一种分布式约束优化模型求解AGV调度系统任务分配的方法与流程
本发明属于调度方法
技术领域:
,涉及一种agv调度系统任务分配的方法,具体涉及一种分布式约束优化模型求解agv调度系统任务分配的方法。
背景技术:
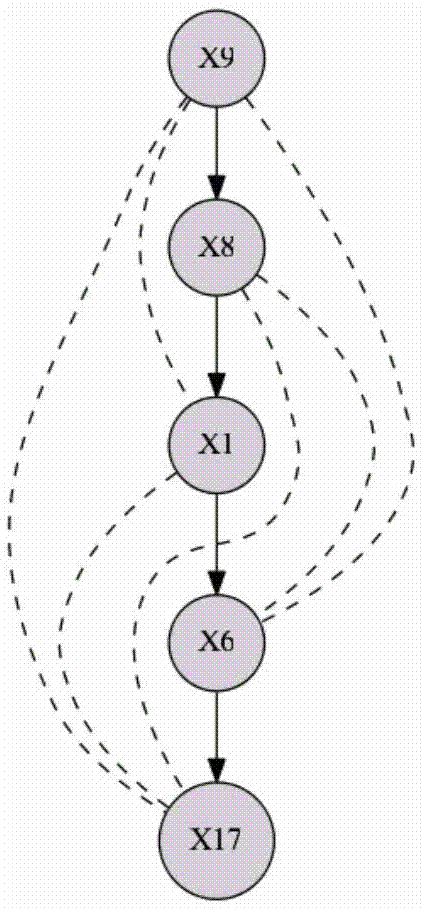
:分布式约束优化问题(distributedconstraintoptimizationproblem,dcop)是基于约束满足问题(constraintsatisfiedproblem,csp)发展而来的,是研究多智能体agent的重要框架。目前,智能体agent在学术界并没有一个统一的定义,通常是指具有自主性和能动性,相互之间能进行通信的实体或虚拟的系统。dcop中有多个agent,并且它们之间有约束关系,dcop的目标就是协调agent之间的约束,从而达到一个目标函数全局最优的目的。同时,在每个agent内部形成一个集中式的约束优化问题,agent具有自我控制的决策能力。agv(automatedguidedvehicle)是指装备有电磁或光学等自动导引装置,由计算机控制,以轮式移动为特征,自带动力或动力转换装置,并且能够沿规定的导引路径自动行驶的运输工具,一般具有安全防护、移载等多种功能。通俗的讲,agv就是一个用来运输的移动机器人,它是一个搬运工,把货物从a处运到b处。agv的大部分研究也是包含在移动机器人领域内的。agv调度系统是要保证任务高效的运行,即将已知和未知的任务按照一定规则并满足系统任务时间和各种资源有限等约束的情况下,合理的分配给agv。目前agv系统的任务调度主要由两种类型:离线任务调度和在线任务调度。技术实现要素:根据以上现有技术的不足,本发明提供一种分布式约束优化模型求解agv调度系统任务分配的方法,基于离线任务调度,将问题抽象为分布式约束优化问题(dcop),进行求解。本发明所述的一种分布式约束优化模型求解agv调度系统任务分配的方法,其特征在于包括以下步骤:(1)定义离散约束优化问题cop由三元组<x,d,r>组成,目标是为变量xi找到一个使总效用函数值最大化的实例x*,其中,x={x1,...,xn}是模型变量的集合;d={d1,...,dn}是变量对应的有限值域的集合;r={r1,...,rm}是一组效用函数;这样的函数为该函数范围内的变量值的每个可能组合赋予一个效用(奖励),而负数意味着成本。硬约束(限制某些特定值)是效用函数的特例,它将可行元组赋值为0,并将不可行元组赋值为负无穷;其中,ri的值为对应特定实例x的效用值;(2)定义分布式约束优化模型dcop由三元组<a,cop,ria>组成,其中,a={a1,...,ak}是一组agent的集合;cop={cop1,...copk}是一组不相交、集中式的cop的集合,每个copi被称为agentai的局部子问题,并由agentai拥有和控制;ria={r1,...rn}是一组相互影响的效用函数的集合;它们根据来自几个不同的本地子问题copi的变量定义得来的;和cop一样,硬约束是通过效用函数来模拟的,它将0赋值给可行元组,并将负无穷变为不可行元组。(3)根据dcop模型可以得出多agent之间的约束关系图,针对约束关系图,得到与之对应的伪树,针对伪树的特例基于深度优先搜索算法dfs生成dfs树;(4)基于动态规划算法dpop在dfs树上进行桶消元。dpop的主要优势在于它只需要线性数量的消息,从而在分布式设置中应用时比搜索算法引入指数级更少的网络开销。它的复杂性在于util消息的大小,它由选择的dfs排序的诱导宽度以指数方式有界。因此,dpop是解决dcop问题的最佳选择,因为这些问题具有较低的感应宽度。dpop是一种完整的算法,具有只生成线性数量的消息的重要优点。这在分布式设置中很重要,因为发送大量小消息(如搜索算法)通常需要大量的通信开销。其中,优选方案如下:步骤(2)中,三元组dcop进一步简化成五元组五元组<a,x,d,f,ria>,其中,a={a1,...,ak}是一组agent的集合;x={x1,...,xn}是模型变量的集合;d={d1,...,dn}是模型变量对应的有限值域的集合;f=﹛f1,.....,fm﹜是约束函数代价的集合;ria={r1,...rn}是一组相互影响的效用函数的集合。步骤(4)中,在dfs树上进行桶消元包括util消息传播阶段和value消息传播阶段。完整dpop算法包括3个阶段,第一阶段实质上包含步骤(3)中使用dfs算法生成dfs树这一阶段,util消息传播阶段和value消息传播阶段分别作为第二阶段和第三阶段。util消息传播阶段具体为:这是一个自下而上的过程,从最下层开始,只通过树边向上传播,在这个过程中,agent向其parents发送util消息,这些消息总结了此agent及其整个子树对其余部分的影响,其中,是指从agentxi发送到xj的util消息的一个多维矩阵。value消息传播阶段具体为:这是一个自上而下的过程,由util消息传播阶段完成时由根节点启动,每个节点根据util消息传播阶段的计算结果和从其父项收到的value消息确定其最佳值,然后,它通过value消息将此值发送给其子代,直到所有的变量都有取值时,算法结束。显然,dpop会产生线性数量的消息。它的复杂性在于util消息的大小,这是由所用dfs排序宽度的时间和空间指数决定。本发明的优点在于:(1)不需要像集中式求解方法那样把各自agent的知识和子问题集中到一个核心agent上,而是与其它agent协作,通过本地决策获取问题的全局最佳方案。这种方式有效提高了解决问题的效率,同时不要求agent对外暴露所有的个体信息,增强了隐私性。(2)在集中式求解方法中,某些agent距离核心agent很远,需要大量的信息进行交互。而在分布式求解方法中,局部求解过程往往局限在某个agent息传递的开销,减少了系统负荷。(3)集中式求解方法通常对系统结构不具备容错性,一个agent出现问题就会导致求解失败。而在分布式系统中,单个agent出现问题不会影响到整个agent系统的求解,具有很好的鲁棒性。附图说明图1为实施例2中agv1的伪树图;图2为实施例2中agv2的伪树图;图3为实施例2中agv3的伪树图;图4为实施例2中agv4的伪树图。具体实施方式以下结合实施例对本发明做进一步说明。实施例1:一种分布式约束优化模型求解agv调度系统任务分配的方法,其特征在于包括以下步骤:(1)定义离散约束优化问题cop由三元组<x,d,r>组成,目标是为变量xi找到一个使总效用函数值最大化的实例x*,其中,x={x1,...,xn}是模型变量的集合;d={d1,...,dn}是变量对应的有限值域的集合;r={r1,...,rm}是一组效用函数;这样的函数为该函数范围内的变量值的每个可能组合赋予一个效用(奖励),而负数意味着成本。硬约束(限制某些特定值)是效用函数的特例,它将可行元组赋值为0,并将不可行元组赋值为负无穷;其中,ri的值为对应特定实例x的效用值;(2)定义分布式约束优化模型dcop由三元组<a,cop,ria>组成,其中,a={a1,...,ak}是一组agent的集合;cop={cop1,...copk}是一组不相交、集中式的cop的集合,每个copi被称为agentai的局部子问题,并由agentai拥有和控制;ria={r1,...rn}是一组相互影响的效用函数的集合;它们根据来自几个不同的本地子问题copi的变量定义得来的;和cop一样,硬约束是通过效用函数来模拟的,它将0赋值给可行元组,并将负无穷变为不可行元组;进一步的,三元组dcop进一步简化成五元组五元组<a,x,d,f,ria>,其中,a={a1,...,ak}是一组agent的集合;x={x1,...,xn}是模型变量的集合;d={d1,...,dn}是模型变量对应的有限值域的集合;f=﹛f1,.....,fm﹜是约束函数代价的集合;ria={r1,...rn}是一组相互影响的效用函数的集合。(3)根据dcop模型可以得出多agent之间的约束关系图,针对约束关系图,得到与之对应的伪树,针对伪树的特例基于深度优先搜索算法dfs生成dfs树;(4)基于动态规划算法dpop在dfs树上进行桶消元,包括util消息传播阶段和value消息传播阶段。完整dpop算法包括3个阶段,第一阶段实质上包含步骤(3)中使用dfs算法生成dfs树这一阶段,util消息传播阶段和value消息传播阶段分别作为第二阶段和第三阶段。dpop的主要优势在于它只需要线性数量的消息,从而在分布式设置中应用时比搜索算法引入指数级更少的网络开销。它的复杂性在于util消息的大小,它由选择的dfs排序的诱导宽度以指数方式有界。因此,dpop是解决dcop问题的最佳选择,因为这些问题具有较低的感应宽度。dpop是一种完整的算法,具有只生成线性数量的消息的重要优点。这在分布式设置中很重要,因为发送大量小消息(如搜索算法)通常需要大量的通信开销。util消息传播阶段具体为:这是一个自下而上的过程,从最下层开始,只通过树边向上传播,在这个过程中,agent向其parents发送util消息,这些消息总结了此agent及其整个子树对其余部分的影响,其中,是指从agentxi发送到xj的util消息的一个多维矩阵。value消息传播阶段具体为:这是一个自上而下的过程,由util消息传播阶段完成时由根节点启动,每个节点根据util消息传播阶段的计算结果和从其父项收到的value消息确定其最佳值,然后,它通过value消息将此值发送给其子代,直到所有的变量都有取值时,算法结束。显然,dpop会产生线性数量的消息。它的复杂性在于util消息的大小,这是由所用dfs排序宽度的时间和空间指数决定。实施例2:本实施例的任务分配是指将已知的存取车任务分配到4辆agv,并使得总延迟惩罚成本最小。因此,任务分配的dcop模型如下:agent:4辆agv,a={a1,a2,a3,a4};变量为:第i个任务是否被分配给agvj;值域为:目标函数:总加权拖期惩罚成本最小;约束条件:约束(1)表示每个任务能且只能分配给一辆agv完成;约束(2)每辆agv的总任务时间不能超过现有电量所能完成任务的时间;约束(3)表示任务完成的拖期时间不能超过一定值,即车主的等待时间有最大值,本问题中,我们定义tmaxwaitingtime≤150s。”frodo是分布式组合优化的java开源框架,最初由zwiterland的洛桑理工学院(epfl)人工智能实验室(lia)开发。本实施例选用了frodo版本2.x,该版本由adrianpetcu在初始frodo平台基础上完全重新设计并重新实施开发。在本实验中,有任务20个,agv4辆,电量约束在本文中转化为执行任务的最大时间如表1所示:表1:电量约束agv序号1234总任务时间(s)100015009001300执行时间是是有任务的路径规划计算得来。根据这些已知数据,如表2所示,将20个任务分配给4辆agv,同时,满足模型中的约束条件。表2:任务初始数据根据以上示例数据,可以看到有4个agent,根据约束条件,进行初始化,得到的5次初始解如表3所示。表3:dcop初始解序号agv1agv2agv3agv4目标值19-8-1-6-173-19-10-14-2-184-12-11-157-20-13-16-55412525-13-15-19-318-10-17-20-611-12-19-214-16-1-4-9-8-74628832-8-16-7-112-19-20-17-5-1113-4-8-1418-3-6-9-105079149-11-3-62-8-19-20-15-1613-1-7-412-17-14-18-5-1047264515-3-16-218-17-1-10-7-412-5-8-1320-14-9-19-11-650465并根据约束得到对应的伪树为图1~图4所示:使用算法dpop计算得到结果如表4所示。表4:dcop结果agv1agv2agv3agv4目标值20-18-19-1016-17-5-6-215-14-7-11-98-4-13-3-1-12134当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1