一种使用深度学习的CBCT去伪影方法与流程
本发明涉及一种使用深度学习的cbct去伪影方法,属于医学图像处理技术领域。
背景技术
锥形束计算机断层成像技术(conebeamcomputedtomography,cbct)因为其自身的扫描速度快、辐射剂量相对较低及射线利用率相对较高等优点,并且还能解决分次放疗间患者的摆位误差等问题,而广泛利用在igrt系统(image-guidedradiationtherapy)中。相比于传统的体层ct,基于cbct图像进行计划验证的技术有能降低患者所受福射剂量且耗时短等优点。但是由于cbct的探测器信噪比低,且没有遮挡散射的准直器,会存在大量的散射伪影与噪声,导致重建图像的ct值(hounsfieldunit,hu)不精确,对于后续图像分割、配准等医生的诊断产生很大的影响。
为了去除cbct的散射伪影,endo等人提出放置准直器的方法,xu.y等人提出基于蒙特卡洛罗模拟的散射伪影校正方法,通过使用蒙特卡罗模拟方法来模拟出cbct图像中的散射伪影,在cbct去伪影方面取得了良好的效果。此外,其他一些方法比如主射线调制,移动挡板等,也为cbct的散射矫正提供了多个角度的思路。
然而这些方法或引入了硬件设备,或增加了辐射剂量,或需要其他先验知识进行约束。某些方法只对某种伪影有矫正效果,对其他伪影则适应性不够理想。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的缺陷,提供一种使用深度学习的cbct去伪影方法,去除cbct中的散射伪影。
为解决上述技术问题,本发明提供一种使用深度学习的cbct去伪影方法,其特征是,包括如下步骤:
(1)从igrt系统获取cbct图像和ct图像对,组成cbct-ct数据集,对cbct-ct数据集进行基于互信息的配准,提高同一个病人相同部位cbct和ct的匹配度,并解决由cbct、ct切片厚度不同导致两种数据数量不同的问题;
(2)将匹配过的cbct-ct数据集进一步划分成子图像块,对相同位置的cbct-ct子图进行二次配准,得到cbct-ct子块组;
(3)将两次配准之后的子块组通过一个深度神经网络进行残差学习,估计出cbct图像与对应位置的ct图像之间的残差分布;
(4)根据模型求出待测cbct的残差图,并用cbct减去残差图得到去除伪影的cbct图像。
进一步的,所述步骤(1)中待配准两图像的互信息由下式给出:
其中,r为cbct图像作为参考图像,f′为ct图像作为待配准图像,
求出
进一步的,所述步骤(2)同样使用步骤(1)中基于互信息的配准,将原图像的各个重叠滑动子块进行精配准。
进一步的,所述步骤(3)将两次配准之后的cbct-ct子块组送入深度神经网络进行残差学习,该网络的代价函数l(θ)为:
其中,fi代表第i个cbct子块,xi代表第i个ct子块,μ(fi;θ)表示深度神经网络学习到的残差,其随着网络的不断训练而更新,n代表训练样本的数目。
进一步的,所述步骤(3)中的深度神经网络为深度卷积神经网络,其中卷积神经网络结构为多尺度卷积神经网络结构,该网络的深度为d层,它有四种不同的网络层,分别如下:
第一层为卷积网络和relu构成的网络层,由64个3*3*1的滤波器组成,用来产生64个特征映射;
第二层,在卷积网络和修正线性单元的基础上引入了批规范化单元bn,使用64个3*3*1*64的滤波器,将bn加在卷积和relu之间;
第三层到d-1层为多尺度模块,使用1*1*1*64,3*3*1*64,5*5*1*64三种不同尺度模块的滤波器+批规范化单元bn+修正线性单元relu组成;
第d层为一个卷积网络层,使用3*3*1*64的滤波器用来实现端到端的映射,重建输出结果。
进一步的,所述步骤(3)中的深度神经网络为深度卷积神经网络,其中卷积神经网络结构为单尺度卷积神经网络结构,该网络的深度为d层,它有三种不同的网络层,分别如下:
第一层为卷积网络和relu构成的网络层,由64个3*3*1的滤波器组成,用来产生64个特征映射;
第二层到d-1层,在卷积网络和修正线性单元的基础上引入了批规范化单元bn,使用64个3*3*1*64的滤波器;
第d层为一个卷积网络层,使用3*3*1*64的滤波器用来实现端到端的映射,重建输出结果。
进一步的,所述步骤(4),用训练好的网络对由cbct图像组成的测试集进行测试,得到每个cbct切片近似的伪影图,再用cbct减去各自的伪影图即可得到去除伪影的cbct。
本发明所达到的有益效果:
本发明在实用igrt图像库真实数据的基础上,通过二次配准对数据预处理,引接下来通过深层卷积神经网络结构框架进行残差学习伪影分布;同时采用gpu加速,缩短了训练的时间,加速了实验的训练过程,有效地去除cbct的亮暗不均匀伪影及条纹状伪影。有利于进一步发挥cbct系统的优势与潜力。
附图说明
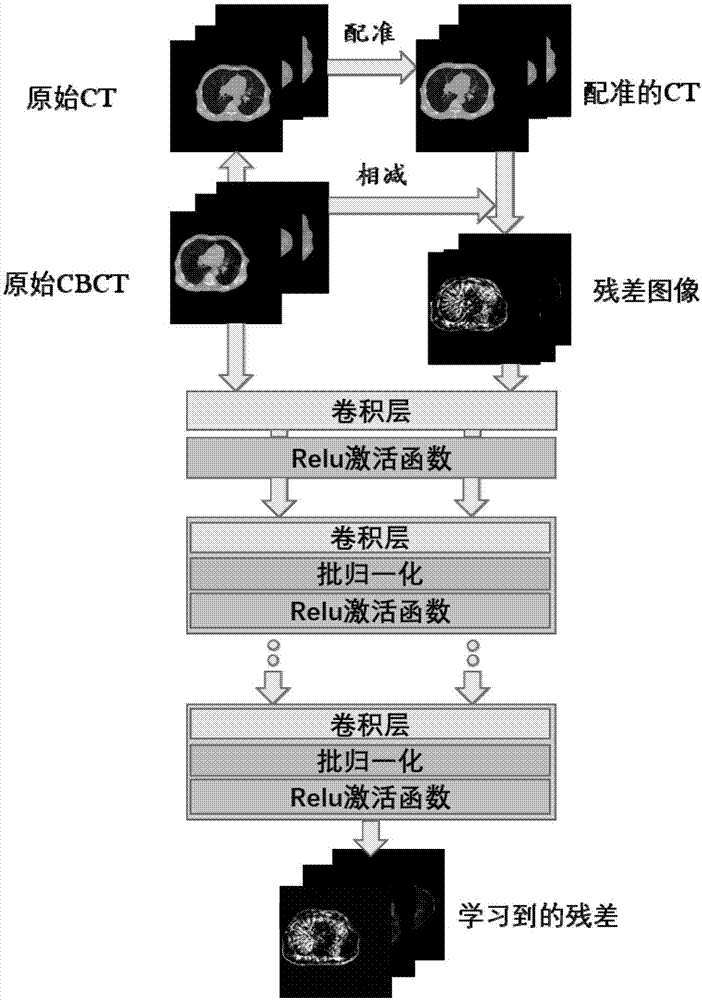
图1是卷积神经网络学习伪影的流程图;
图2是去伪影示意图;
图3是实验结果对比图。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
本发明提出了一种使用深度学习的cbct去伪影方法,首先体配准对整体的cbct-ct数据集进行预处理,使得两种数据的数量相等。再通过精配准之后送入深层卷积神经网络进行残差学习,得到伪影图;最后将cbct与伪影图的做残差,实现cbct的伪影去除。
深度学习网络结构图如图1所示。
1.1基于残差学习的卷积神经网络
由于深度学习在学习图像噪声特点方面取得了很好的效果,张凯等人利用残差学习卷积神经网络去高斯噪声、解决sisr和jpeg图像块效应等方面较传统的方法效果更好。本发明利用基于残差学习的卷积神经网络对cbct图像进行学习,残差学习的卷积神经网络的输入为cbct图像f=x+n。在深度学习卷积网络当中,典型的去噪模型如mlp和csf旨在学习一个映射函数f(f)=x预测一个清晰的图像。对于残差学习的卷积神经网络,训练的是一个映射μ(f)≈n函数。本发明提出的基于残差的卷积神经网络旨在解决以下问题:
常规的重建散射矫正之后cbct图像的目标函数可以表示为:
其中,f为原始cbct图像,x在这里代表无伪影的ct图像,r(x)为正则化项,λ表示正则化参数。这里正则化项可以表示为
以f为起点,α为步长的梯度下降法进行迭代学习,其中
以相同位置的cbct与ct图像的真实残差,与网络生成的伪影图像的最小平方差作为损失函数来衡量恢复图像的好坏,公式为:
其中,fi代表第i个cbct子块,xi代表第i个ct子块,(fi-xi)代表作为第i个标签的残差图像,μ(fi;θ)表示深度神经网络学习到的残差,其随着网络的不断训练而更新,n代表训练样本数目。
该残差学习神经网络即为本方法提出的去伪影校正方法,由残差学习神经网络学习得到的残差图即为伪影特征图,然后根据x=f-n,得到最终清晰的图像,实现过程见图2所示。
1.2残差学习卷积神经网络的具体结构
基于残差学习的多尺度卷积神经网络的具体结构,如图1所示。
该网络的深度为d层,它有四种不同的网络层,分别为:卷积网络+relu(修正线性单元)、卷积网络+bn(batchnormalization,批规范化),多尺度开始模块(inceptionmodule)和卷积网络层。第一层为卷积网络和relu构成的网络层,它由64个3*3*1的滤波器组成,用来产生64个特征映射。这一层加入relu,目的是在卷积网络中引入非线性,因为神经网络学习的实际数据是非线性的,卷积是一个线性操作(元素级别的矩阵相乘和相加),因此需要通过使用非线性函数relu来引入非线性。然而经实践证明,relu具备引导适度稀疏的能力,训练后的网络完全具备适度的稀疏性,而且训练后的可视化效果和传统预处理的效果很相似。正因为它有这样的作用使得relu的速度非常快,而且精确度很高。第二层,在卷积网络和修正线性单元的基础上引入了bn(批规范),使用64个3*3*64的滤波器,将bn加在卷积和relu之间。深层神经网络在做非线性变换前激活输入值随着网络深度的加深,分布逐渐发生偏移或者变动,逐渐往非线性函数取值区间的上下限两端靠近,这导致后向传播时低层神经网络梯度的消失,进而使得深层神经网络的训练速度收敛越来越慢。bn通过一定的规范化手段,把每层神经网络中任意神经元输入值的分布强行拉回到均值为0、方差为1的标准正态分布中(即把越来越偏的分布强制拉回比较标准的分布中),使得激活输入值落在非线性函数对输入比较敏感的区域。这样输入的小变化引起损失函数较大的变化,梯度随之变大,于是避免了梯度消失的问题,同时学习收敛速度加快,大大提高了训练速度。
第三层到d-1层为多尺度模块,使用64个1*1*64,64个3*3*64,64个5*5*64三种不同尺度模块的滤波器组成,并将bn加在卷积和relu之间。
第四层为一个卷积层,使用3*3*64的滤波器用来实现端到端的映射,重建输出结果。
1.3优化加速
在训练中优化过程一般采用梯度下降法,梯度下降法有随机梯度下降法(sgd,stochasticgradientdescent)和adam算法等。其中adam算法根据损失函数对每个参数梯度的一阶矩估计和二阶矩估计进行动态调整,使其调整到一个合适的学习速率。adam算法在每次迭代中参数的学习步长都有一个确定的范围,不会因为很大的梯度导致学习步长的增大,参数的值也比较稳定。批量梯度下降算法的缺点是每次都会使用全部训练样本,而且每次都使用完全相同的样本集,这会使得计算相对的冗杂。相反随机梯度下降算法的实现是可以在线更新的,每次只随机选择一个样本来更新模型参数,学习速度是非常快的。在神经网络训练过程当中,sgd和adam优化方法的引入使网络结构训练得到了更好的结果,其中adam算法在图像高斯去噪过程中效果要强与sgd算法。
具体实施例
2.1实验数据
实验的数据由某医院提供的肺部的cbct扫描。实验所用cbct数据共1093张,分为384*384及512*512两种尺寸,厚度也分为2.5mm和3mm两种。ct数据共1225张,均为512*512,3mm。其中352张cbct和367张ct被划分至测试集,其余为训练数据。本实验将cbct数据作为网络输入,cbct与ct的残差作为标签,进行有监督神经网络训练。经过50次迭代,得到最终训练好的网络。
2.2网络训练和参数的设定
本方法为了训练的准确性而得到较好的去伪影效果,不同投影数重建的训练样本分别为2000张,测试图像分别为200张,同时把网络的深度d设置为15。采用损失函数学习残差映射μ(f)估计预测残差n。优化方法选择adam下降法,梯度的一阶矩估计α为0.01,二阶矩估计β1为0.9,β2为0.999,更新幅度的校正参数epsilon为1e-8。该残差网络的训练速率为10-3~10-4,每次训练逐渐递减。为了产生较好的去伪影效果,提取出条状伪影的特征图,训练次数设置为50。
本方法在训练的过程中使用matconvnet工具包,运行环境为matlab2015a,处理器为i7-6850kcpu(3.60hz),内存为64gb,gpu显卡为geforcegtx1080ti。在此配置环境中,通过该网络训练样本大约需要24个小时。
2.3实验结果
2.3.1实验前后对比
图3对比了原始cbct,ct,并分别使用linxi的方法以及本专利的方法进行散射矫正。实验结果显示本专利的方法能够有效的去除散射带来的条纹状伪影,同时较好地保留细节以及边缘信息。
2.3.2图像评价
在评价重建图像的好坏主要有两个指标:psnr(peaksignaltonoiseratio,峰值信噪比)和ssim(structuralsimilarity,结构相似性)。
2.3.3.1psnr
psnr的计算如下:
mse表示稀疏重建图像x和通过残差学习恢复的图像y的均方误差(meansquareerror),h、w分别为图像的高度和宽度;n为像素的位深,在ct图像中位深为12。
2.3.3.2ssim
ssim是一种全参考的图像质量评价指标,它分别从亮度、对比度、结构三方面度量图像相似性。
ssim(x,y)=[l(x,y)]α·c(x,y)]β·s[(x,y)]γ;
其中l(x,y)为亮度对比函数,c(x,y)为对比度对比函数,s(x,y)为结构对比度函数,x和y分别表示稀疏重建的图像和残差学习恢复的图像,α、β、γ是三个对比函数所占的比例因子。
本实施例选取了120个原始数据作为测试数据,分别计算了原始cbct,ct以及使用本方法和对比方法去伪影之后图像的平均对ctpsnr和hu值,同时计算了不同roi(regionofinterests)的cnr(contrast-to-noiseratio)。结果如表1所示。可见经过本方法处理之后,cbct对ct的pnsr显著提高,同时从hu值来看校正之后的cbct在亮暗上也比对比方法更接近于原始ct。
表1
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!