一种基于深度密度的RGBD图像语义分割优化方法与流程
本发明涉及计算机图像处理领域,特别涉及一种基于深度密度的rgbd图像语义分割优化方法。
背景技术:
rgbd是一种图像类型的,其实质是rgb+depth,即在采集图像的过程中,会同时获取目标的深度信息(从目标表面到镜头的直线距离),本专利中的rgbd图像时利用tof(timeoffly)技术来获取的,这类技术的特点是成像快,精度高,可以做到实时采集两类图像。缺点是深度图像的分辨率也比较低。
深度卷积网络是深度学习领域的一个关键技术点,其基础是多层神经网络,区别是将原来神经网络的全连接转变为卷积操作,这样会提高网络前向和反向传播的效率,这样就可以在原有计算资源的基础上,通过增加网络的深度来实现更多数据特征的提取。
全卷积网络是深度卷积网络的一种,一般是在分类网络的基础上进行改变行成的,其特点是整个网络中没有全连接层,从输入到输出都是卷积操作,这样的网络与原有的分类网络相比,具有更快的处理速度,而且参数更少。其用途一般是用于像素级的语义分割,其理论实质是对图像中所有的像素点进行分类。
上采样操作是逆向卷积操作的一种说法,其实质是将特征图进行扩大尺寸操作,以获得目标尺寸的图像,主要的上采样操作包括全尺寸反卷积操作和双线性差值法。其中全尺寸反卷积操作可以获得任意尺寸大小的目标图像,而双线性插值法主要用于产生2倍于原图像尺寸的目标图像。
目前,利用全卷积网络进行图像分割时,由特征图(热图heatmap)恢复为原始图像尺寸,分割结果过于粗糙,边界不清晰。这主要是由于上采样过程中,很多细节特征丢失而造成像素分类不准,因此需要对上采样过程和采样结果进行优化。
技术实现要素:
本发明提供一种基于深度密度的rgbd图像语义分割优化方法,可以利用深度图像来计算图片中每个位置的深度密度,利用深度密度来判断相邻区域是否属于同一物体,并以此进行目标物体的边界判定,将具有相近深度密度的像素归为同一类型,从而提高语义分割效果。
一种基于深度密度的rgbd图像语义分割优化方法,包括如下步骤:
计算rgbd图像中以(x,y)像素点为中心的n×n范围内像素点的平均深度
μx,y:
计算rgbd图像中以(x,y)点为中心的,n×n范围内与(x,y)点的像素的深度方差σx,y:
计算rgbd图像中以(x,y)点为中心的,n×n范围内与平均深度μx,y的深度方差
将图像加入图像填充区域(padding),即在原图像的基础上,外沿四周加上一圈像素边框,且padding的深度值为0,使图像尺寸变为(h+(n-1)/2,w+(n-1)/2),得到待分割图像;
对待分割图像进行处理:
其中,gaus(x,μ,σ)为高斯分布函数,denm(x,y)为将平均深度μx,y作为概率密度函数的位置参数,
设立深度密度的范围,判定在同一密度范围内的像素点是否属于同一物体。
更优地,在进行上述计算步骤前还包括:
对rgbd图像构建用于分类的深度卷积网络,得到特征图;
基于深度卷积网络建立全卷积网络:以深度卷积网络为基础,将深度卷积网络的全连接层转换为卷积层,以保留图像的二维信息;对深度卷积网络的结果进行反卷积操作,使图像恢复到原始图像的尺寸;逐个对像素分类以获取每个像素的类别,得到热图;
对热图进行反卷积操作,使热图恢复到原始图像尺寸大小。
本发明提供一种基于深度密度的rgbd图像语义分割优化方法,利用深度图像来计算图片中每个位置的深度密度,利用深度密度来判断相邻区域是否属于同一物体(根据深度密度来将图像中的像素进行聚类),并以此进行目标物体的边界判定,将具有相近深度密度的像素归为同一类型,最终给出分割结果,使语义分割效果得到有效提升。
附图说明
图1为深度卷积网络的示意图;
图2为全卷积网络的示意图;
图3为反卷积的操作示意图;
图4为full模式下反卷积操作的操作示意图;
图5为基于反卷积操作进行热图恢复的操作示意图;
图6为rgbd图像;
图7为rgbd图像的像素深度分布图;
图8为深度密度核操作示意图;
图9为真值图;
图10为全卷积网络分割结果示意图;
图11为基于深度密度的rgbd图像语义分割优化后的示意图。
具体实施方式
下面结合附图,对本发明的一个具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
本发明实施例提供的一种基于深度密度的rgbd图像语义分割优化方法,包括如下步骤:
1、构建用于分类的深度卷积网络模型:
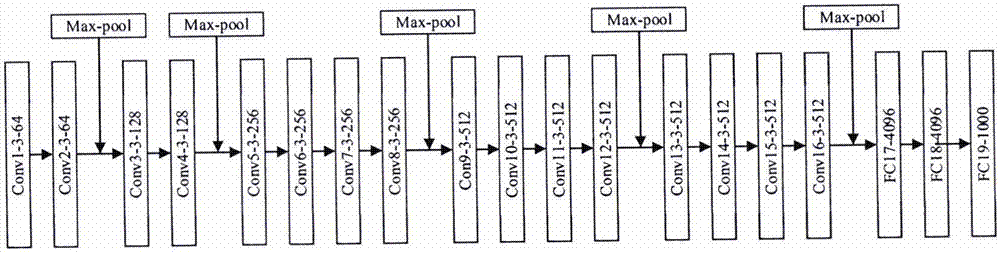
如图1所示,对于第一层“conv1-3-64”,其中“conv”表示卷积层,“3”表示卷积核尺寸为3*3,“64”表示卷积后的输出通道数,也可以理解为卷积核的个数,构建分类网络主要用于建立后面的全卷积网络。
2.基于分类网络建立全卷积网络
如图2所示,这里要说明的是,分类网络与全卷积网络主要区别在于后面全连接网络,如图1中后三层“fc17”,“fc18”和“fc19”。全卷积网络以分类卷积神经网络为基础,将分类网络后面的全连接层转换为卷积层,以保留输入图像的二维信息;对分类网络的结果(特征图或热图)进行反卷积操作,使特征图恢复到原始图像的尺寸,最后通过逐个像素分类获取每个像素的类别,从而实现目标对象的语义分割。全卷积网络的结构如图2所示。
3.利用全卷积网络的结果(热图),进行反卷积操作,将热图恢复到原始图像尺寸大小
如图3至图4所示,分类网络中的卷积层主要是获取高维特征,每层池化操作可以使图片缩小一半,全连接与传统神经网络相似作为权值训练,最后通过softmax输出概率最高类别。经过改造后,vgg-19中的全连接层全部换成卷积层,其中全连接层分别转换为1×1×4096(长、宽、通道)、1×1×*4096和1×1×class。最终可以获得与输入图像对应的热图。而热图的尺寸在经历过5次池化过程后,变成原图像大小的1/32。为了实现端到端的语义分割,因此需要将热图恢复到原始图像的尺寸,因此需要采用上采样操作。上采样(upsample)是池化操作的逆过程,上采样后数据数量会增多。在计算机视觉领域,常用的上采样方法有3种,一个是双线性插值(bilinear),这种方法特点是不需要进行学习,运行速度快,操作简单;一个是反卷积(deconvolution),即利用转置卷积核的方法,对卷积核进行180度翻转(结果都是唯一的),注意不是转置操作;一个是反池化,在池化过程中记录坐标位置,然后根据之前坐标将元素填写进去,其他位置补0。本发明选择“反卷积+双线性插值”法实现上采样过程,如图3、图4所示,设原特征图的尺寸为n×n,那么采用差值法,则会将原始特征图的尺寸变为2n+1,然后设置2×2的卷积,对新特征图进行valid方式的卷积操作,最终会获得新的特征图,尺寸为2n。
4.利用反卷积操作恢复热图
如图5所示,因为分类网络中有5次池化操作,因此最后输出的特征图大小是原图的1/32,因此上采样操作针对池化后的结果进行反卷积,可以分别获得32倍、16倍、8倍、4倍和2倍的结果(与输入图像尺寸相同)如图5所示。这里分别称这些结果为fcn-32s,fcn-16s,fcn-8s,fcn-4s,fcn-2s。
假设输入图像的尺寸为32×32,而且vgg-19网络中卷积操作不改变该阶段输入图像或特征图的大小,则pool-1层的输出尺寸为16×16,pool-2层的输出尺寸为8×8,pool-3层的输出尺寸为4×4,pool-4层的输出尺寸为2×2,pool-5的输出尺寸为1×1。由于全卷积网络将vgg-19最后的三个全连接层转变为卷积层,f-1-4096×2层和f-1-class×1层不会改变特征图的二维空间属性,输出的特征图尺寸仍与pool-5的输出相等,为原始图像的1/32而通道数与分类数相等。
(1)对于fcn-32s,f-1-class×1层输出的特征图大小为1×1,直接将特征图用32倍的反卷积操作还原成32×32的尺寸,对于本例子即用32×32的卷积核对特征图进行处理,反卷积操作后的输出的特征图为32×32。如图5所示,在f-1-class×1层后加了一个full-32-1层进行反卷积处理。
(2)对于fcn-16s,本文将f-1-class×1层输出的特征图进行1次插值2倍的卷积操作,即在f-1-class×1层后增加一个bc-2-1层,将f-1-class×1输出的特征图增大到2×2倍,然后与pool-4的结果相加,最后将相加的结果进行16倍的full-全卷积操作,可以获得与原图像相同尺寸的图像。如图5所示,在f-1-class×1层后加了一个bc-2-1层,在加操作后增加一个full-29-1层,进行反卷积处理。
(3)对于fcn-8s,本文将f-1-class×1层输出的特征图进行2次插值2倍的卷积操作,使原特征图增大到4×4倍,然后对pool-4进行1次插值2倍的上采样,最后将2个结果与pool-3的结果相加,最终对相加的结果进行8倍的full模式全卷积上采样,可以获得一个与原图相同尺寸的图像。如图5所示,在f-1-class×1层后增加了3个bc-2-1卷积层,和1个full-29-1卷积层。
从结构上看,仍旧可以针对pool-1和pool-2的结果进行反卷积处理,分别得到fcn-4s和fcn-2s的端到端输出,但是结果显示在8倍上采样之后,优化效果已经不明显。
5.基于深度密度的分割优化
如图6至图8所示,利用全卷积网络对图像进行语义分割的主要步骤是对特征图进行上采样,将特征图中的热点像素还原到原图像的尺寸,但是这种还原方式会存在较大的像素分类误差。这其中包括像素的错误分类以及像素丢失。因此,利用原rgb图像附加的深度信息对fcn-8s的结果进行优化。
在实施例中,用于全卷积网络训练的rgb图像有与其对应相同尺寸的深度图像,而且rgb图像与深度图像在内容上是近似映射的(存在噪点和误差)。从深度图像上可以看出,同一物体的细节信息可以通过连续变化的深度值表示出来,不同物体间的边界信息会根据深度值的突变表示出来。特别是对于一个特定目标来说,深度值一般是连续的、或者是临近区间内的。这里我们随机给出一幅深度图像的4列像素深度的分布,如图7所示,其中横坐标表示像素的空间位置,纵坐标表示像素的深度值,可以发现深度值接近的点在空间上点都是相对集中的。(可以随机取图像中的4列信息)。
从图8中可以观察到,深度图像中具有相近灰度值(深度值)的像素点在空间上也比较相近,因此本文利用空间这一特点,提出了深度密度概念(depthdensity)。设图像i的尺寸为h×w,其中h为图像i的行数,w为图像的列数。设den(x,y)为图像上(x,y)点的深度密度;设dx,y为图像上(x,y)点的深度值。针对图像上每个像素点,都需要进行深度密度计算,而计算过程由一个密度核操作完成,设核的尺寸为n×n,本文分别取n=3和n=5来计算像素点的深度密度值,如图x所示,1点的坐标为(2,2),n=3;2点的坐标为(5,4),n=5。
设μx,y为图中以(x,y)点为中心的n×n范围内像素点的平均深度,即:
设σx,y为图中以(x,y)点为中心的n×n范围内,与中心点像素求得的深度方差,即:
设
为了求得图像中每个像素点的深度密度,这里将原图像加入了padding,并且padding的深度值为0(体现在灰度图像上即灰度值为0),使原图像变为(h+(n-1)/2,w+(n-1)/2)。
最后,基于高斯分布函数x~n(μ,σ2)对原深度图像进行处理,用gaus(x,μ,σ)表示高斯分布函数,具体如下:
这里,使用了2种计算深度密度方案:第一种是将平均深度μx,y作为概率密度函数的位置参数,
从公式1中可以得,当像素点(x,y)与n×n范围内像素点的均值相近时,denm(x,y)较高。对于公式2,当像素点(x,y)与中心点的像素值相近是,denc(x,y)较高。
设立深度密度的范围,判定在同一密度范围内的像素点属于同一物体,这样就可以根据深度密度对原始分割结果进行优化,提高分割精度。
如图9至图11所示,利用深度图像获取每个像素点的深度密度,然后基于深度密度优化图像分割的方法,提高了图像分割的准确率,其中全卷积分割的平均精度在65%左右,改进后平均精度能提高到85%左右。
以上公开的仅为本发明的几个具体实施例,但是,本发明实施例并非局限于此,任何本领域的技术人员能思之的变化都应落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!