一种针对非结构化文本的知识图谱构建方法及系统与流程
本发明属于数据分析技术领域,尤其涉及一种针对非结构化文本的知识图谱构建方法及系统。
背景技术
随着数字时代的飞速发展,人们周围无时无刻都充斥着各种各样的数据,要从这些数据中抽取我们所感兴趣的信息成为了现在的一大问题,数据挖掘就是从这些丰富多彩的数据中获取关注信息。而在机械维修领域,大部分的维修数据都是非结构化的数据,从以往的数据当中得到关联的故障部件、问题、原因、解决措施等结构化信息,可以为从业人员提供非常大的帮助,对于达到tb(trillionbyte,万亿字节,太字节)甚至pb(petabyte,千万亿字节,拍字节)级别的非结构化故障信息数据进行关键信息提取、特征提取与关系分析等,建立关于故障信息的知识库,形成知识图谱,为技术人员处理故障问题提供支持,提升故障处理效率。
因此,构建该类数据的知识图谱的需求越来越强烈。
申请号为cn201710109316.8的国内发明专利公开了一种知识图谱构建方法及装置,其具体公开了方法包括:基于目标语言,构建针对于目标物的初步知识图谱,目标语言为复杂度小于rdf语言的轻量级数据交换格式,初步知识图谱中包含语义理解所需的各种关键要素,各种关键要素存储在同一个文件中;从至少一个数据源,收集与各种关键要素中至少一种关键要素匹配的行业数据;将行业数据添加到初步知识图谱中至少一种关键要素指示的位置,得到目标物的目标知识图谱。由于基于复杂度小于rdf语言的轻量级目标语言构建知识图谱,因此知识图谱可读性和可维护性较佳,可提升聊天机器人的聊天效果。此外,知识图谱中包含了语义理解所需且存储在同一文件中的各种关键要素,便于统一进行管理。该发明专利详细地解释如何构建知识图谱,获取数据源并与关键要求指示位置匹配,得到知识图谱,但只适用于复杂度小于rdf语言的轻量级数据,同时对非结构化文本的知识图谱也不能很好的构建,所以,我们需要设计一种对大量非结构化信息,从中提取出有效的结构化信息,并分析它们之间的关系,从而形成知识图谱的方法和系统。
技术实现要素:
本发明针对现有技术存在的问题,提出了一种针对非结构化文本的知识图谱构建方法及系统。
本发明是通过以下技术方案得以实现的:
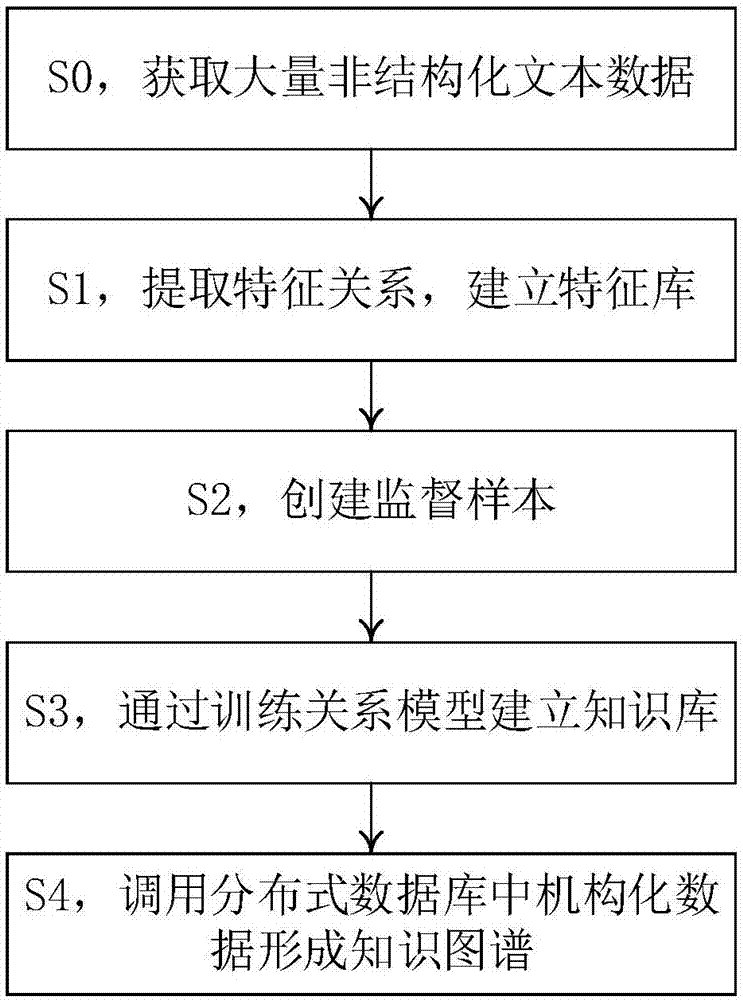
一种针对非结构化文本的知识图谱构建方法,包括以下步骤:
s1,提取特征关系,建立特征库;
s2,创建监督样本;
s3,通过训练关系模型建立知识库;
s4,调用分布式数据库中机构化数据形成知识图谱。
作为本技术方案的优选,所述步骤s1之前包括:
s0,获取大量非结构化文本数据。
作为本技术方案的优选,所述步骤s1包括:
s1.1,对所述非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析;
s1.2,根据实体标注的结果提取和句子依存关系提取故障部件、问题、原因方面的关键词组或者短语,分析关键词组之间的标注信息;
s1.3,结合所述标注信息,分析得到特征关系,提取建立特征库。
作为本技术方案的优选,所述步骤s2包括:
s2.1,调用所述特征库;
s2.2,采用远监督的方法自动创建监督样本;
s2.3,分析所述监督样本,根据依存关系标记形成正负样本集。
作为本技术方案的优选,所述步骤s3包括:
s3.1,在因子图模型中导入所述特征库;
s3.2,调用所述正负样本集进行监督;
s3.3,训练形成知识库并储存在分布式数据库中。
一种针对非结构化文本的知识图谱构建系统,包括:
特征库建立模块,用于提取特征关系,建立特征库;
监督样本创建模块,用于创建监督样本;
知识库建立模块,用于通过训练关系模型建立知识库;
知识图谱形成模块,用于调用分布式数据库中机构化数据形成知识图谱。
作为本技术方案的优选,所述特征库建立模块之前包括:
非结构化文本数据获取模块,用于获取大量非结构化文本数据。
作为本技术方案的优选,所述特征库建立模块包括:
分词单元,用于对所述非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析;
标注单元,用于根据实体标注的结果提取和句子依存关系提取故障部件、问题、原因方面的关键词组或者短语,分析关键词组之间的标注信息;
特征库建立单元,用于结合所述标注信息,分析得到特征关系,提取建立特征库。
作为本技术方案的优选,所述监督样本创建模块包括:
调用单元,用于调用所述特征库;
创建单元,用于采用远监督的方法自动创建监督样本;
标记单元,用于分析所述监督样本,根据依存关系标记形成正负样本集。
作为本技术方案的优选,所述知识库建立模块包括:
导入单元,用于在因子图模型中导入所述特征库;
监督单元,用于调用所述正负样本集进行监督;
训练单元,用于训练形成知识库并储存在分布式分布式数据库中。
本技术方案的有益效果为:
针对大量数据进行知识库的创建,通过建立特征库,创建监督样本,训练关系模型建立知识库,整个过程实现全自动化,最终将提取的结构化的数据信息与关系信息存储在分布式的数据库之中,轻松实现知识图谱的创建。
附图说明
图1为本发明一种针对非结构化文本的知识图谱构建方法的流程图;
图2为本发明一种针对非结构化文本的知识图谱构建方法步骤s1的流程图;
图3为本发明一种针对非结构化文本的知识图谱构建方法步骤s2的流程图;
图4为本发明一种针对非结构化文本的知识图谱构建方法步骤s3的流程图;
图5为本发明一种针对非结构化文本的知识图谱构建系统的框图;
图6为本发明一种针对非结构化文本的知识图谱构建系统特征库建立模块的框图;
图7为本发明一种针对非结构化文本的知识图谱构建系统监督样本创建模块的框图;
图8为本发明一种针对非结构化文本的知识图谱构建系统知识库建立模块的框图;
图9为本发明知识图谱的举例示意图。
具体实施方法
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。另外,各个实施例之间的技术方案可以相互结合,但是必须是以本领域普通技术人员能够实现为基础,当技术方案的结合出现相互矛盾或无法实现时应当认为这种技术方案的结合不存在,也不在本发明要求的保护范围之内。
以下是本发明的具体实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
实施例1
如图1所示,为本发明一种针对非结构化文本的知识图谱构建方法的流程图。
为解决机械维修领域数据量达到tb甚至pb级别的非结构化故障信息数据,建立关于故障信息的知识库,形成知识图谱,设计了一种针对非结构化文本的知识图谱构建方法。其方法包括以下步骤:
s1,提取特征关系,建立特征库。
s2,创建监督样本。
s3,通过训练关系模型建立知识库。
s4,调用分布式数据库中机构化数据形成知识图谱。
针对大量非结构化文本信息,从中提取出有效的结构化信息,并分析它们之间的关系,从而形成知识图谱。
知识图谱,也被称为科学知识图谱,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及知识之间的相互关系。时下,通过构建知识图谱,并将构建的知识图谱运用于机械故障判定以及寻找维修方法,已经成为了本领域技术人员广泛采取的一种做法。
将大量非结构化文本导入分布式数据库,从分布式数据库中读取非结构化文本数据并对非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析,根据实体标注结构提取故障部件、问题、原因等关键信息,再联合关键信息之间的词性标注、实体标注、依存关系标注结果建立特征库。根据特征库提取特征的因果依存关系,分析创建监督样本。将所述特征库导入因子图模型进行训练,样本监督采用结构化的故障信息文本,最后,通过训练出的模型完成知识库的创建与知识图谱的呈现。
s0,获取大量非结构化文本数据。
本实施例主要是对于车辆、船或者飞机等大批量非结构化故障信息数据进行故障问题、故障原因、解决措施的抽取。在建立专业领域词典和标注词典之前,首先需要获取大量非结构化文本数据,以此作为基础,进行后续的分析操作过程。
如图2所示,为本发明一种针对非结构化文本的知识图谱构建方法步骤s1的流程图。
s1,提取特征关系,建立特征库。
建立专业领域的词典并进行相关标注,确保故障信息的专业词组能够被分词分出和后续标注,使用stanfordcorenlp(是由斯坦福大学开源的一套用处理自然语言的工具)对大量非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析,在分词过程中需要加载刚才创建的专业领域词典和标注词典,将分析出的结果按照分词和标注的对应关系存入分布式数据库之中,根据实体标注的结果提取和句子依存关系提取故障部件、问题、原因方面的关键词组或者短语,分析关键词组之间的标注信息,包括词性标注、实体标注、和依存关系标注的信息,按照一定的规则将这些标注信息结合在一起形成特征,构建所示特征库。
所述步骤s1包括:
s1.1,对所述非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析。
s1.2,根据实体标注的结果提取和句子依存关系提取故障部件、问题、原因方面的关键词组或者短语,分析关键词组之间的标注信息。
s1.3,结合所述标注信息,分析得到特征关系,提取建立特征库。
如表一所示
表一
表一中的第一行表示一段关于汽车故障维修的非结构化文本,我们从中获取有用信息需要将整段读完理解后才能实现。现在我们使用stanfordcorenlp对其进行分词、词性标注、命名实体标注、依存句法分析,对发动机、喷油头等部件实体标记为parts(标记名称可以自定),“抖动”、“发出”等词语标记为q(question,问题),“阻塞”等词语标记为r(reason,原因),“清洗”等动词标记为s(solve,解决方式),下面将说明关键词组的产生方法。
找到标记为q的表示故障问题的动词,利用依存句法的nsubj(名词性主语)、dobj(动宾短语)等句法关系进行组合,例如:发动机抖动、发出声音;找到标记为r的表示故障原因的动词,同样按照nsubj(名词性主语)、dobj(动宾短语)等句法关系进行组合,例如喷油头阻塞;找到标记为s的表示解决措施的动词,按照上述原则进行组合,例如:清洗喷油头。这样就提取出来表达故障信息的问题、原因、解决措施三个方面的关键词组。
找到命名实体标记为q和r的词,利用它们之间句子的标注信息建立问题和原因之间的特征即为q-r关系,如表中斜体加粗的句子,通过“发出”和“阻塞”两个词之间标注信息建立特征,一般只取这两个词附近三个词以内的标注信息进行联合建立特征,为了减小特征库的大小和计算量。同样地,找到命名实体标记为r与s的词,如“阻塞”和“清洗”,以相同的方式建立问题和解决方式之间的特征即为q-s关系。
最后所有的q-r关系数据和q-s关系数据共同形成所述特征库。
如图3所示,为本发明一种针对非结构化文本的知识图谱构建方法步骤s2的流程图。
s2,创建监督样本。
采用远监督的方法进行监督样本的自动创建。在分布式数据库中数据集的标签是不可靠情况下(这里的不可靠可以是标记不正确,多种标记,标记不充分,局部标记等),远监督学习方法针对监督信息不完整或不明确对象时,更为适用。
所述步骤s2包括:
s2.1,调用所述特征库。
s2.2,采用远监督的方法自动创建监督样本。
s2.3,分析所述监督样本,根据依存关系标记形成正负样本集。
采用远监督的方法进行监督样本的自动创建,命名实体标记为q和r的词之间如果出现“由于”、“因为”、“原因”等词语时,我们将其作为故障问题与原因这一对关系中的正样本,其它相差太大的标记为负样本;命名实体标记为r和s的词之间如果出现“解决”、“实行”、“执行”、“正常”等词语时,我们将其作为故障原因与解决措施这对关系中的正样本,其它完成不相关的句子标记为负样本。上面只是建立监督样本的规则举例,还可以添加更多的规则来建立正负样本集,这些规则一般通过编写脚本(shell,python等)的方式实现。
如图4所示,为本发明一种针对非结构化文本的知识图谱构建方法步骤s3的流程图。
s3,通过训练关系模型建立知识库。
训练模型这里采用因子图模型,将所述步骤s1中得到的所述特征库导入因子图模型进行训练,采用所述步骤s2中得到的正负样本集进行监督,最终可得到关系模型,建立知识库。
所述步骤s3包括:
s3.1,在因子图模型中导入所述特征库。
s3.2,调用所述正负样本集进行监督。
s3.3,训练形成知识库并储存在分布式数据库中。
将非结构化文本数据经过预处理导入关系模型,就能得到结构化的q-r关系数据和r-s关系数据,最终的关系数据是存储在分布式的数据库中,这就是所建立的关系知识库。
s4,调用分布式数据库中机构化数据形成知识图谱。
最后调用数据库中的结构化数据进行呈现,就能形成知识图谱,如图9所示。
实施例2
为基于实施例1基础之上的系统。
如图5所示,为本发明一种针对非结构化文本的知识图谱构建系统的框图。
一种针对非结构化文本的知识图谱构建系统,包括:
特征库建立模块,用于提取特征关系,建立特征库。
监督样本创建模块,用于创建监督样本。
知识库建立模块,用于通过训练关系模型建立知识库。
知识图谱形成模块,用于调用分布式数据库中机构化数据形成知识图谱。
所述特征库建立模块之前包括:
非结构化文本数据获取模块,用于获取大量非结构化文本数据。
如图5所示,为本发明一种针对非结构化文本的知识图谱构建系统特征库建立模块的框图。
特征库建立模块,用于提取特征关系,建立特征库。
所述特征库建立模块包括:
分词单元,用于对所述非结构化文本数据进行分词、词性标注、命名实体标注、依存关系分析。
标注单元,用于根据实体标注的结果提取和句子依存关系提取故障部件、问题、原因方面的关键词组或者短语,分析关键词组之间的标注信息。
特征库建立单元,用于结合所述标注信息,分析得到特征关系,提取建立特征库。
如图7所示,为本发明一种针对非结构化文本的知识图谱构建系统监督样本创建模块的框图。
监督样本创建模块,用于创建监督样本。
所述监督样本创建模块包括:
调用单元,用于调用所述特征库。
创建单元,用于采用远监督的方法自动创建监督样本。
标记单元,用于分析所述监督样本,根据依存关系标记形成正负样本集。
如图8所示,为本发明一种针对非结构化文本的知识图谱构建系统知识库建立模块的框图。
知识库建立模块,用于通过训练关系模型建立知识库。
所述知识库建立模块包括:
导入单元,用于在因子图模型中导入所述特征库;
监督单元,用于调用所述正负样本集进行监督;
训练单元,用于训练形成知识库并储存在分布式分布式数据库中。
知识图谱形成模块,用于调用分布式数据库中机构化数据形成知识图谱。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方法替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!