一种基于宽度学习的智能移动机器人导航方法与流程
本发明涉及神经网络及视觉slam领域,更具体地,涉及一种基于宽度学习的智能移动机器人导航方法
背景技术:
智能移动机器人导航中slam的运用越来越广泛,slam是simultaneouslocalizationandmappong的缩写,中文译作“同时定位与地图构建”。它指搭载特定传感器的主体,在没有环境先验信息的情况下,于运动过程中建立环境的模型,同时估计自己的运动。如果这里的传感器主要为相机,那就称为“视觉slam”。
slam最早于1988年提出,最开始的时候用于描述机器人在未知环境的未知地点中同步的进行地图构建和自身定位。机器人通过传感器获取的环境数据对位置环境进行地图的建立,然后根据在运动中观测到的环境特征与地图中的特征进行匹配从而进行自身的定位以及地图的建立。
在经典视觉slam框架中,主要由传感器数据、视觉里程计、后端优化、回环检测、最终建图,这些方面主城。其中回环检测方面,现在通常是采用bow(bag-of-words)的方法,这个方法的目的是用“图像上有哪几种特征”来描述一副图像。例如,某张图片中有一个人、一辆车;而另外一张图中有两个人、一只狗。具体要做的就是确定“人”“车”“狗”等概念,对应bow的“单词”。然后用单词出现的情况进行比较,判断相似度来看看有没有达到回环。
bow方法在实际中需要人为的设定一些字典,并且在准确性上相对于机器学习来说并不高。并且回环检测说到底就是聚类的问题,而此类问题在机器学习方面已经得到了很好的解决,所以在未来,机器学习方法将有希望打败这些人工设计特征的方法,成为回环检测的主流方法,在物体识别问题方面上已经明显不如神经网络了,而回环检测又是及其相似的问题。
传统的智能移动机器人导航中的视觉slam算法主要由传感器数据、前端视觉里程计、后端优化、回环检测、建图这五大部分组成。其中回环检测的问题现在通常是使用bow这类算法来解决,但它有着准确性不高以及人为设定的缺陷,相对与机器学习而言,效果并不好。并且机器学习在解决这类聚类问题方面的成就已经得到了充分的证明,所以机器学习代替bow这类算法成为主流回环检测方法将是一大趋势。
技术实现要素:
本发明的目的为解决上述一个或多个缺陷,提出一种基于宽度学习的智能移动机器人导航方法。
为实现以上发明目的,采用的技术方案是:
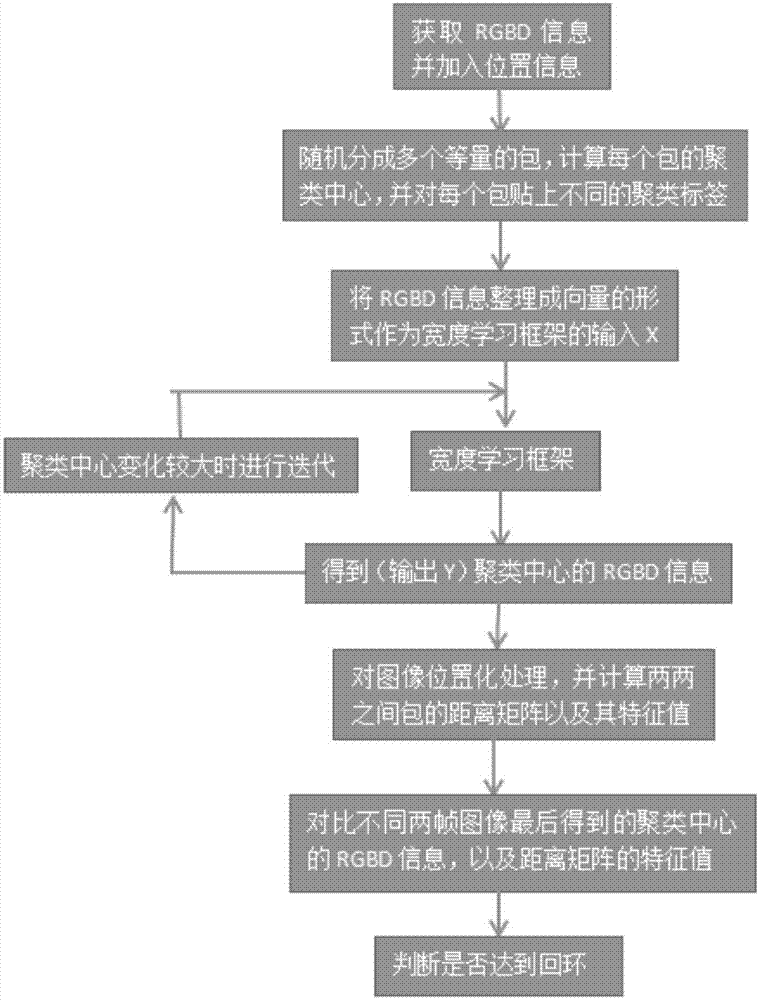
一种基于宽度学习的智能移动机器人导航方法,包括以下步骤:
s1:提出通过宽度学习框架,对图像进行聚类问题的阐述,以此来解决智能移动机器人导航中回环检测的问题;
s2:提出通过距离矩阵特征值的方法,对图像空间关系的描述,进一步对回环检测进行检验。
优选的是,步骤s1包括以下步骤:
s1.1:使用rgb-d摄像头获取rgb信息以及深度的信息,将采集到的数据集的样本分成多个同等份的小数据集,把这些小数据集称为包;此分组为随机平分,所述包的数量是固定的且根据数据集的总数决定;
s1.2:分组完成后,对每个包贴上相应的聚类标签,以作为每个聚类的区分和识别;
s1.3:将数据信息整理成向量的形式,把此向量看作x,并作为输入放入宽度学习的输入层;同时在数据进入宽度学习系统前,对每个包的数据分别计算均值,作为相应的聚类分组的聚类中心;
s1.4:在步骤s1.3中得到的向量x作为输入,进入宽度学习系统,首先通过映射获得n组特征节点,其中每组特征节点含有p个节点,所述n组映射每组映射的激励函数不同,再利用稀疏自编码器训练更新特征映射过程的权值和阈值;此步的映射方程为
r=φi(x*wri+βri)
其中wri为输入到特征节点之间的权重,βri为给定的阈值;
s1.5:通过步骤s1.4中得到的特征节点,映射出m个增量节点h,映射方程为
其中whi为特征节点到增量节点之间的权重,βhi为给定的阈值;
s1.6:通过得到的特征节点以及增量节点,使用超限学习(elm)的方法获得输出y,其中特征节点以及增量节点这层到输出层的权值定义为wall;
s1.7:在得到宽度学习的输出y之后,对输出值进行处理,计算输出值数据离各个聚类中心的距离d,最后将此输出y划分到距离d最小的相应聚类中心里,以此重新得到了多个包;
s1.8:处理完所有输出值后,对各个包的数据计算均值,重新得到每个聚类组类的新聚类中心;
s1.9:将宽度学习得到的输出作为输入放入宽度学习系统里,然后重复步骤s1.4至步骤s1.8的操作进行迭代处理,当聚类中心不再变化或显现出小变化时,停止迭代的操作,得到最终的多个包以及每个包对应的聚类中心;
s1.10:将第a帧图像聚类与第b帧图像聚类的每个中心进行对比,规定a、b在全部帧中随机取,且a+1<b,当最终聚类中心的对比在误差范围之内,并达到了一定的数量时,便看作是达到了回环的效果。
优选的是,步骤s2包括以下步骤:
s2.1:在中通过rgbd相机得到数据的同时,对此时得到的像素平面进行位置化处理,给定每个像素(x,y)位置信息,x轴为横向,y轴为纵向;
s2.2:对步骤s1.9中得到的多个包分别进行位置化的均值处理,得到位置中心ci(i=1,...,t)(位置心中的数量即跟包的数量一致,标定为t);
s2.3:计算t个中心两两之间的距离dij,为
式中θij表示位置ci、cj相连线段与水平线的夹角,此夹角恒为锐角;将两两中心的距离dij组成距离矩阵mij,然后求mij的t个特征值λi(i=1,...,t),并对特征值进行归一化处理,其中所述归一化处理包括将各个分量除以t个特征值的均方差或除以t个特征值所组成的向量的范数。
与现有技术相比,本发明的有益效果是:
本发明与现有技术相比,使用宽度学习进行离线的训练,使得整个回环检测的稳定性以及准确性得到提高,以此来提高智能移动机器人导航的高效性和准确性。并且因为宽度学习的特性,相比于其他的机器学习来说所需要训练的时间更加少,所以整个系统也不会很费时;另外,在回环检测中加入位置化特性,通过计算距离矩阵以及其特征值,用来对图像空间关系进行描述,从而进一步对回环检测进行检验。本发明中的这两大特征使得整个系统的准确性得到显著的提高。
附图说明
图1为本发明的流程图;
图2为本发明的宽度学习网络框架图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
一种基于宽度学习的智能移动机器人导航方法,请参考图1,步骤流程如下:
(1)使用rgb-d摄像头获取rgb信息以及深度的信息,将采集到的数据集的样本分成多个同等份的小数据集,把这些小数据集称为包,此分组是随机平分的,包的数量取9;
(2)分组完成后,对每个包贴上相应的聚类标签。以作为每个聚类的区分和识别。并将数据信息整理成向量的形式,把此向量看作x,并作为输入放入宽度学习的输入层。同时,在数据进入宽度学习系统时,对每个包的数据分别计算均值,作为相应的聚类分组的聚类中心;
(3--5)是宽度学习系统的框架。
(3)在s1.3中得到的向量x看作输入,进入宽度学习系统,首先通过映射获得n组特征节点,其中每组特征节点含有p个节点(这里的n组映射每组映射的激励函数可以不同),再利用稀疏自编码器训练更新特征映射过程的权值和阈值。此步的映射方程是r=φi(x*wri+βri),其中wri是输入到特征节点之间的权重,βri是给定的阈值。
(4)通过s1.4中得到的特征节点,映射出m个增量节点h,这个增量节点与特征节点在同一层网络中如图2所示。此步的映射方程是
(5)通过得到的特征节点以及增量节点,使用超限学习(elm)的方法获得输出y,其中特征节点以及增量节点这层到输出层的权值定义为wall。
(6)在得到宽度学习的输出y之后,对输出值进行处理,计算输出值数据离各个聚类中心的距离d,最后将此输出y划分到距离d最小的相应聚类中心里,以此重新得到了多个包。
(7)处理完所有输出值后,对各个包的数据计算均值,重新得到每个聚类组类的新聚类中心。
(8)将宽度学习得到的输出作为输入放入宽度学习系统里,然后重复(3)至(7)的操作进行迭代处理,当聚类中心不再变化或显现出小变化时,停止迭代的操作,得到最终的多个包以及每个包对应的聚类中心。
另一方面,对图像位置化处理,并计算两两之间包的距离矩阵以及其特征值:
(9)在s1的s1.1中通过rgbd相机得到数据的同时,对此时得到的像素平面进行位置化处理,给定每个像素(x,y)位置信息,x轴为横向,y轴为纵向。
(10)对s1的s1.9中得到的多个包分别进行位置化的均值处理,得到位置中心(i=1,...,9)(位置心中的数量即跟包的数量一致,标定为9)。
(11)计算9个中心两两之间的距离
最终,判断图像是否达到回环:
(12)将第a帧图像聚类与第b帧图像聚类的每个中心进行对比(规定a、b在全部帧中随机取,且a+1<b),并且将这两帧图像得到的特征值分别进行对比。当最终聚类中心的对比在误差范围之内,并达到了一定的数量,而且两帧图像特征值之间的差值也在误差范围之内时,便看作是达到了回环的效果。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!