一种语义分割驱动的图像超分辨率重构方法与流程
本发明属于数字图像处理技术领域,具体涉及一种图像超分辨率重构方法,更具体地说,涉及一种语义分割驱动的图像超分辨率重构方法。
背景技术:
语义分割是计算机视觉领域的基础任务之一,它将像素按照不同的语义分成不同的类别,在自动驾驶、图片内容理解等方面有着广泛的应用。近年来,深度卷积神经网络(deepconvolutionalneuralnetwork,dcnn)不仅在图像分类任务上有了长足的进步,而且在一些结构化输出的任务中,如语义分割,取得了突破性的进展。
2015年,long等人[1]提出fcn(fullyconvolutionalneuralnetwork),首次将dcnn应用于像素级分类的语义分割任务。为了保持感受野,fcn中用的池化层较多,导致特征图分辨率较小,分割结果粗糙。chen等人为了提高特征图分辨率同时不降低感受野,提出了deeplab系列的方法[2-4],引入了空洞卷积,优化网络的输出,在pascalvoc2012[5]的测试集上达到的86.9%的准确率。然而,在语义分割中,分割图像中的小物体仍然是很大的挑战。
图像超分辨率重构是一种有效提升图像分辨率、丰富图像内容的技术手段,可以有效增强小物体或低分辨率图像中物体的视觉效果。早期基于插值的重构方法很难模拟复杂的真实场景。随着dcnn的发展,也出现了很多基于神经网络的超分辨率重构方法。
2015年,dong等人[6]提出srcnn(super-resolutionconvolutionalneuralnetwork),将低分辨率图像作为输入,高分辨率图像作为标签,通过优化目标函数,让dcnn学习低分辨率图像和高分辨率图像之间的映射关系。2016年,kim等人[7]加深了网络架构,用插值的图像作为输入,堆叠多个卷积层,并使用残差的结构加速网络收敛,取得了更好的重构效果。
上述超分辨率重构方法皆是以提升人眼的感官效果为目的,但是肉眼所看到的图像和机器看到的图像并不相同[8]。针对具体任务而不仅仅是肉眼的感官效果增加图像的分辨率,将有利于提高具体任务的效果。提出一种语义分割驱动的超分辨率重构方法用于提高小物体或者低分辨率图像中物体的语义分割精确度具有很强的实用价值。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种语义分割驱动的图像超分辨率重构方法,让超分辨率网络能够在语义分割的驱动下更新参数,提高低分辨率图像的语义分割的准确度。
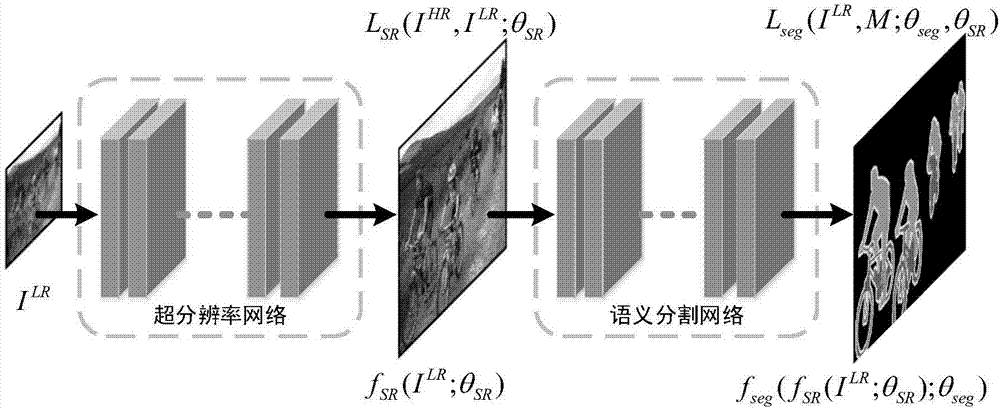
本发明提供的语义分割驱动的图像超分辨率重构方法,具体步骤如下:
(1)分别独立预训练图像超分辨率网络和语义分割网络模型
用数据集
用数据集
(2)级联独立训练的超分辨率网络和语义分割网络
超分辨率网络可以将低分辨率图像
(3)在语义分割任务的驱动下,训练超分辨率网络
在预训练模型的基础上微调网络参数,用超分辨率网络的损失函数和语义分割网络的损失函数共同指导超分辨率网络的参数的更新,使得超分辨率网络针对具体的语义分割任务进行调整;
(4)低分辨率图像经过任务驱动的网络处理后,获得准确的语义分割结果
对于低分辨率图像的语义分割任务,先将低分辨率图像输入到训练完成的语义分割驱动的超分辨率网络模型中,重构高分辨率图像,再将重构的高分辨率图像输入到语义分割网络中,获得准确的分割结果。
进一步的,步骤(1)中,训练超分辨率网络的数据集
将高分辨率图像
进一步的,步骤(1)中,两种网络独立训练的方法为:
用两种数据集训练超分辨率网络,先用常用的超分辨率任务的数据集训练网络,收敛后,再用语义分割数据集微调网络;
用标准的含有像素级标注的语义分割数据集训练语义分割网络。
常用的超分辨率任务的数据集可以为div2k[11]、91张图片[12]等;语义分割数据集可以为pascalvoc2012[5]、pascalcontext[13]或cityscapes[14]等。
进一步的,步骤(2)中,级联网络的参数由两个独立训练的模型初始化,其中语义分割模型部分的参数将被固定,用于计算重构的高分辨率图像产生的语义分割的损失,预训练的语义分割网络为超分辨率网络的参数更新提供正确的指导,因此一个较精确的语义分割网络模型在级联网络中至关重要。
进一步的,步骤(3)中,所述的损失函数为:
超分辨率网络的损失函数为:
其中,n为图像数量。
语义分割网络的损失函数为:
其中,
l为像素的类别的集合,
为了使超分辨率网络能够适应语义分割任务,而不是仅仅提供较好的视觉质量,将超分辨率网络的损失函数和语义分割网络的损失函数结合,作为最终的损失函数,所以参数更新的目标函数为:
其中,α、β用于平衡两种损失函数的贡献,α、β的选取可以根据需求调整,一般情况下,α相对β越小,重构的高分辨率图像视觉效果越差,但语义分割精确度越高;α相对β越大,则相反;建议α、β两者之比取为(0.5—1):1,优选为1:1。
虽然本发明采用两个网络级联的形式,但是最小化损失函数产生的梯度仍然可以传播到超分辨率网络中,损失函数对θsr的梯度为:
本发明的有益效果在于:本发明针对具体的语义分割任务训练超分辨率网络,使得超分辨率重构的目的不再仅仅是提供视觉质量较高、细节更丰富的高分辨率图像,而是输出对于语义分割网络内容更丰富、更有利于提取特征的高分辨率图像。本发明中,语义分割驱动的超分辨率重构方法框架简单、易于实现,可以作为一种前处理被广泛应用,提高低分辨率图像的语义分割精确度。
附图说明
图1为本发明的网络框架图。
图2为使用本发明的方法和其他方法重构的高分辨率图像的分割效果比较(4倍重构)。
具体实施方式
下面对本发明实施方案进行详细说明,但是本发明的保护范围不局限于所述实施例。
以vdsr作为超分辨率网络,deeplab-v2作为语义分割网络,分别做4倍及8倍重构,低分辨率图像由高分辨率图像下采样获得,具体步骤如下:
(1)独立训练超分辨率网络vdsr和语义分割网络deeplab-v2。用div2k和pascalvoc2012训练超分辨率网络;用pascalvoc2012训练语义分割网络;
(2)级联独立训练的超分辨率网络和语义分割网络,用步骤(1)中的参数初始化级联网络中对应部分的参数;
(3)在语义分割任务的驱动下,训练超分辨率网络,损失函数α,β的权值设为1:1或0.5:1;
(4)低分辨率图像通过任务驱动的网络处理后,获得准确的语义分割结果。
本发明重构的图像与其他方法重构的图像,经语义分割网络处理后,分割精确度比较如表1所示。可以看出,不同重构倍数下,本发明的方法重构的高分辨率图像分割的精确度远远高于其他方法。
此外,图2中给出了α:0.5,β:1时,4倍重构中,本发明方法和其他方法重构图像分割效果的直观比较,其中图2(a)为高分辨率图像及语义分割标签;图2(b)为双三次差值重构的图像及语义分割结果;图2(c)为独立训练的超分辨率网络的重构图像及语义分割结果;图2(d)为语义分割驱动的超分辨率网络的重构图像及分割结果。可以看出,本发明的方法产生的分割结果最准确。
表1不同方法重构图像的分割精确度的比较
参考文献
[1]j.long,e.shelhamerandt.darrell,“fullyconvolutionalnetworksforsemanticsegmentation,”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),pp.3431-3440,2015.(fcn)
[2]l.chen,g.papandreou,andetal.,“semanticimagesegmentationwithdeepconvolutionalnetsandfullyconnectedcrfs,”internationalconferenceonlearningrepresentations(iclr),2015.(deeplab-v1)
[3]l.chen,g.papandreou,andetal.,“deeplab:semanticimagesegmentationwithdeepconvolutionalnets,atrousconvolution,andfullyconnectedcrfs,”ieeetransactionsonpatternanalysisandmachineintelligence(tpmai),vol.40,pp.834-848,2018.(deeplab-v2)
[4]l.chen,g.papandreou,andetal.“rethinkingatrousconvolutionforsemanticimagesegmentation,”arxiv:1706.05587,2017.(deeplab-v3)
[5]m.everingham,s.eslami,andetal.,“thepascalvisualobjectclasseschallenge:aretrospective,”internationaljournalofcomputervision(ijcv),vol.111,no.1,pp.98-136,2014.(pascalvoc2012)
[6]c.dong,c.c.loy,k.he,andx.tang.“imagesuper-resolutionusingdeepconvolutionalnetworks,”ieeetransactionsonpatternanalysisandmachineintelligence(tpami),vol.38,no.2,pp.295-307,2015.(srcnn)
[7]j.kim,j.lee,andetal.“accurateimagesuper-resolutionusingverydeepconvolutionalnetworks,”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),pp.1646-1654,2016.(vdsr)
[8]c.xie,j.wang,z.zhang,y.zhou,l.xieanda.yuille,“adversarialexamplesforsemanticsegmentationandobjectdetection,”ieeeinternationalconferenceoncomputervision(iccv),pp.1378-1387,2017.
[9]b.lim,s.son,h.kim,s.nahandk.m.lee,“enhanceddeepresidualnetworksforsingleimagesuper-resolution,”ieeeconferenceoncomputervisionandpatternrecognitionworkshops(cvprw),pp.1132-1140,2017.(edsr)
[10]h.zhao,j.shi,x.qi,x.wang,andj.jia,“pyramidsceneparsingnetwork,”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),pp.2881-2890,2017.(pspnet)
[11]r.timofte,e.agustsson,l.vangool,m.-h.yang,l.zhang,etal.,“ntire2017challengeonsingleimagesuperresolution:methodsandresults,”ieeeconferenceoncomputervisionandpatternrecognitionworkshops(cvprw),2017.(div2k)
[12]j.yang,j.wright,t.s.huang,andy.ma,“imagesuper-resolutionviasparserepresentation,”ieeetransactionsonimageprocessing,pp.2861-2873,2010.(91images)
[13]r.mottaghi,x.chen,x.liu,andetal.,“theroleofcontextforobjectdetectionandsemanticsegmentationinthewild,”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2014.(pascalcontext)
[14]m.cordts,m.omran,s.ramos,andetal.,“thecityscapesdatasetforsemanticurbansceneunderstanding,”ieeeconferenceoncomputervisionandpatternrecognition(cvpr),2016.(cityscapes)。
- 还没有人留言评论。精彩留言会获得点赞!