一种基于表示学习和竞争理论的学者推荐及合作预测方法与流程
本发明属于计算机软件领域,涉及一种基于表示学习和竞争理论的学者推荐及合作预测方法。
背景技术:
跨越多领域的跨学科研究在过去几十年中快速增长,学者之间的科学合作变得越来越重要和必要。然而,从大的学术数据中找到最有价值的合作者往往是个极大的挑战。表示学习的目的是为网络中的每一个节点分配一个某个线性空间中的向量,也就是我们常说的n维向量,向量与向量之间的关系保留了原网络中对应的节点之间在结构上的关系。word2vec于2013年由google发布,集成cbow和skip-gram模型,提供了用于计算单词向量表示的高效实现,它将文本语料库作为输入并输出单词向量。在此基础上发展而来的doc2vec是表示学习中有效的处理文本的方法,集成pv-dm和pv-dbow模型,可以用于从不同长度的文本片段中获取固定长度的特征表示。node2vec是2016年提出的用于网络中可伸缩特征学习的半监督算法,优化了一个自定义的基于图形的目标函数,返回的特征表示最大化保留d维特征空间中节点的网络邻域的可能性,并使用二阶随机游走方法为节点生成网络邻域。
梯度下降值更新技术是求解机器学习算法的模型参数,即无约束优化问题时最常用的方法之一。本发明中利用梯度下降迭代求解,得到趋于稳定的因子特征向量,该向量表示了各个因子在整体作用下影响力的权重。
传统上,学者合作推荐的核心是为学者创建静态的推荐列表,该推荐严重依赖于源学者与候选学者之间的相关性,这不利于新合作的建立。此外,推荐候选学者还不足以保证实现真正的合作。给出静态推荐列表会导致同一个候选人被同时推荐给多位学者。然而,由于时间的限制,这位候选人无法接受众多的合作者。所以传统的给出静态推荐列表的推荐方法已经不能满足学者们的需求。
合作预测是通过现有数据对未来合作的一个推测。目前大多数的预测方法都是基于学者的出版物来进行的,但是这不利于跨领域合作的建立。此外,对于下一次的合作对象的来源,既可能是加强旧合作的最有价值的推荐者(mostvaluablerecommenders,mvcs),也可能是建立新合作的最有潜力的推荐者(mostpotentialrecommenders,mpcs)。合作网络中包含这两种来源,并且可以比基于出版物的预测方法给mpcs更多的机会,同时保证了预测对象之间较高的合作意向。因此结合合作网络和论文内容进行合作预测可以得到更高的准确性。
技术实现要素:
本发明提供了一种基于表示学习和竞争理论的学者推荐及合作预测方法,解决传统静态推荐和单一来源合作预测导致的效果不佳的问题,实现了动态合作推荐和合作预测,保证了结果的准确性。
本发明的技术方案:
一种基于表示学习和竞争理论的学者推荐及合作预测方法,具体步骤如下:
步骤一、从微软数据集中获取有效数据并进行预处理,然后划分为训练集和测试集;
所述的有效数据包括:论文中的学者信息、标题信息、摘要信息、关键词信息和引用信息;
所述的预处理是:依据学者信息获取学者群体,过滤合作数低的学者,得到有效学者群体,建立有效学者群体的四个因子文件;利用有效学者群体的四个因子文件建立无向合作网络,获取每个学者的最邻近网络节点邻居;四个因子包括论文的标题、摘要、关键词和引用;
步骤二、构建动态的基于论文内容的学者个性相似度计算模型,具体过程为:
(1)利用doc2vec计算学者之间标题的相似度、摘要的相似度,利用重合率计算方法计算学者之间关键词的相似度、引用的相似度;具体过程为:
利用doc2vec分别处理所有学者的标题、摘要,并过滤掉停用词,最终为每个学者生成一个128位的向量表示,并计算两两之间的余弦相似度以表征学者之间标题的相似度、摘要的相似度,计算公式均为:
其中,在计算标题相似度时,
分别对每个学者的关键词信息和引用信息建立“带权集合”,集合中的每个元素为该学者论文中的四个因子之一,“带权”是指每个元素都有一个权值标记该因子出现的次数,利用重合率计算方法计算学者之间关键词的相似度、引用的相似度,计算公式分别为:
(2)以某学者与其他学者间四个因子上的相似度总和作为节点状态的初始值,具体过程为:计算学者i的最佳表现值作为节点状态的初始值,公式为:
(3)根据步骤(1)计算的学者之间的相似度,利用梯度下降算法学习因子特征向量,同时不断更新处理节点的邻域节点的状态,以实现动态更新当前节点的状态值;具体过程为:在梯度下降算法中输入每个学者的四个因子,不断迭代直到因子特征向量
其中,α为学习速率;
(4)利用学习得到的因子特征向量结合相似度计算每个学者的推荐度表征值,并生成初步的推荐列表;具体过程为:用学者i的最佳表现值与相似度综合表征值的和来表示学者i的推荐度,公式为:
步骤三、构建基于合作网络的学者环境相似度计算模型,具体过程为:
(1)利用表示学习方法node2vec分析步骤一所建立的无向合作网络,获得每个学者节点的特征向量;
(2)利用特征向量余弦值计算方法计算学者之间在合作网络中的相似度;余弦值计算公式为:
步骤四、构建合作预测模型,具体过程为:
(1)利用步骤二得到的基于论文内容的学者个性相似度和步骤三得到的基于合作网络的学者环境相似度组合起来,得到组合相似度;
(2)根据组合相似度对初步的推荐列表进行排序,为每个学者的候选人生成一个组合相似度从高到低的降序序列,得到每个学者的合作预测列表;
(3)把每个学者合作预测列表中组合相似度最大的学者作为合作预测对象;
步骤五、构建竞争理论的处理模型,具体过程为:
(1)利用基于论文内容的学者个性相似度对每个学者的候选人列表进行排序,获得合作推荐候选列表;
(2)利用步骤三得到的基于合作网络的学者环境相似度,对排序后的合作推荐候选列表进行竞争处理,保证每个学者只被推荐给最佳的合作者,从而消除时间冲突;具体过程为:对合作推荐候选列表中的目标学者ae被推荐给学者a1,…,ah,找到其中与ae环境相似度最大的学者ai,则标记一个成功匹配,重复这个过程直到每个学者都被成功标记一个目标学者,竞争的原理为:compete(ae|a1,...,ah)=ai,ifenvsimxei=max{envsimxe1,...,envsimxeh};其中ae表示目标学者;a1,…,ah表示合作推荐候选列表种有学者ae的源学者,envsimxei表示学者ae和学者ai之间的环境相似度。
(3)最终为每个学者推荐一个不冲突的最佳合作者,即每个目标学者只推荐给一个源学者;
步骤六、利用步骤一预处理的数据集对以上模型进行训练,根据训练获得的个性相似度,产生合作推荐候选列表和合作预测列表;
步骤七、利用环境相似度削弱过于相似的源学者和目标学者,同时利用竞争理论的处理模型消除时间冲突,从而获得最终的推荐列表和下一次合作对象预测结果。
本发明的有益效果:本发明提出一种基于表示学习和竞争理论的学者推荐及合作预测方法,解决了学者推荐过程的动态演变,并将竞争理论引入推荐过程,将时间因素纳入影响因子范围,从而获得更准确、更合理的推荐结果;利用学术合作网络中学者之间的相似度削弱因论文内容相似度高而被推荐的过于相似的合作对象,更加有利于跨领域、跨学科的科研合作;在合作预测方面,我们综合学者的论文信息和合著关系来对未来可能产生的合作进行预测,具有更高的准确性。
附图说明
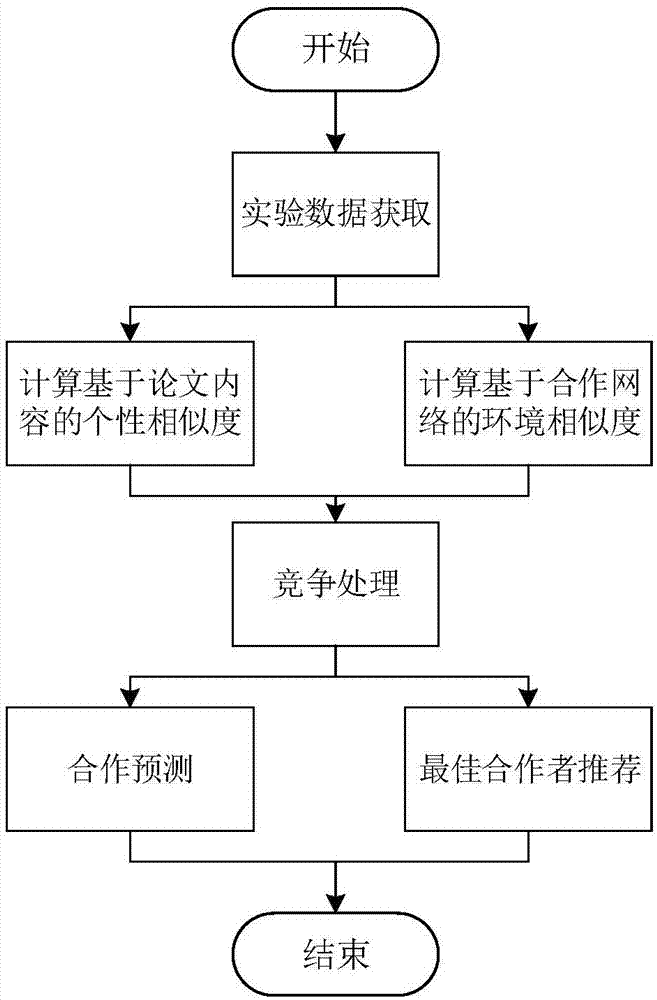
图1是基于表示学习和竞争理论的学者推荐及合作预测方法的流程图。
图2是基于表示学习和竞争理论的学者推荐及合作预测方法的过程示意图。
图3是数据处理过程中数据筛选的流程图。
图4是对不同大小测试集进行实验验证的结果对比图。
具体实施方式
下面将结合具体实施例和附图对本发明的技术方案进行进一步的说明。
如图1所示,本发明实施例公开了一种基于表示学习和竞争理论的学者推荐及合作预测方法,包括以下步骤:
步骤一、从微软数据集中获取有效数据并进行预处理,并划分为训练集和测试集;
预处理:依据学者信息获取学者群体,过滤合作数低的学者,得到有效学者群体,建立有效学者群体的四个因子文件;以标题因子文件为例,文件里的每条信息都是以python字典类型存储,学者姓名为键、学者论文的标题信息为值(学者参与发表多篇论文的情况下,标题信息为每篇论文的标题简单拼接,并以分号隔开);利用有效学者群体的合著关系建立无向合作网络(一篇论文的所有作者之间的关系为合著关系),具体为以单个学者为节点,每两个有合著关系的学者之间连一条边,利用该网络为每个学者获取10个最邻近网络节点邻居;
从微软数据集中获取以论文信息条为单元的数据文件,利用基于python的正则表达式对数据进行筛选,选出machinelearning领域的文章,从中提取2005-2017年的数据,将2005-2014年的数据作为训练集,训练集共包含96891名学者,将2015-2017年的数据作为测试集,测试集包含5202名学者,并提取学者、标题、摘要、关键词和引用信息。数据筛选过程如图3所示,论文以数据条的形式存在于txt文件中,具体实施为:
(1)从文件中读取相应数据条,转化为python字典类型;
(2)python正则匹配“fos”键值是否包含“machinelearning”,“是”则进入下一步,“否”则跳转到步骤(1)继续读下一个数据条;
(3)python正则匹配“year”是否满足“year>=2005andyear<=2017”,“是”则进入下一步,“否”则跳转到步骤(1)继续读下一个数据条;
(4)检查学者、标题、摘要、关键词和引用信息是否完整,“是”则写入目标文件,“否”则返回步骤(1)继续读下一个数据条;
(5)判断当前是否为文件末尾,如“是”则结束数据处理过程,“否”则返回步骤一继续读下一个数据条。
步骤二、构建动态的基于论文内容的学者个性相似度计算模型和基于合作网络的学者环境相似度计算模型,具体包括以下步骤:
(1)构建动态的基于论文内容的学者个性相似度计算模型
(a)利用表示学习方法doc2vec分别处理所有学者的标题、摘要,并过滤掉一些停用词,“of”、“and”、“the”等,最终为每个学者生成一个128位的向量表示,并计算两两之间的余弦相似度以表征该因子上的相似度,计算公示为:
(b)以某学者与其他学者间四个因子上的相似度总和作为节点状态的初始值具体为:计算学者i的状态值,公式为:
(c)根据学者之间的相似度,利用梯度下降算法学习因子特征向量,同时不断更新处理节点的邻域节点的状态,以实现动态更新当前节点的状态值,具体为;在梯度下降算法中输入每个学者的四个因子,不断迭代直到因子特征向量
其中,α为学习速率;
(d)利用学习得到的因子特征向量结合相似度计算每个学者的推荐度表征值,并生成初步的推荐列表,具体为:用学者i的状态表征值与相似度综合表征值的和来表示学者i的推荐度,公式为:
(2)构建基于合作网络的学者环境相似度计算模型
根据论文的“authors”信息确定学者之间的合著关系(一篇论文的所有作者之间的关系为合著关系),并根据合著关系建立合作网络,具体为以单个学者为节点,每两个有合著关系的学者之间连一条边;利用表示学习方法node2vec为每个学者学习一个128位的特征向量,并通过计算两两之间的余弦值以表征学者之间网络位置上的相似度,余弦值计算公式为:
步骤三、竞争过程包括构建合作预测模型和构建竞争理论的处理模型具体包括如下步骤:
(1)建立合作预测模型具体为:
(a)将基于论文内容的学者个性相似度和基于合作网络的学者环境相似度组合起来,组合的公式为:sim=persim*0.6+envsim*0.4,其中sim为组合相似度,persim为个性相似度,数值上等于popi,计算公式为:
(b)根据组合相似度为对templist进行排序,为每个学者的候选人生成一个组合相似度从高到低的降序序列;
(c)提取学者i合作预测列表中组合相似度最大的学者k作为合作预测对象。
(2)构建竞争理论的处理模型具体为:
(a)基于论文内容的学者个性相似度对每个学者的候选人列表进行排序获得的templist;
(b)对templist的每个学者进行竞争处理,保证每个学者只被推荐给最佳的合作者,对于目标学者ae被推荐给学者a1,...,ah,找到其中与ae环境相似度最大的学者ai,则标记一个成功匹配,重复这个过程直到每个学者都被成功标记一个目标学者,竞争的原理为:compete(ae|a1,...,ah)=ai,ifenvsimxei=max{envsimxe1,...,envsimxeh};其中ae表示目标学者;a1,…,ah表示合作推荐候选列表种有学者ae的源学者,envsimxei表示学者ae和学者ai之间的环境相似度。
(c)对成功标记的学者组合ae和ai,获取学者ae的10个与当前时间距离最近的10个合作者作为学者ai的备选合作者。
利用以上模型对训练集数据进行训练,并通过测试集实验结果进行验证,将算法rcrec与经典随机游走算法rwr和基于共同邻居的推荐算法cnrec进行对比,获得和表1的结果,对不同大小测试集进行实验获得如图4的实验结果:
表1不同算法实验结果对比
算法rcrec在相同数据集上获得了优于rwr和cnrec的结果,在测试集大小为5202时准确度高于rwr0.03,高于cnrec0.038。由图4可知,在不同大小测试集下的实验,rcrec的结果普遍优于rwr和cnrec,且当测试集越大时,优势越明显。但随着测试集的不断增大,推荐结果的准确率变化逐渐平缓,最后稳定在一定范围内。
- 还没有人留言评论。精彩留言会获得点赞!