一种时序数据的高效存储方法与流程
本发明涉及数据处理领域,具体涉及一种时序数据的高效存储方法。
背景技术:
时序数据是指时间序列数据,是一种按照时间顺序记录的数据列。一个时间序列的数据通常都是由一个数据采集点(传感器或设备)产生的,而这个采集点往往具有各种属性,比如设备序列号、厂商、型号、所处地理位置等等,属于静态信息。
在实际场景中,往往有多个同类型的设备,需要将他们产生的时序数据基于各种属性进行聚合统计、计算。比如计算北京市pm2.5的平均值,就需要将北京市各个pm2.5的监测点的值加起来求平均,而计算朝阳区pm2.5的平均值,就只需要将朝阳区的各个pm2.5监测点的值加起来求平均。
通用的时序数据处理方法,是在记录采集量的同时,将采集点的属性作为标签同时存入。但是这种设计带来两个问题:数据冗余严重,因为每条记录都带有标签;而且历史数据的标签信息修改十分困难,导致查询的灵活性不够。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种时序数据的高效存储方法,该方法能够节省存储空间,处理效率大幅提高,提高了处理速度,并且查询处理灵活。
本发明提供了一种时序数据的高效存储方法,包括如下步骤:
将每个数据采集点采集的时序数据与静态属性数据分开存储;
每个时间序列具有唯一id,基于此id存储对应的时序数据;
静态属性数据单独存放在另外一个数据库中,其中每个数据采集点在该库里有一条对应的记录。
进一步地,存储对应的时序数据通过建立独立的表,并用所述id作为表的id进行存储。
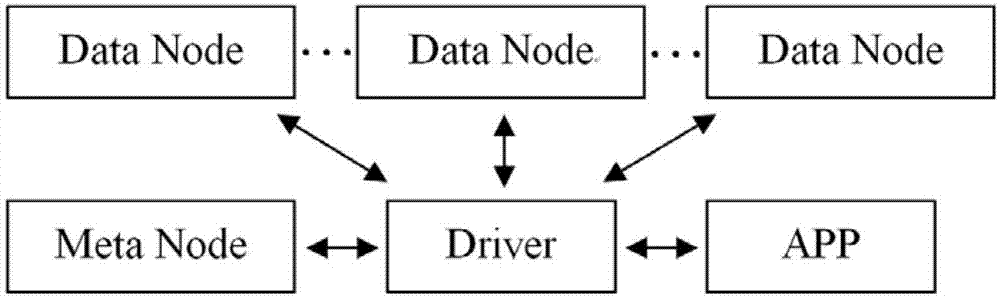
进一步地,存储对应的时序数据的节点为数据节点(datanode)。
进一步地,存储所述静态属性的表的节点为元数据节点(metanode)。
进一步地,每个数据采集点在所述元数据节点表里有一行记录。
进一步地,每行记录里包括采集点静态属性数据和该采集点对应的数据节点的信息。
进一步地,元数据节点的静态属性数据能够增加、删除和/或修改,支持各种组合条件的查询。
进一步地,存储写入数据时,根据提供的采集点的id,访问对应的元数据节点(metanode)获取对应的数据节点信息或者根据相应的算法直接推算数据节点信息,将采集的时序数据写入对应的数据节点。
进一步地,还包括聚合查询、计算步骤,具体为:
1)应用调用系统driver提供的接口api,提供查询条件;
2)driver将查询条件发往元数据节点;
3)元数据节点根据查询条件,将满足条件的采集点过滤,将采集点id以及所对应的数据节点信息列表返回给driver;
4)driver将聚合、计算请求发往一到多个数据节点,该请求里包含一到多个位于该数据节点上的采集点id;
5)数据节点将要处理的采集点的时序数据进行处理,进行第一步聚合,将结果返回给driver;
6)driver收到来自各数据节点的返回结果后,做第二步聚合操作,然后将结果返回给应用调用系统。
进一步地,driver为系统提供的一个sdk,与应用程序编译连接在一起。对于restful接口,driver是整个系统对外服务的一个接口,接收并处理http请求。
本发明的时序数据的处理方法,可以实现:
1)数据节点不保存静态属性数据(标签信息),而每个采集点的静态属性数据在元数据节点上只有一行记录,存储空间大为节省。
2)元数据节点根据查询条件,先过滤出要处理的采集点列表,这样大大节省数据节点上的数据扫描,能精准定位所需要处理的数据,大大提高处理速度。
3)各个数据节点先进行聚合,然后再由driver做最后的聚合,二级聚合的设计,大大减少数据节点与driver之间的通讯,整体处理效率大幅提高;
4)静态属性数据单独存储,可以随意增加、删除、修改,这样能支持各种灵活的查询条件。对于已经存储的历史时序数据,不用修改数据节点上的任何数据,只要修改元数据节点上的标签信息,即可做新的分析和计算。
附图说明
图1为时序数据的高效存储方法的流程原理图
具体实施方式
下面详细说明本发明的具体实施,有必要在此指出的是,以下实施只是用于本发明的进一步说明,不能理解为对本发明保护范围的限制,该领域技术熟练人员根据上述本发明内容对本发明做出的一些非本质的改进和调整,仍然属于本发明的保护范围。
本发明提供了一种时序数据的高效存储方法,下面对该方法进行具体的介绍。
(1)建立时序数据模型
将每个数据采集点采集的时序数据与采集点的各种静态的属性数据(标签信息)分开存储、处理。
存放静态属性的表可能有多个,同一类型的采集点有一个表,不同类型的采集点往往是一个不同的属性表。每一种类型的采集点的静态属性定义不一样。
每个时间序列有自己唯一的id,以此id建立独立的表来存储其时序数据,并用该id作为表的id来存储其时序数据,或其他方式。但无论其最终存储如何实现,通过该id就能找到其对应的时序数据。我们将存储该数据的节点称之为数据节点(datanode)。
每个采集点的静态属性数据(标签信息)单独存放在一张表里,每个采集点在该表里有一行记录,如果有100万个采集点,就有一百万行记录。每行记录里除静态属性数据外,还记录有该采集点对应的数据节点的信息(如ip地址)。存储该表的节点称为元数据节点(metanode)。元数据节点的静态属性数据可以增加、删除、修改,并支持各种组合条件的查询。
这样,数据节点不保存标签数据,而每个采集点的标签数据在元数据节点上只有一行记录,存储空间大为节省。
(2)写数据流程
应用程序写入数据时,driver根据其提供的采集点的id,可以访问元数据节点获取该采集点对应的数据节点信息,或者根据相应的算法,直接推算其数据节点信息(比如通过哈希算法),然后将其采集的时序数据写入该数据节点。其中,写入的时序数据不带有任何静态属性或标签信息,仅有时序数据。
(3)聚合查询、计算流程
进行聚合查询或计算时,应用需要提供查询条件,这些条件里除时间条件外,往往带有基于静态属性的过滤条件,比如地理位置、型号、颜色等等,具体流程如下:
1.应用调用系统提供的api,或发送一http请求到系统,提供其查询条件;
2.driver将其查询条件发往元数据节点;
3.元数据节点根据查询条件,将满足条件的采集点过滤出来,将采集点id以及所对应的数据节点信息列表返回给driver,这样先过滤出要处理的采集点列表可以大大节省数据节点上的数据扫描,能精准定位所需要处理的数据,大大提高处理速度;
4.driver将聚合、计算请求发往一到多个数据节点,该请求里包含一到多个位于该数据节点上的采集点id;
5.数据节点将要处理的采集点的时序数据进行处理,比如sum,avg操作,进行第一步聚合,将结果返回给driver;
6.driver收到来自个数据节点的返回结果后,做第二步聚合操作,然后将结果返回给应用(app),这样各个数据节点先进行聚合,然后再由driver做最后的聚合,大大减少数据节点与driver之间的通讯,整体处理效率大幅提高。
需要注意的是,driver可以为两种形式:
1)系统提供的一个sdk,与应用程序编译连接在一起,应用通过提供的api调用其提供的功能。访问元数据节点,数据节点以及第二阶段聚合实际上都在app所运行的计算机上进行。
2)整个系统对外服务的一个模块,应用可以通过restfulapi访问它。这种情况下,访问元数据节点、数据节点以及第二阶段聚合都是在系统内部完成。
上述方法中,静态属性数据单独存储,可以随意增加、删除、修改,这样能支持各种灵活的查询条件。对于已经存储的历史时序数据,不用修改数据节点上的任何数据,只要修改元数据节点上的静态属性数据,即可做新的分析和计算。
尽管为了说明的目的,已描述了本发明的示例性实施方式,但是本领域的技术人员将理解,不脱离所附权利要求中公开的发明的范围和精神的情况下,可以在形式和细节上进行各种修改、添加和替换等的改变,而所有这些改变都应属于本发明所附权利要求的保护范围,并且本发明要求保护的产品各个部门和方法中的各个步骤,可以以任意组合的形式组合在一起。因此,对本发明中所公开的实施方式的描述并非为了限制本发明的范围,而是用于描述本发明。相应地,本发明的范围不受以上实施方式的限制,而是由权利要求或其等同物进行限定。
- 还没有人留言评论。精彩留言会获得点赞!