果的均值,即:
步骤3.3计算图片集合白化处理结果矩阵cx的方差:
式(7)中
步骤3.4进行图片数据批量标准化处理,用于加快网络训练:
式(8)中
步骤四,对所述当前批次k的图片数据批量标准化结果重新转换回二维数据,即宽为w、高为h,进行卷积操作:
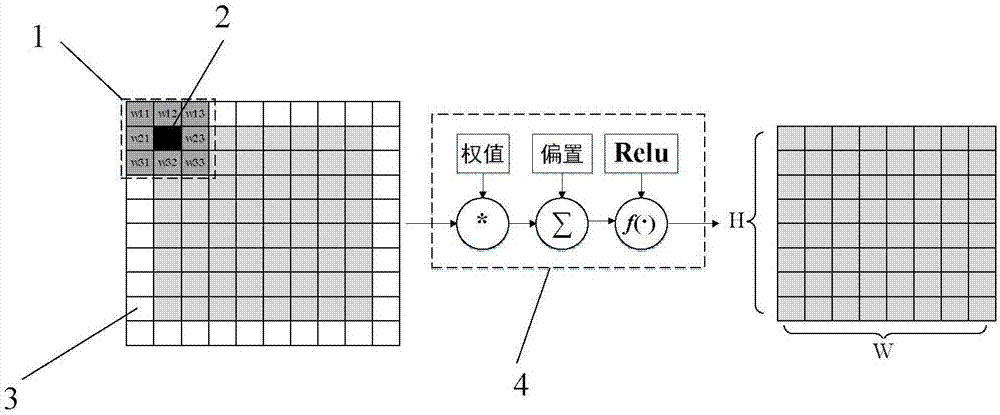
步骤4.1设定方形卷积核的边长大小值为size,设定卷积核核心起始位置为所述二维数据矩阵左上角第一个位置,设定卷积核滑动的距离为stride,设定滑动顺序为从左到右,从上到下;
步骤4.2设定隐含层神经元的节点个数node1,用于表示卷积核对所述当前批次二维数据进行卷积操作,实现加权求和,提取拥有节点个数的图片细节特征,卷积的计算公式为:
式(9)中r为卷积核核心在二维数据矩阵的横坐标,c为卷积核核心在二维数据矩阵的纵坐标,kernelsize×size表示设定的卷积核,bias表示实现加权求和的偏置;
步骤五,需要对卷积操作后的特征进行激活,有目的地将有用的图片特征信息表达出来,通过给定的relu滤波器,将大于某阈值的有用信息进行激活处理,小于阈值的进行抑制,其relu滤波器激活公式为:
activerc=max(0,converc)(10)
式(10)中activerc为激活后的对应坐标特征数据,最终激活后的坐标数据矩阵记为active,max(0,converc)为滤波激活函数,即矩阵中数值以所述阈值为0进行滤波,取当前值和阈值中的最大值;
步骤六,将激活后的active数据矩阵进行池化降维操作,提高特征计算效率,池化降维操作采用最大池化操作,计算公式为:
式(11)中kernelsize×size为设定的池化核,
w'=w/stride,h'=h/stride(12)
式(12)中w'为最大池化输出后的新宽度,h'为最大池化输出后的新高度;
步骤七,重复步骤四到步骤六两次,设定这两次的隐含层神经元节点数分别为node2和节点数node3,设定每次卷积核的大小和滑动距离等与步骤四同,设定池化核的大小和滑动距离与步骤六同,最后输出的节点大小为w”'=w/stride3,h”'=h/stride3;
步骤八,(w”',h”')大小对应的矩阵信息为提取的高阶图像信息,称为热图,定位特定特征属于特定分类的物流工程车辆特征,引进了滑动的建议框在这一层上进行边框回归,该建议框有9种类型,由基本的三种尺寸和对应三种宽高比例进行组合得到9种尺度形状的建议框。通过在热图上的滑动,计算每一点不同建议框下的热图信息与真实对应的车辆类别特征进行损失的计算,定位与分类的总损失函数为:
式(13)中,ncls表示前景的个数,而边框回归个数nreg是最后特征图滑动的最大维度数量;i表示某一次迭代中的某一个建议框;pi表示预测出对应类别的概率,包括前景、背景;
式(14)中,
本发明的优点是:根据对摄像机传输的图像进行直接的判断,不需要图像背景的预处理等复杂特征的提取工程,能够适应不同环境条件下的情况,包括黑夜、白天、雨雪天气等。只需要利用训练好的多层神经网络参数进行分类判断,并输出边框回归的结果,计算效率快,并且准确率很高。
附图说明
图1是本发明的滑动距离stride为1,size为3的卷积过程示意图。
图2是本发明采用的relu滤波激活函数示意图。
图3是本发明的滑动距离stride为2,size为2的最大池化过程的示意图。
图4是本发明的多层神经网络的节点联接结构简图。
图5是本发明的由基本的尺寸和对应宽高比例形成的9种建议框类型的示意图。
图6是本发明的热图上输出的边框回归信息和分类得分信息的示意图。
图7是本发明的边框回归损失函数的示意图。
图8是本发明的多层神经网络训练的整体流程图。
图9是本发明的多层神经网络训练的误差传递过程的流程图。
图10是本发明的是边框回归定位识别物流车辆的分类结果示例图。
图中标记:1、方形卷积核;2、卷积核核心;3、扩充操作;4、加权求和操作;5、池化核;6、最大池化操作;7、神经网络的输入层;8、node1隐含层;9、node2隐含层;10、node3隐含层;11、全连接层;12、输出层。
具体实施方式
下面结合附图,进一步说明本发明的技术方案。
本发明提出的一种基于图像目标检测的物流车辆车型分类的识别方法,包括物流车辆图片数据的产生、图片的随机裁剪、白化操作、标准化操作、多层神经网络模型的训练、卷积激活操作、最大池化操作、边框回归、分类、模型参数的保存和后期的实际应用;
参照附图,基于图像目标检测的物流车辆车型分类的识别方法,步骤如下:
步骤一,通过视觉设备获取物流园区的实时影像,包含的物流车辆分为10大类:单桥厢式货车、双桥厢式货车、半挂式牵引货车、全挂式牵引货车、平头自卸车、尖头自卸车、椭圆罐车、方型罐车、搅拌类罐车;
步骤二,在所述图像指定的位置指定位置(0,0)、(10,10)、(20,20)、(30,30)、(40,40)、(50,50)裁剪大小600×600,对其进行裁剪,并将图片缩放到固定的像素:宽为w=400,高为h=400;
步骤三,将统一大小的图片,经过图片数据批量标准化处理,具体过程如下:
步骤3.1确定每次处理的图片数量为m=50张,每张图片包含有宽高的像素点信息,定义图片集合为:
x=[x1,x2,kxi...,x50](1)
式(1)中x为当前要处理的图片集合,xi为第i张图片的所有像素信息;以下表达式用于将每张二维图片像素信息按照从左往右,从上到下顺序平摊为一维像素信息:
xi=[xi1,xi2,k,xilk,xiη],1≤i≤50,1≤l≤η(2)
式(2)中η=400*400=160000,表示一张图片像素信息的总长度,xil表示第i张图片的一维像素信息所对应图片的第l位置像素信息;
通过将每张图片的一维像素信息缩放为0到1,得到浮点型的白化处理结果:
ci=xi/255(3)
式(3)中ci就表示所述第i张图片的白化处理结果;
图片集合x的白化处理结果矩阵为:
cx=[c1,c2,kci,kc50](4)
式(4)中cx为该批次图片的白化结果集合;
步骤3.2计算所述图片集合白化处理结果矩阵cx的均值:
式(5)中
e[ci]表示当前批次中第i张图片白化处理结果的均值,如第一批次中:
步骤3.3计算图片集合白化处理结果矩阵cx的方差,如第一批次中:
步骤3.4进行图片数据批量标准化处理,用于加快网络训练:
图片数据批量标准化处理结果用于神经网络的输入层7;
步骤四,对所述当前批次k图片数据批量标准化结果重新转换回二维数据:宽w=400,高h=400,进行卷积操作:
步骤4.1设定所述方形卷积核1的边长大小size=3,设定卷积核核心2起始位置为所述二维数据矩阵左上角第一个位置,注意到卷积后的结果是有损的,要得到原先一模一样的大小,必须先扩充操作3,即在上下左右各填充一行或一列的数据(这里填充白色255)。设定卷积核滑动的距离stride=1,设定滑动顺序为从左到右,从上到下;卷积核内的初始化权值weight设定为n(0,1),即服从正态分布,即
步骤4.2设定隐含层8神经元的节点个数node1=32,用于表示卷积核对所述当前批次二维数据进行卷积操作,实现加权求和4,提取32种图片特征,卷积的计算公式为:
式(9)中r为所述卷积核核心在二维数据矩阵的横坐标,c为所述卷积核核心在二维数据矩阵的纵坐标,converc为对应坐标位置的卷积操作结果,kernel3×3表示设定的卷积核,bias表示实现加权求和的偏置,偏置bias=0.2;
步骤五,需要对卷积操作后的特征进行激活,有目的地将有用的图片特征信息表达出来,通过给定的relu滤波器,将大于某阈值的有用信息进行激活,小于阈值的进行抑制,其relu滤波器激活公式为:
activerc=max(0,converc)(10)
式(10)中activerc为激活后的对应坐标特征数据,最终激活后的坐标数据矩阵记为active,max(0,converc)为激活函数,即矩阵中数值以所述阈值为0进行滤波,取当前值和阈值中的最大值,这样更符合人体机制信号刺激与抑制特点;
步骤六,将激活后的active数据矩阵进行池化降维操作,提高特征计算效率,池化降维操作采用最大池化操作,如第一批次的左上角数据为:
式(11)中kernelsize×size为设定的池化核5,
式(12)中w'为最大池化输出后的新宽度,h'为最大池化输出后的新高度;
步骤七,重复步骤四到步骤六两次,设定这两次的隐含层9和10神经元节点数分别为node2=64和节点数node3=128,设定每次卷积核的大小和滑动距离等与步骤四同,设定池化核的大小和滑动距离与步骤六同,最后输出的节点大小为w”'=w/stride3=400/23=50,h”'=400/23=50;
步骤八,(w”',h”')=(50,50)大小对应的矩阵信息为提取的高阶图像信息,称为热图,定位特定特征属于特定分类的物流工程车辆特征,引进了滑动的建议框在这一层上进行边框回归,该建议框有9种类型,由基本的尺寸{1282,2562,5122}和对应宽高比例{2:1,1:1,1:2}进行组合得到9种尺度形状的建议框。通过在热图上的滑动,计算每一点不同建议框下的热图信息与真实对应的车辆类别特征进行损失的计算,定位与分类的总损失函数为:
式(13)中,ncls=256表示前景的个数,而边框回归个数nreg=50×50=2500是最后特征图滑动的最大维度数量;i表示某一次迭代中的某一个建议框;pi表示预测出对应类别的概率,包括前景、背景;
式(14)中,
不断地迭代,调整权值、偏置,当满足总损失函数趋于稳定时停止训练,利用步骤八输出的边框位置坐标ti=(xi,yi,wi,hi),以及对应的分类概率最高的一类判定为该位置物流车型回归预测结果。如第一批次的50个图片样本输出为[1,2,6,0,...,7,9],总共50个。
本方案的优点:
本方案的优点在于可以有效地管理物流园区的车辆类型识别,降低了管理不当的损失成本;并且图像智能识别简单,只需要传入摄像机的图片到服务器,流程简单;调用训练好的模型的参数就能识别,操作简单;识别的速度非常快,只需要几毫秒就能够出结果,并且判别的结果准确率很高;对物流车辆类型的精细化管理,实时统计物流车辆的数量,有利于停车计费的准确性,避免了套牌现象和人员监督的工作,降低了人工成本。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!