一种面向动态环境的自适应在线推荐方法与流程
本发明涉及数据挖掘和机器学习领域中的在线推荐方法,特别涉及在动态环境中进行自适应在线推荐的方法,可应用于新闻推荐、广告推荐和商品推荐等场景。
背景技术
在线推荐方法能够在进行推荐的同时从与用户的交互数据中学习兴趣偏好,并且实时地调整推荐策略以适应用户的兴趣偏好。在每个推荐回合,推荐方法先观察到用户和所有候选项目的特征,然后根据推荐策略决定推荐项目,最后根据用户实际所选项目更新推荐策略。随着可观测数据量的急速增长和硬件计算能力的大幅度提高,在线推荐方法已经被大量地应用在经济、教育、游戏和多媒体等领域。如在互联网广告投放中,在线推荐方法可以在每个用户到来的时候根据用户和所有候选广告的特征决定投放的广告,并且在用户进行反馈(点击某一个广告)后更新模型以提高接下来的投放效果。在新闻推荐系统中,在线推荐方法可以在每个用户到来的时候根据用户和所有候选新闻的特征预测用户感兴趣的新闻类别从而进行推荐,并在用户进行反馈(阅读某一类别新闻)后更新模型以提高接下来的推荐效果。在股票投资中,在线推荐方法可以在每个投资周期开始的时候根据市场特征预测接下来的市场涨跌情况从而推荐优质标的,并在投资周期结束的时候根据实际涨跌情况更新模型以提高在下一周期的投资收益。
传统的在线推荐方法主要致力于在降低运算开销的同时达到静态离线推荐方法的性能。虽然有很多在线推荐方法已经在理论上被证明当推荐回合足够多的时候,平均意义上其性能与最好的离线推荐方法相当,但是对于一个动态变化的环境来说,静态离线推荐方法往往表现很差,这些在线推荐方法的理论保证也就没有了实际意义。最近也有一些可以应用于动态环境、具有理论保证的在线推荐方法被提出,但是这些方法都要求环境的变化速度和幅度可以事先确定,这些要求限制了他们的适用范围。在很多现实场景中,推荐方法面对的环境的变化情况难以提前控制和估计。如在股票投资中,当有重大事件发生的时候,股票的价格往往变化十分剧烈;在互联网广告投放和新闻推荐系统中,用户流充满了随机性和偶然性。为了能够应用于高度变化、不可事先确定的动态环境,我们需要一种自适应的在线推荐方法。
技术实现要素:
发明目的:目前的在线推荐方法只适用于有先验知识、变化缓慢的动态环境,而现实中很多场景下环境的变化是快速且无法提前预知的。针对此问题,本发明提供了一种面向动态环境的自适应在线推荐方法。
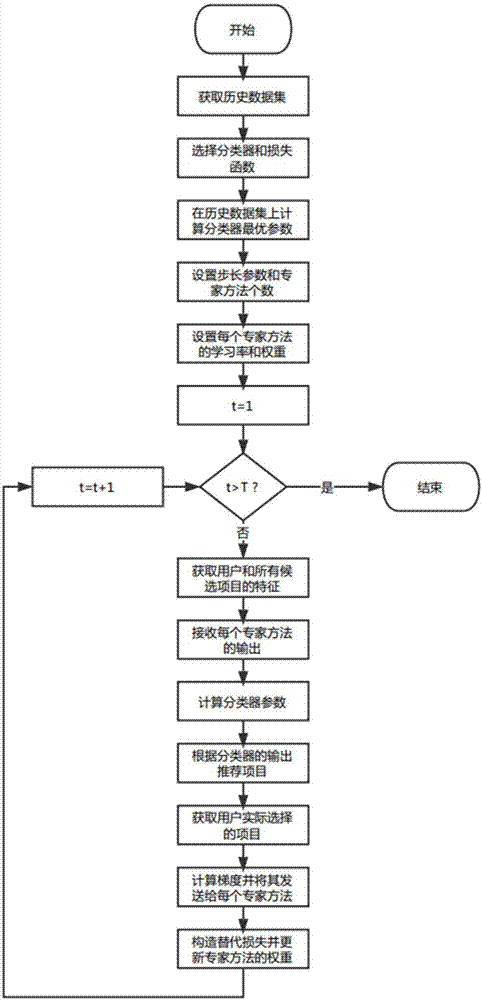
技术方案:一种面向动态环境的自适应在线推荐方法,用于新闻推荐、广告推荐和商品推荐等应用场景。具体来说,首先,获取应用场景的历史数据集。接着,选择分类器和损失函数,并计算出分类器在历史数据集上的最优参数作为初始值。然后,在每个回合根据分类器的预测决定推荐项目,并通过一个自适应方法更新分类器参数。该自适应方法包含一个元方法和多个专家方法。每个专家方法针对一类可能的动态环境,被配置不同的学习率,在每个回合用梯度下降的方式更新决策;元方法在每个回合接收所有专家方法的决策,然后按照每个专家方法在动态环境中的近期推荐表现给每个专家方法赋予不同的权值,最后基于这些权值组合专家方法的决策确定最终的推荐项目。
一种面向动态环境的自适应在线推荐方法,包括元方法和专家方法。
所述元方法的具体步骤为:
步骤100,获取推荐场景历史数据集h={(xi,yi),i=1,2,…,m},其中xi表示用户特征和所有候选项目特征拼接而成的向量,yi表示用户实际选择的项目;
步骤101,选择分类器c(x,w)和损失函数l(p,y),其中x表示用户特征和所有候选项目特征拼接而成的向量,y表示用户实际选择的项目,w表示分类器的参数,p表示分类器输出的推荐项目;
步骤102,在历史数据集上,根据所选的分类器和损失函数,在分类器参数可行域w中计算最优参数
步骤103,设置步长参数α;
步骤104,设置专家方法个数n;
步骤105,设置每个专家方法的学习率η;
步骤106,初始化每个专家方法的权重
步骤107,在每个推荐回合t=1,2,…,t执行以下步骤:
步骤108,获取用户特征和所有候选项目特征拼接而成的向量xt;
步骤109,接收每个专家方法的输出
步骤110,计算分类器参数
步骤111,根据分类器输出的推荐项目c(xt,wt)进行推荐;
步骤112,获取该回合用户实际选择的项目yt;
步骤113,计算函数ft(w)=l(c(xt,w),yt)在wt处的梯度
步骤114,将
步骤115,构造替代损失函数st(·);
步骤116,更新每个专家方法的权重
每个专家方法的具体步骤为:
步骤200,初始化
步骤201,在每个推荐回合t=1,2,…,t执行以下步骤:
步骤202,将
步骤203,接收
步骤204,更新输出
所述步骤101中可供选择的分类器包括常用的线性分类器c(x,w)=wtx、softmax分类器和神经网络分类器等;可供选择的损失函数为所有凸的可微损失函数,包括平方损失l(p,y)=(p-y)2、hinge损失l(p,y)=max(0,1-yp)和交叉熵损失l(p,y)=-∑iyilog(pi)等。
所述步骤103中步长参数α的设置方式为
所述步骤104中专家方法个数n的设置方式为
所述步骤105中每个专家方法的学习率η的设置方式为:第i(=1,2,…,n)个专家的学习率为
所述步骤115中构造的替代损失函数st(·)的具体定义为
所述步骤204中的投影操作符πw[·]的具体定义为πw[u]=argminv∈w‖u-v‖,u∈w。
有益效果:与现有技术相比,本发明能自适应地进行在线推荐,适用于变化速度和幅度无法事先预测的动态环境。
附图说明
图1为本发明的元方法工作流程图;
图2为本发明的专家方法工作流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
以电子商务网站中的商品推荐为例。
元方法的工作流程如图1所示。首先,获取网站最近一段时间所有用户的购买记录h={(xi,yi),i=1,2,…,m},其中xi表示用户和所有商品的特征拼接而成的向量,yi表示用户购买的商品。用户特征包括性别、年龄、居住地、经济收入、教育程度等,商品特征包括价格、销量、点击率、购物车转化率等。
接着,选择该场景下常用的softmax分类器和交叉熵损失l(p,y)=-∑iyilog(pi)。在购买记录数据集上,根据所选的分类器和损失函数,计算最优分类器参数
之后,确定推荐回合数t,设置步长参数
然后,设置每个专家方法的学习率:将第i(=1,2,…,n)个专家方法的学习率设置为
最后,开始每个推荐回合的在线运行。在每个推荐回合中,元方法首先获取该回合用户和所有候选商品的特征向量,拼接得到xt。接着元方法接收每个专家方法的输出
每个专家方法的工作流程如图2所示。完成初始化后,在每个推荐回合,专家方法首先将当前回合的输出发送给元方法,然后从元方法处接收梯度信息,最后使用梯度下降更新下一回合的输出。
- 还没有人留言评论。精彩留言会获得点赞!